
[Trimming] SmolLM3
Collection
Collection of trimmed Hugging Face's SmolLM3 models. The models are sorted alphabetically. • 16 items • Updated
This model is a 6.36% smaller version of HuggingFaceTB/SmolLM3-3B optimized for Italian language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 32,768 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
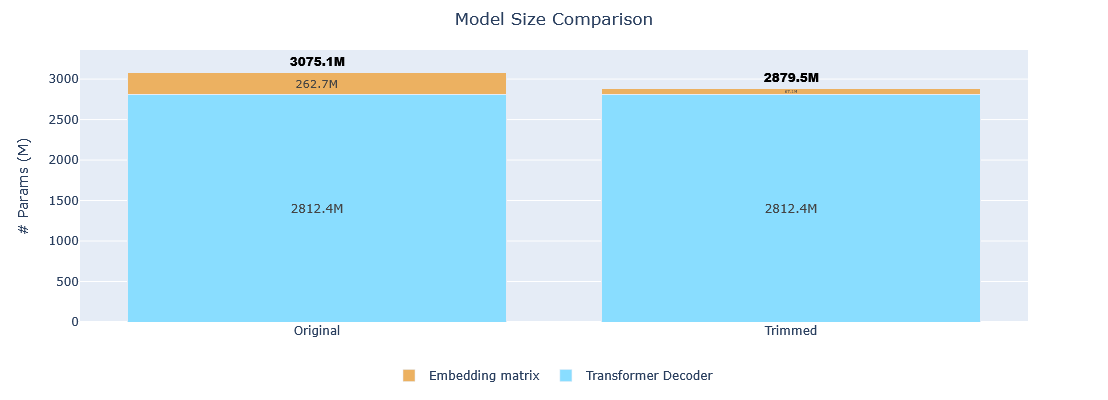
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 128,256 tokens | 32,768 tokens | 74.45% |
| Model size | 3,075,098,624 params | 2,879,539,200 params | 6.36% |
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "alphaedge-ai/SmolLM3-3B-ita-32768"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)
# prepare the model input
prompt = "Your prompt in Italian."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate the output
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
To enable/disable thinking mode, use the /think or /no_think flag in the system prompt:
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": prompt}
]
@misc{bakouch2025smollm3,
title={SmolLM3: smol, multilingual, long-context reasoner},
author={akouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane
and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward
and Roucher, Aymeric and others},
year={2025},
howpublished={https://huggingface.co/blog/smollm3}
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
HuggingFaceTB/SmolLM3-3B-Base