
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Paper
• 2508.06471 • Published
• 206
Made using LLM Compressor model_free_ptq:
from llmcompressor import model_free_ptq
MODEL_ID = "zai-org/GLM-4.6"
SAVE_DIR = MODEL_ID.rstrip("/").split("/")[-1] + "-FP8-BLOCK"
# Apply FP8-Block to the model
# Once quantized, the model is saved
# using compressed-tensors to the SAVE_DIR.
model_free_ptq(
model_stub=MODEL_ID,
save_directory=SAVE_DIR,
scheme="FP8_BLOCK",
ignore=[
"re:.*gate$",
"lm_head",
"model.embed_tokens",
],
max_workers=15,
device="cuda:0",
)
GSM8k running with vLLM TP=4 on GB300
vllm serve GLM-4.6-FP8-BLOCK -tp=4
python tests/evals/gsm8k/gsm8k_eval.py
Running GSM8K evaluation: 1319 questions, 5-shot
Evaluating: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1319/1319 [00:52<00:00, 25.15it/s]
Results:
Accuracy: 0.929
Invalid responses: 0.001
Total latency: 52.449 s
Questions per second: 25.148
Total output tokens: 131828
Output tokens per second: 2513.428
👋 Join our Discord community.
📖 Check out the GLM-4.6 technical blog, technical report(GLM-4.5), and Zhipu AI technical documentation.
📍 Use GLM-4.6 API services on Z.ai API Platform.
👉 One click to GLM-4.6.
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
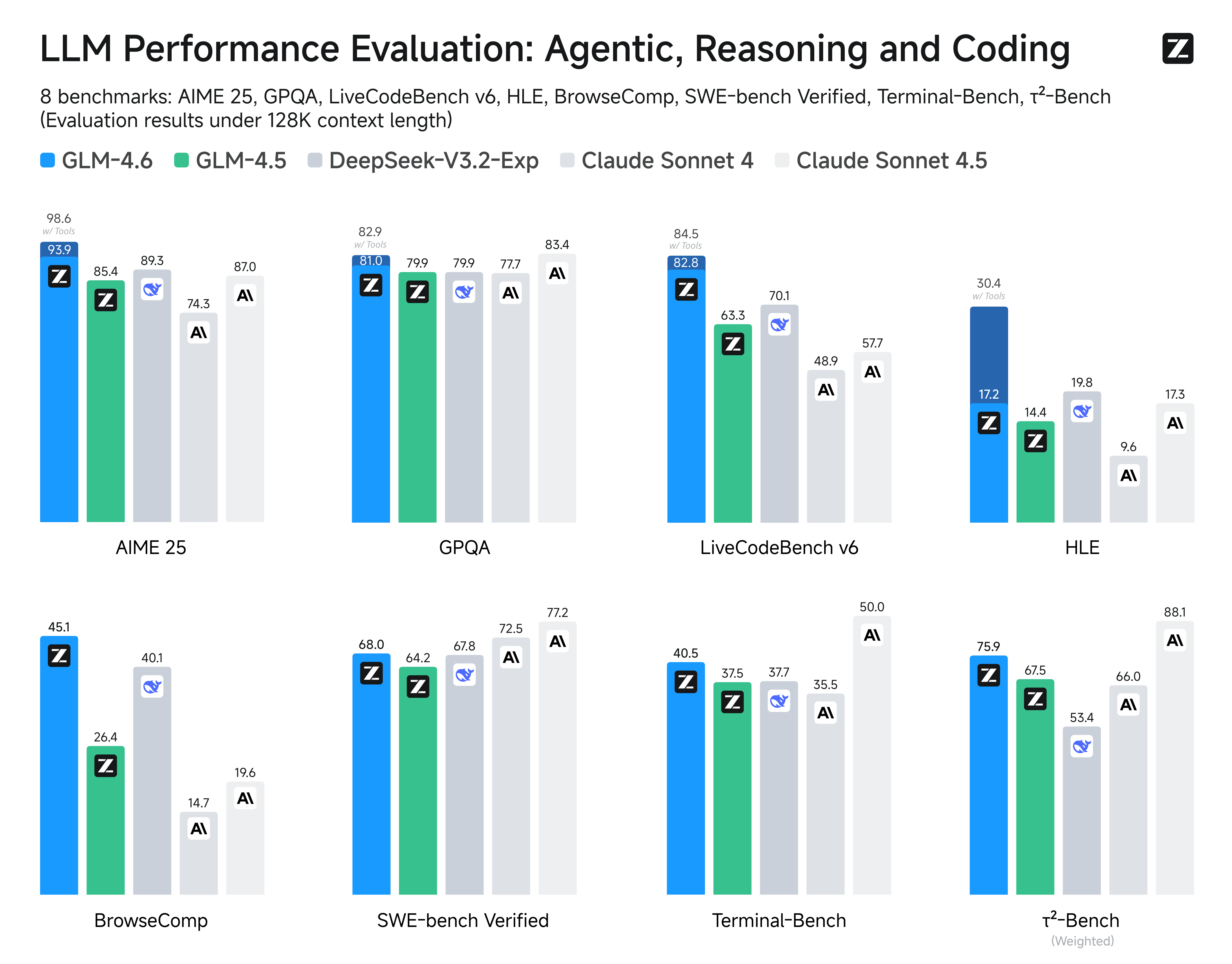
Both GLM-4.5 and GLM-4.6 use the same inference method.
you can check our github for more detail.
For general evaluations, we recommend using a sampling temperature of 1.0.
For code-related evaluation tasks (such as LCB), it is further recommended to set:
top_p = 0.95top_k = 40Base model
zai-org/GLM-4.6