
onevision-encoder
Collection
2 items
•
Updated
•
1
Transformers Version Compatibility:
- ✅
transformers==4.57.3(Recommended): Works withAutoModel.from_pretrained()- ⚠️
transformers>=5.0.0: Not currently supported. We are actively working on a fix.
Note on Inputs: While the model is pre-trained with the configurations below, it supports dynamic native resolution and arbitrary frame counts during inference:
- Pre-training Image Base: 448×448
- Pre-training Video Base: 224×224 (256 tokens/frame)
- Inference: Supports variable resolutions and frame lengths.
from transformers import AutoModel, AutoImageProcessor
from PIL import Image
import torch
# Load model and preprocessor
model = AutoModel.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True,
attn_implementation="flash_attention_2"
).to("cuda").eval()
preprocessor = AutoImageProcessor.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True
)
# Image inference: [B, C, H, W]
image = Image.open("path/to/your/image.jpg") # Replace with your image path
pixel_values = preprocessor(images=image, return_tensors="pt")["pixel_values"].to("cuda")
with torch.no_grad():
outputs = model(pixel_values)
# outputs.last_hidden_state: [B, num_patches, hidden_size]
# outputs.pooler_output: [B, hidden_size]
# Video inference: [B, C, T, H, W] with patch_positions
num_frames, target_frames = 16, 64
patch_size = 14
# Load video frames and preprocess each frame (replace with your video frame paths)
frames = [Image.open(f"path/to/frame_{i}.jpg") for i in range(num_frames)]
video_pixel_values = preprocessor(images=frames, return_tensors="pt")["pixel_values"]
# Reshape from [T, C, H, W] to [B, C, T, H, W]
video = video_pixel_values.unsqueeze(0).permute(0, 2, 1, 3, 4).to("cuda")
# Build patch_positions for temporal sampling: [B, num_frames * frame_tokens, 3]
frame_pos = torch.linspace(0, target_frames - 1, num_frames).long().cuda() # [T]
grid_h, grid_w = video.shape[-2] // patch_size, video.shape[-1] // patch_size # patch grid
frame_tokens = grid_h * grid_w
t_positions = frame_pos[:, None].repeat(1, frame_tokens).reshape(-1) # [T * frame_tokens]
h_positions = torch.arange(grid_h, device="cuda").repeat_interleave(grid_w)
h_positions = h_positions.repeat(num_frames) # [T * frame_tokens]
w_positions = torch.arange(grid_w, device="cuda").repeat(grid_h)
w_positions = w_positions.repeat(num_frames) # [T * frame_tokens]
patch_positions = torch.stack([t_positions, h_positions, w_positions], dim=-1).unsqueeze(0)
# patch_positions example (256 tokens per frame, 16x16 patch grid):
# Each row is [t, h, w].
# First 4 patches of frame 0 (t=0):
# patch_positions[0, 0:4, :] -> [[0, 0, 0], [0, 0, 1], [0, 0, 2], [0, 0, 3]]
# First 4 patches of frame 1 (t=4):
# patch_positions[0, 256:260, :] -> [[4, 0, 0], [4, 0, 1], [4, 0, 2], [4, 0, 3]]
with torch.no_grad():
outputs = model(video, patch_positions=patch_positions)
git clone [https://github.com/EvolvingLMMs-Lab/OneVision-Encoder.git](https://github.com/EvolvingLMMs-Lab/OneVision-Encoder.git)
cd OneVision-Encoder
pip install -e .
from onevision_encoder import OneVisionEncoderModel, OneVisionEncoderConfig
from transformers import AutoImageProcessor
model = OneVisionEncoderModel.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True,
attn_implementation="flash_attention_2"
).to("cuda").eval()
preprocessor = AutoImageProcessor.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large-lang",
trust_remote_code=True
)
Training on a mixed dataset of 740K samples from LLaVA-OneVision and 800K samples from LLaVA-Video SFT. The training pipeline proceeds directly to Stage 2 fine-tuning.
We adopt a streamlined native-resolution strategy inspired by LLaVA-OneVision: when the input frame resolution matches the model's native input size, it is fed directly—without tiling or cropping—to evaluate the ViT's capability to handle true native resolution and arbitrary frame sequences.
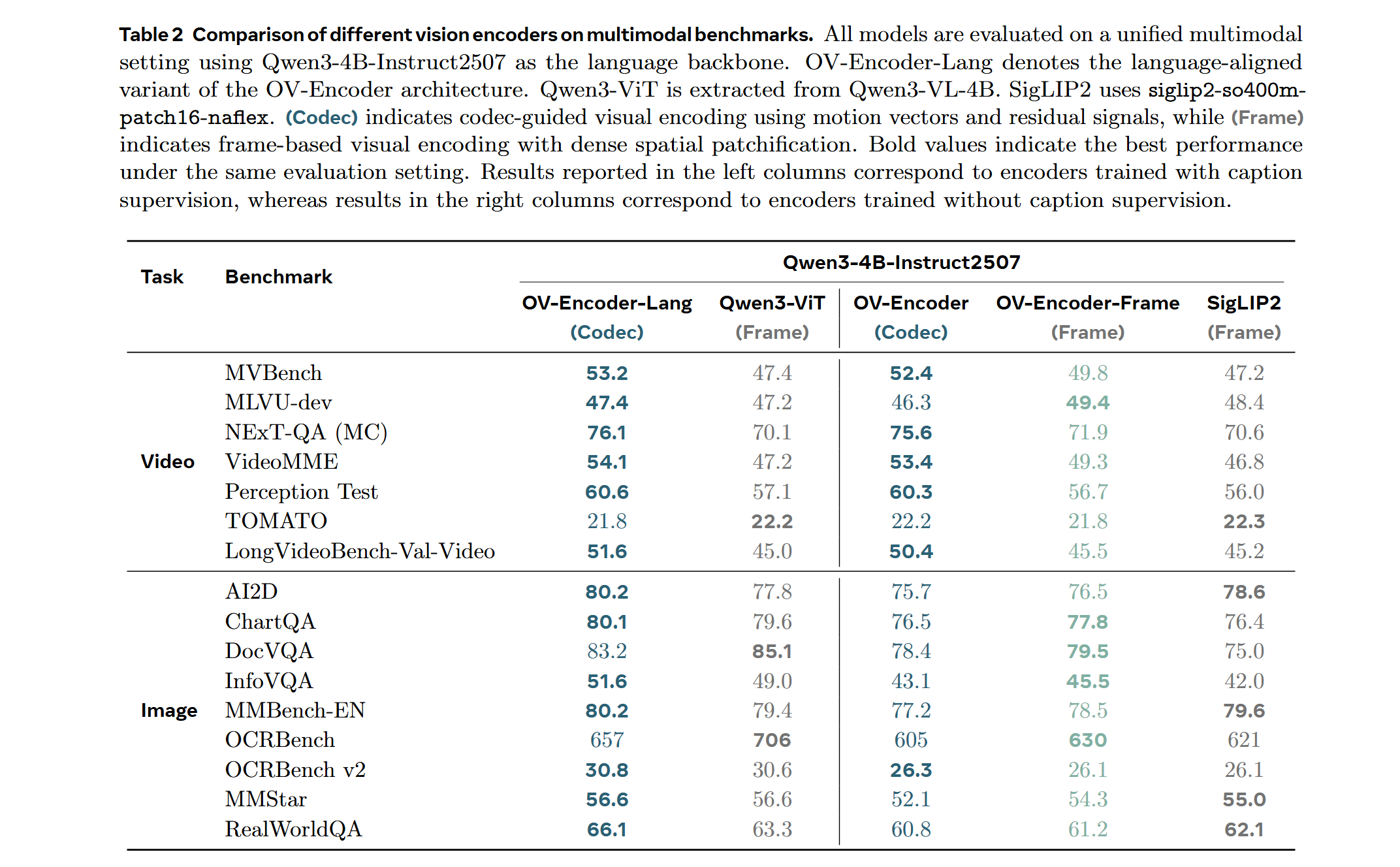
| Property | Value |
|---|---|
| Model Type | LLM-Aligned Vision Transformer (ViT) |
| Architecture | HEVC-Style / Codec-Like Vision Transformer |
| Input Paradigm | Codec-Style (Sparse Patch / Dense Frame) |
| Resolution Strategy | True Native Resolution (Dynamic, No Tiling) |
| Temporal Context | Arbitrary Frame Count (Variable Length Support) |
| Hidden Size | 1024 |
| Intermediate Size | 4096 |
| Number of Layers | 24 |
| Number of Attention Heads | 16 |
| Patch Size | 14 |
| Positional Encoding | 3D RoPE (4:6:6 split for T:H:W) |
| Normalization | Layer Normalization |
| Activation Function | GELU |
| License | Apache 2.0 |