
Commit ·
d57daa8
0
Parent(s):
This view is limited to 50 files because it contains too many changes. See raw diff
- .github/workflows/lint.yml +23 -0
- .gitignore +170 -0
- .pre-commit-config.yaml +30 -0
- LICENSE +203 -0
- README.md +242 -0
- assets/LOGO.svg +24 -0
- assets/apple.jpg +0 -0
- docs/en/.readthedocs.yaml +17 -0
- docs/en/ConfigSystem.md +57 -0
- docs/en/Contributors.md +21 -0
- docs/en/Development.md +146 -0
- docs/en/Makefile +20 -0
- docs/en/Quickstart.md +148 -0
- docs/en/_static/css/readthedocs.css +63 -0
- docs/en/_static/image/logo.svg +24 -0
- docs/en/_static/image/logo_icon.svg +31 -0
- docs/en/_static/js/custom.js +10 -0
- docs/en/_templates/404.html +18 -0
- docs/en/_templates/autosummary/class.rst +13 -0
- docs/en/_templates/callable.rst +14 -0
- docs/en/conf.py +234 -0
- docs/en/docutils.conf +2 -0
- docs/en/index.rst +41 -0
- docs/ja/README_ja.md +177 -0
- docs/zh-CN/.readthedocs.yaml +17 -0
- docs/zh-CN/ConfigSystem.md +59 -0
- docs/zh-CN/Development.md +140 -0
- docs/zh-CN/Makefile +20 -0
- docs/zh-CN/Quickstart.md +147 -0
- docs/zh-CN/README_zh-CN.md +215 -0
- docs/zh-CN/_static/css/readthedocs.css +63 -0
- docs/zh-CN/_static/image/logo.svg +24 -0
- docs/zh-CN/_static/image/logo_icon.svg +31 -0
- docs/zh-CN/_static/js/custom.js +10 -0
- docs/zh-CN/_templates/404.html +18 -0
- docs/zh-CN/_templates/autosummary/class.rst +13 -0
- docs/zh-CN/_templates/callable.rst +14 -0
- docs/zh-CN/conf.py +242 -0
- docs/zh-CN/cp_origin_docs.sh +9 -0
- docs/zh-CN/docutils.conf +2 -0
- docs/zh-CN/index.rst +49 -0
- eval.sh +19 -0
- eval_scripts/idefics_9b_instruct.sh +15 -0
- install.sh +2 -0
- load_data.ipynb +0 -0
- models.txt +216 -0
- models_candiate.txt +1 -0
- requirements.txt +31 -0
- requirements/docs.txt +11 -0
- requirements_conda.txt +304 -0
.github/workflows/lint.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: lint
|
| 2 |
+
|
| 3 |
+
on: [push, pull_request]
|
| 4 |
+
|
| 5 |
+
concurrency:
|
| 6 |
+
group: ${{ github.workflow }}-${{ github.ref }}
|
| 7 |
+
cancel-in-progress: true
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
lint:
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
steps:
|
| 13 |
+
- uses: actions/checkout@v2
|
| 14 |
+
- name: Set up Python 3.10
|
| 15 |
+
uses: actions/setup-python@v2
|
| 16 |
+
with:
|
| 17 |
+
python-version: 3.10.15
|
| 18 |
+
- name: Install pre-commit hook
|
| 19 |
+
run: |
|
| 20 |
+
pip install pre-commit
|
| 21 |
+
pre-commit install
|
| 22 |
+
- name: Linting
|
| 23 |
+
run: pre-commit run --all-files
|
.gitignore
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.idea/
|
| 2 |
+
|
| 3 |
+
# Byte-compiled / optimized / DLL files
|
| 4 |
+
__pycache__/
|
| 5 |
+
*.py[cod]
|
| 6 |
+
*$py.class
|
| 7 |
+
|
| 8 |
+
# C extensions
|
| 9 |
+
*.so
|
| 10 |
+
|
| 11 |
+
# Distribution / packaging
|
| 12 |
+
.Python
|
| 13 |
+
build/
|
| 14 |
+
develop-eggs/
|
| 15 |
+
dist/
|
| 16 |
+
downloads/
|
| 17 |
+
eggs/
|
| 18 |
+
.eggs/
|
| 19 |
+
lib/
|
| 20 |
+
lib64/
|
| 21 |
+
parts/
|
| 22 |
+
sdist/
|
| 23 |
+
var/
|
| 24 |
+
wheels/
|
| 25 |
+
share/python-wheels/
|
| 26 |
+
*.egg-info/
|
| 27 |
+
.installed.cfg
|
| 28 |
+
*.egg
|
| 29 |
+
MANIFEST
|
| 30 |
+
.vscode/
|
| 31 |
+
.gradio/
|
| 32 |
+
|
| 33 |
+
# PyInstaller
|
| 34 |
+
# Usually these files are written by a python script from a template
|
| 35 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 36 |
+
*.manifest
|
| 37 |
+
*.spec
|
| 38 |
+
|
| 39 |
+
# Installer logs
|
| 40 |
+
pip-log.txt
|
| 41 |
+
pip-delete-this-directory.txt
|
| 42 |
+
|
| 43 |
+
# Unit test / coverage reports
|
| 44 |
+
htmlcov/
|
| 45 |
+
.tox/
|
| 46 |
+
.nox/
|
| 47 |
+
.coverage
|
| 48 |
+
.coverage.*
|
| 49 |
+
.cache
|
| 50 |
+
nosetests.xml
|
| 51 |
+
coverage.xml
|
| 52 |
+
*.cover
|
| 53 |
+
*.py,cover
|
| 54 |
+
.hypothesis/
|
| 55 |
+
.pytest_cache/
|
| 56 |
+
cover/
|
| 57 |
+
|
| 58 |
+
# Translations
|
| 59 |
+
*.mo
|
| 60 |
+
*.pot
|
| 61 |
+
|
| 62 |
+
# Django stuff:
|
| 63 |
+
*.log
|
| 64 |
+
local_settings.py
|
| 65 |
+
db.sqlite3
|
| 66 |
+
db.sqlite3-journal
|
| 67 |
+
|
| 68 |
+
# Flask stuff:
|
| 69 |
+
instance/
|
| 70 |
+
.webassets-cache
|
| 71 |
+
|
| 72 |
+
# Scrapy stuff:
|
| 73 |
+
.scrapy
|
| 74 |
+
|
| 75 |
+
# Sphinx documentation
|
| 76 |
+
docs/_build/
|
| 77 |
+
|
| 78 |
+
# PyBuilder
|
| 79 |
+
.pybuilder/
|
| 80 |
+
target/
|
| 81 |
+
|
| 82 |
+
# Jupyter Notebook
|
| 83 |
+
.ipynb_checkpoints
|
| 84 |
+
|
| 85 |
+
# IPython
|
| 86 |
+
profile_default/
|
| 87 |
+
ipython_config.py
|
| 88 |
+
|
| 89 |
+
# pyenv
|
| 90 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 91 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 92 |
+
# .python-version
|
| 93 |
+
|
| 94 |
+
# pipenv
|
| 95 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 96 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 97 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 98 |
+
# install all needed dependencies.
|
| 99 |
+
#Pipfile.lock
|
| 100 |
+
|
| 101 |
+
# poetry
|
| 102 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 103 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 104 |
+
# commonly ignored for libraries.
|
| 105 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 106 |
+
#poetry.lock
|
| 107 |
+
|
| 108 |
+
# pdm
|
| 109 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 110 |
+
#pdm.lock
|
| 111 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 112 |
+
# in version control.
|
| 113 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 114 |
+
.pdm.toml
|
| 115 |
+
|
| 116 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 117 |
+
__pypackages__/
|
| 118 |
+
|
| 119 |
+
# Celery stuff
|
| 120 |
+
celerybeat-schedule
|
| 121 |
+
celerybeat.pid
|
| 122 |
+
|
| 123 |
+
# SageMath parsed files
|
| 124 |
+
*.sage.py
|
| 125 |
+
|
| 126 |
+
# Environments
|
| 127 |
+
.env
|
| 128 |
+
.venv
|
| 129 |
+
env/
|
| 130 |
+
venv/
|
| 131 |
+
ENV/
|
| 132 |
+
env.bak/
|
| 133 |
+
venv.bak/
|
| 134 |
+
|
| 135 |
+
# Spyder project settings
|
| 136 |
+
.spyderproject
|
| 137 |
+
.spyproject
|
| 138 |
+
|
| 139 |
+
# Rope project settings
|
| 140 |
+
.ropeproject
|
| 141 |
+
|
| 142 |
+
# mkdocs documentation
|
| 143 |
+
/site
|
| 144 |
+
|
| 145 |
+
# mypy
|
| 146 |
+
.mypy_cache/
|
| 147 |
+
.dmypy.json
|
| 148 |
+
dmypy.json
|
| 149 |
+
|
| 150 |
+
# Pyre type checker
|
| 151 |
+
.pyre/
|
| 152 |
+
|
| 153 |
+
# pytype static type analyzer
|
| 154 |
+
.pytype/
|
| 155 |
+
|
| 156 |
+
# Cython debug symbols
|
| 157 |
+
cython_debug/
|
| 158 |
+
|
| 159 |
+
# Images
|
| 160 |
+
images/
|
| 161 |
+
|
| 162 |
+
scripts/*ttf
|
| 163 |
+
.history
|
| 164 |
+
cache_dir/*
|
| 165 |
+
|
| 166 |
+
# Evaluation Outputs
|
| 167 |
+
outputs/*
|
| 168 |
+
demo.ipynb
|
| 169 |
+
*json
|
| 170 |
+
.vscode
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: |
|
| 2 |
+
(?x)^(
|
| 3 |
+
scripts/|
|
| 4 |
+
assets/|
|
| 5 |
+
vlmeval/config.py
|
| 6 |
+
)
|
| 7 |
+
repos:
|
| 8 |
+
- repo: https://github.com/PyCQA/flake8
|
| 9 |
+
rev: 6.1.0
|
| 10 |
+
hooks:
|
| 11 |
+
- id: flake8
|
| 12 |
+
args: ["--max-line-length=120", "--ignore=F401,F403,F405,E402,E722,E741,W503,E231,E702"]
|
| 13 |
+
exclude: ^configs/
|
| 14 |
+
- repo: https://github.com/pre-commit/mirrors-yapf
|
| 15 |
+
rev: v0.30.0
|
| 16 |
+
hooks:
|
| 17 |
+
- id: yapf
|
| 18 |
+
args: ["--style={column_limit=120}"]
|
| 19 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 20 |
+
rev: v3.1.0
|
| 21 |
+
hooks:
|
| 22 |
+
- id: trailing-whitespace
|
| 23 |
+
- id: check-yaml
|
| 24 |
+
- id: end-of-file-fixer
|
| 25 |
+
- id: requirements-txt-fixer
|
| 26 |
+
- id: check-merge-conflict
|
| 27 |
+
- id: fix-encoding-pragma
|
| 28 |
+
args: ["--remove"]
|
| 29 |
+
- id: mixed-line-ending
|
| 30 |
+
args: ["--fix=lf"]
|
LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright 2023 VLMEvalKit Authors. All rights reserved.
|
| 2 |
+
|
| 3 |
+
Apache License
|
| 4 |
+
Version 2.0, January 2004
|
| 5 |
+
http://www.apache.org/licenses/
|
| 6 |
+
|
| 7 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 8 |
+
|
| 9 |
+
1. Definitions.
|
| 10 |
+
|
| 11 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 12 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 15 |
+
the copyright owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 18 |
+
other entities that control, are controlled by, or are under common
|
| 19 |
+
control with that entity. For the purposes of this definition,
|
| 20 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 21 |
+
direction or management of such entity, whether by contract or
|
| 22 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 23 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 24 |
+
|
| 25 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 26 |
+
exercising permissions granted by this License.
|
| 27 |
+
|
| 28 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 29 |
+
including but not limited to software source code, documentation
|
| 30 |
+
source, and configuration files.
|
| 31 |
+
|
| 32 |
+
"Object" form shall mean any form resulting from mechanical
|
| 33 |
+
transformation or translation of a Source form, including but
|
| 34 |
+
not limited to compiled object code, generated documentation,
|
| 35 |
+
and conversions to other media types.
|
| 36 |
+
|
| 37 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 38 |
+
Object form, made available under the License, as indicated by a
|
| 39 |
+
copyright notice that is included in or attached to the work
|
| 40 |
+
(an example is provided in the Appendix below).
|
| 41 |
+
|
| 42 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 43 |
+
form, that is based on (or derived from) the Work and for which the
|
| 44 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 45 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 46 |
+
of this License, Derivative Works shall not include works that remain
|
| 47 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 48 |
+
the Work and Derivative Works thereof.
|
| 49 |
+
|
| 50 |
+
"Contribution" shall mean any work of authorship, including
|
| 51 |
+
the original version of the Work and any modifications or additions
|
| 52 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 53 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 54 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 55 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 56 |
+
means any form of electronic, verbal, or written communication sent
|
| 57 |
+
to the Licensor or its representatives, including but not limited to
|
| 58 |
+
communication on electronic mailing lists, source code control systems,
|
| 59 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 60 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 61 |
+
excluding communication that is conspicuously marked or otherwise
|
| 62 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 63 |
+
|
| 64 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 65 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 66 |
+
subsequently incorporated within the Work.
|
| 67 |
+
|
| 68 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 69 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 70 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 71 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 72 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 73 |
+
Work and such Derivative Works in Source or Object form.
|
| 74 |
+
|
| 75 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 76 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 77 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 78 |
+
(except as stated in this section) patent license to make, have made,
|
| 79 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 80 |
+
where such license applies only to those patent claims licensable
|
| 81 |
+
by such Contributor that are necessarily infringed by their
|
| 82 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 83 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 84 |
+
institute patent litigation against any entity (including a
|
| 85 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 86 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 87 |
+
or contributory patent infringement, then any patent licenses
|
| 88 |
+
granted to You under this License for that Work shall terminate
|
| 89 |
+
as of the date such litigation is filed.
|
| 90 |
+
|
| 91 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 92 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 93 |
+
modifications, and in Source or Object form, provided that You
|
| 94 |
+
meet the following conditions:
|
| 95 |
+
|
| 96 |
+
(a) You must give any other recipients of the Work or
|
| 97 |
+
Derivative Works a copy of this License; and
|
| 98 |
+
|
| 99 |
+
(b) You must cause any modified files to carry prominent notices
|
| 100 |
+
stating that You changed the files; and
|
| 101 |
+
|
| 102 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 103 |
+
that You distribute, all copyright, patent, trademark, and
|
| 104 |
+
attribution notices from the Source form of the Work,
|
| 105 |
+
excluding those notices that do not pertain to any part of
|
| 106 |
+
the Derivative Works; and
|
| 107 |
+
|
| 108 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 109 |
+
distribution, then any Derivative Works that You distribute must
|
| 110 |
+
include a readable copy of the attribution notices contained
|
| 111 |
+
within such NOTICE file, excluding those notices that do not
|
| 112 |
+
pertain to any part of the Derivative Works, in at least one
|
| 113 |
+
of the following places: within a NOTICE text file distributed
|
| 114 |
+
as part of the Derivative Works; within the Source form or
|
| 115 |
+
documentation, if provided along with the Derivative Works; or,
|
| 116 |
+
within a display generated by the Derivative Works, if and
|
| 117 |
+
wherever such third-party notices normally appear. The contents
|
| 118 |
+
of the NOTICE file are for informational purposes only and
|
| 119 |
+
do not modify the License. You may add Your own attribution
|
| 120 |
+
notices within Derivative Works that You distribute, alongside
|
| 121 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 122 |
+
that such additional attribution notices cannot be construed
|
| 123 |
+
as modifying the License.
|
| 124 |
+
|
| 125 |
+
You may add Your own copyright statement to Your modifications and
|
| 126 |
+
may provide additional or different license terms and conditions
|
| 127 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 128 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 129 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 130 |
+
the conditions stated in this License.
|
| 131 |
+
|
| 132 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 133 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 134 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 135 |
+
this License, without any additional terms or conditions.
|
| 136 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 137 |
+
the terms of any separate license agreement you may have executed
|
| 138 |
+
with Licensor regarding such Contributions.
|
| 139 |
+
|
| 140 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 141 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 142 |
+
except as required for reasonable and customary use in describing the
|
| 143 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 144 |
+
|
| 145 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 146 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 147 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 148 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 149 |
+
implied, including, without limitation, any warranties or conditions
|
| 150 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 151 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 152 |
+
appropriateness of using or redistributing the Work and assume any
|
| 153 |
+
risks associated with Your exercise of permissions under this License.
|
| 154 |
+
|
| 155 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 156 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 157 |
+
unless required by applicable law (such as deliberate and grossly
|
| 158 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 159 |
+
liable to You for damages, including any direct, indirect, special,
|
| 160 |
+
incidental, or consequential damages of any character arising as a
|
| 161 |
+
result of this License or out of the use or inability to use the
|
| 162 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 163 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 164 |
+
other commercial damages or losses), even if such Contributor
|
| 165 |
+
has been advised of the possibility of such damages.
|
| 166 |
+
|
| 167 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 168 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 169 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 170 |
+
or other liability obligations and/or rights consistent with this
|
| 171 |
+
License. However, in accepting such obligations, You may act only
|
| 172 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 173 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 174 |
+
defend, and hold each Contributor harmless for any liability
|
| 175 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 176 |
+
of your accepting any such warranty or additional liability.
|
| 177 |
+
|
| 178 |
+
END OF TERMS AND CONDITIONS
|
| 179 |
+
|
| 180 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 181 |
+
|
| 182 |
+
To apply the Apache License to your work, attach the following
|
| 183 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 184 |
+
replaced with your own identifying information. (Don't include
|
| 185 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 186 |
+
comment syntax for the file format. We also recommend that a
|
| 187 |
+
file or class name and description of purpose be included on the
|
| 188 |
+
same "printed page" as the copyright notice for easier
|
| 189 |
+
identification within third-party archives.
|
| 190 |
+
|
| 191 |
+
Copyright 2023 VLMEvalKit Authors.
|
| 192 |
+
|
| 193 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 194 |
+
you may not use this file except in compliance with the License.
|
| 195 |
+
You may obtain a copy of the License at
|
| 196 |
+
|
| 197 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 198 |
+
|
| 199 |
+
Unless required by applicable law or agreed to in writing, software
|
| 200 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 202 |
+
See the License for the specific language governing permissions and
|
| 203 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
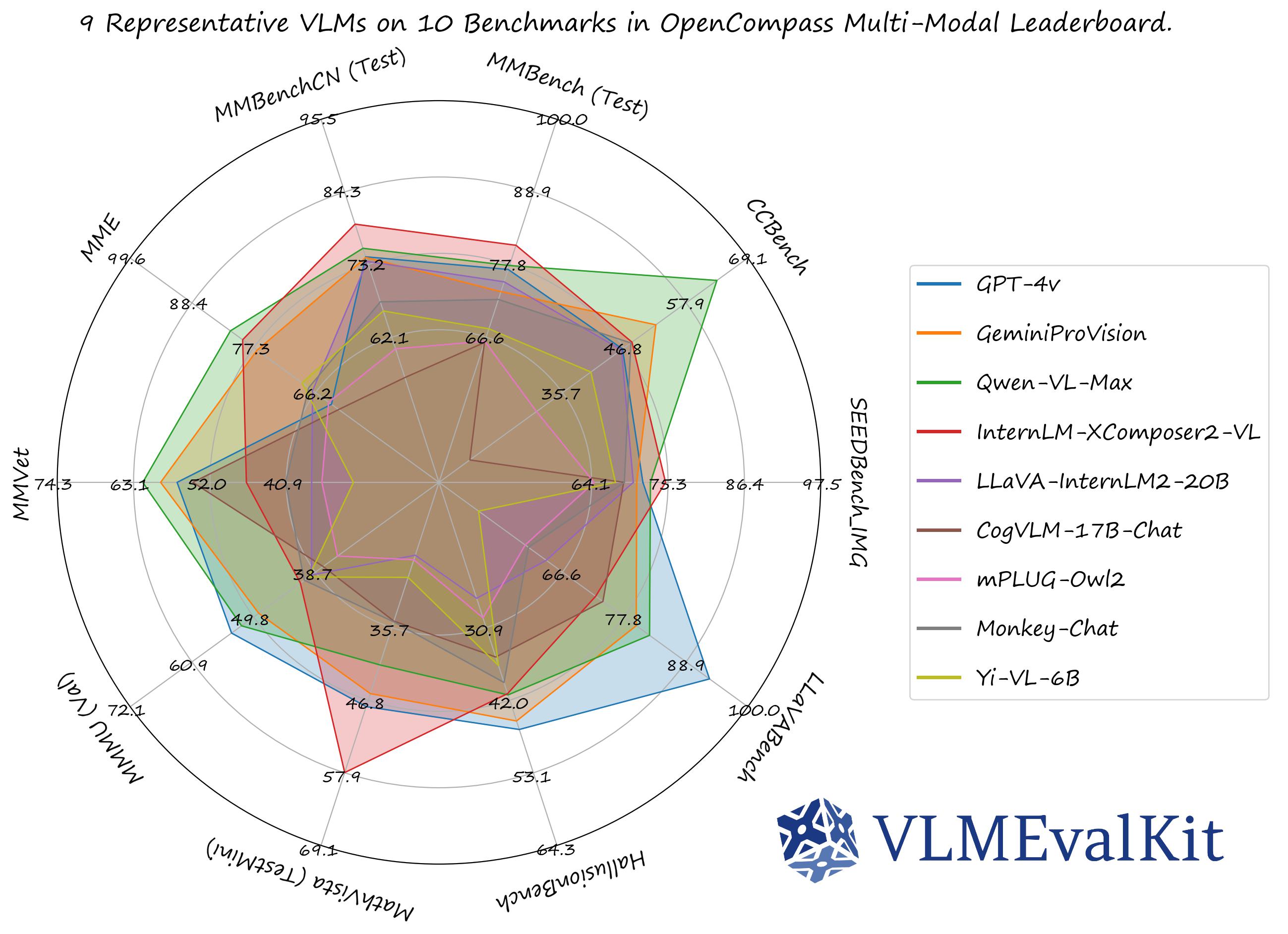
|
| 4 |
+
|
| 5 |
+
<b>A Toolkit for Evaluating Large Vision-Language Models. </b>
|
| 6 |
+
|
| 7 |
+
[![][github-contributors-shield]][github-contributors-link] • [![][github-forks-shield]][github-forks-link] • [![][github-stars-shield]][github-stars-link] • [![][github-issues-shield]][github-issues-link] • [![][github-license-shield]][github-license-link]
|
| 8 |
+
|
| 9 |
+
English | [简体中文](/docs/zh-CN/README_zh-CN.md) | [日本語](/docs/ja/README_ja.md)
|
| 10 |
+
|
| 11 |
+
<a href="https://rank.opencompass.org.cn/leaderboard-multimodal">🏆 OC Learderboard </a> •
|
| 12 |
+
<a href="#%EF%B8%8F-quickstart">🏗️Quickstart </a> •
|
| 13 |
+
<a href="#-datasets-models-and-evaluation-results">📊Datasets & Models </a> •
|
| 14 |
+
<a href="#%EF%B8%8F-development-guide">🛠️Development </a> •
|
| 15 |
+
<a href="#-the-goal-of-vlmevalkit">🎯Goal </a> •
|
| 16 |
+
<a href="#%EF%B8%8F-citation">🖊️Citation </a>
|
| 17 |
+
|
| 18 |
+
<a href="https://huggingface.co/spaces/opencompass/open_vlm_leaderboard">🤗 HF Leaderboard</a> •
|
| 19 |
+
<a href="https://huggingface.co/datasets/VLMEval/OpenVLMRecords">🤗 Evaluation Records</a> •
|
| 20 |
+
<a href="https://huggingface.co/spaces/opencompass/openvlm_video_leaderboard">🤗 HF Video Leaderboard</a> •
|
| 21 |
+
<a href="https://discord.gg/evDT4GZmxN">🔊 Discord</a> •
|
| 22 |
+
<a href="https://www.arxiv.org/abs/2407.11691">📝 Report</a>
|
| 23 |
+
</div>
|
| 24 |
+
|
| 25 |
+
**VLMEvalKit** (the python package name is **vlmeval**) is an **open-source evaluation toolkit** of **large vision-language models (LVLMs)**. It enables **one-command evaluation** of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt **generation-based evaluation** for all LVLMs, and provide the evaluation results obtained with both **exact matching** and **LLM-based answer extraction**.
|
| 26 |
+
|
| 27 |
+
## 🆕 News
|
| 28 |
+
- **[2024-12-02]** Supported [VisOnlyQA](https://github.com/psunlpgroup/VisOnlyQA/), a benchmark for evaluating the visual perception capabilities 🔥🔥🔥
|
| 29 |
+
- **[2024-11-26]** Supported [Ovis1.6-Gemma2-27B](https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-27B), thanks to **[runninglsy](https://github.com/runninglsy)** 🔥🔥🔥
|
| 30 |
+
- **[2024-11-25]** Create a new flag `VLMEVALKIT_USE_MODELSCOPE`. By setting this environment variable, you can download the video benchmarks supported from **[modelscope](https://www.modelscope.cn)** 🔥🔥🔥
|
| 31 |
+
- **[2024-11-25]** Supported **[VizWiz](https://vizwiz.org/tasks/vqa/)** benchmark 🔥🔥🔥
|
| 32 |
+
- **[2024-11-22]** Supported the inference of **[MMGenBench](https://mmgenbench.alsoai.com)**, thanks **[lerogo](https://github.com/lerogo)** 🔥🔥🔥
|
| 33 |
+
- **[2024-11-22]** Supported **[Dynamath](https://huggingface.co/datasets/DynaMath/DynaMath_Sample)**, a multimodal math benchmark comprising of 501 SEED problems and 10 variants generated based on random seeds. The benchmark can be used to measure the robustness of MLLMs in multi-modal math solving 🔥🔥🔥
|
| 34 |
+
- **[2024-11-21]** Integrated a new config system to enable more flexible evaluation settings. Check the [Document](/docs/en/ConfigSystem.md) or run `python run.py --help` for more details 🔥🔥🔥
|
| 35 |
+
- **[2024-11-21]** Supported **[QSpatial](https://andrewliao11.github.io/spatial_prompt/)**, a multimodal benchmark for Quantitative Spatial Reasoning (determine the size / distance, e.g.), thanks **[andrewliao11](https://github.com/andrewliao11)** for providing the official support 🔥🔥🔥
|
| 36 |
+
- **[2024-11-21]** Supported **[MM-Math](https://github.com/kge-sun/mm-math)**, a new multimodal math benchmark comprising of ~6K middle school multi-modal reasoning math problems. GPT-4o-20240806 achieces 22.5% accuracy on this benchmark 🔥🔥🔥
|
| 37 |
+
- **[2024-11-16]** Supported **[OlympiadBench](https://github.com/OpenBMB/OlympiadBench)**, a new multimodal benchmark comprising olympiad-level math and physics questions 🔥🔥🔥
|
| 38 |
+
- **[2024-11-16]** Supported **[WildVision](https://huggingface.co/datasets/WildVision/wildvision-bench)**, a new subjective multimodal benchmark derived from multi-modal arena data 🔥🔥🔥
|
| 39 |
+
- **[2024-11-13]** Supported **[MIA-Bench](https://arxiv.org/abs/2407.01509)**, a multimodal instruction-following benchmark 🔥🔥🔥
|
| 40 |
+
|
| 41 |
+
## 🏗️ QuickStart
|
| 42 |
+
|
| 43 |
+
See [[QuickStart](/docs/en/Quickstart.md) | [快速开始](/docs/zh-CN/Quickstart.md)] for a quick start guide.
|
| 44 |
+
|
| 45 |
+
## 📊 Datasets, Models, and Evaluation Results
|
| 46 |
+
|
| 47 |
+
### Evaluation Results
|
| 48 |
+
|
| 49 |
+
**The performance numbers on our official multi-modal leaderboards can be downloaded from here!**
|
| 50 |
+
|
| 51 |
+
**[OpenVLM Leaderboard](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard)**: **[Download All DETAILED Results](http://opencompass.openxlab.space/assets/OpenVLM.json)**.
|
| 52 |
+
|
| 53 |
+
### Supported Benchmarks
|
| 54 |
+
|
| 55 |
+
**Supported Image Understanding Dataset**
|
| 56 |
+
|
| 57 |
+
- By default, all evaluation results are presented in [**OpenVLM Leaderboard**](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard).
|
| 58 |
+
- Abbrs: `MCQ`: Multi-choice question; `Y/N`: Yes-or-No Questions; `MTT`: Benchmark with Multi-turn Conversations; `MTI`: Benchmark with Multi-Image as Inputs.
|
| 59 |
+
|
| 60 |
+
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|
| 61 |
+
| ------------------------------------------------------------ | ------------------------------------------------------ | --------- | --------- | --------- | --------- |
|
| 62 |
+
| [**MMBench Series**](https://github.com/open-compass/mmbench/): <br>MMBench, MMBench-CN, CCBench | MMBench\_DEV\_[EN/CN] <br>MMBench\_TEST\_[EN/CN]<br>MMBench\_DEV\_[EN/CN]\_V11<br>MMBench\_TEST\_[EN/CN]\_V11<br>CCBench | MCQ | [**MMStar**](https://github.com/MMStar-Benchmark/MMStar) | MMStar | MCQ |
|
| 63 |
+
| [**MME**](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation) | MME | Y/N | [**SEEDBench Series**](https://github.com/AILab-CVC/SEED-Bench) | SEEDBench_IMG <br>SEEDBench2 <br>SEEDBench2_Plus | MCQ |
|
| 64 |
+
| [**MM-Vet**](https://github.com/yuweihao/MM-Vet) | MMVet | VQA | [**MMMU**](https://mmmu-benchmark.github.io) | MMMU_[DEV_VAL/TEST] | MCQ |
|
| 65 |
+
| [**MathVista**](https://mathvista.github.io) | MathVista_MINI | VQA | [**ScienceQA_IMG**](https://scienceqa.github.io) | ScienceQA_[VAL/TEST] | MCQ |
|
| 66 |
+
| [**COCO Caption**](https://cocodataset.org) | COCO_VAL | Caption | [**HallusionBench**](https://github.com/tianyi-lab/HallusionBench) | HallusionBench | Y/N |
|
| 67 |
+
| [**OCRVQA**](https://ocr-vqa.github.io)* | OCRVQA_[TESTCORE/TEST] | VQA | [**TextVQA**](https://textvqa.org)* | TextVQA_VAL | VQA |
|
| 68 |
+
| [**ChartQA**](https://github.com/vis-nlp/ChartQA)* | ChartQA_TEST | VQA | [**AI2D**](https://allenai.org/data/diagrams) | AI2D_[TEST/TEST_NO_MASK] | MCQ |
|
| 69 |
+
| [**LLaVABench**](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) | LLaVABench | VQA | [**DocVQA**](https://www.docvqa.org)+ | DocVQA_[VAL/TEST] | VQA |
|
| 70 |
+
| [**InfoVQA**](https://www.docvqa.org/datasets/infographicvqa)+ | InfoVQA_[VAL/TEST] | VQA | [**OCRBench**](https://github.com/Yuliang-Liu/MultimodalOCR) | OCRBench | VQA |
|
| 71 |
+
| [**RealWorldQA**](https://x.ai/blog/grok-1.5v) | RealWorldQA | MCQ | [**POPE**](https://github.com/AoiDragon/POPE) | POPE | Y/N |
|
| 72 |
+
| [**Core-MM**](https://github.com/core-mm/core-mm)- | CORE_MM (MTI) | VQA | [**MMT-Bench**](https://mmt-bench.github.io) | MMT-Bench\_[VAL/ALL]<br>MMT-Bench\_[VAL/ALL]_MI | MCQ (MTI) |
|
| 73 |
+
| [**MLLMGuard**](https://github.com/Carol-gutianle/MLLMGuard) - | MLLMGuard_DS | VQA | [**AesBench**](https://github.com/yipoh/AesBench)+ | AesBench_[VAL/TEST] | MCQ |
|
| 74 |
+
| [**VCR-wiki**](https://huggingface.co/vcr-org/) + | VCR\_[EN/ZH]\_[EASY/HARD]_[ALL/500/100] | VQA | [**MMLongBench-Doc**](https://mayubo2333.github.io/MMLongBench-Doc/)+ | MMLongBench_DOC | VQA (MTI) |
|
| 75 |
+
| [**BLINK**](https://zeyofu.github.io/blink/) | BLINK | MCQ (MTI) | [**MathVision**](https://mathvision-cuhk.github.io)+ | MathVision<br>MathVision_MINI | VQA |
|
| 76 |
+
| [**MT-VQA**](https://github.com/bytedance/MTVQA) | MTVQA_TEST | VQA | [**MMDU**](https://liuziyu77.github.io/MMDU/)+ | MMDU | VQA (MTT, MTI) |
|
| 77 |
+
| [**Q-Bench1**](https://github.com/Q-Future/Q-Bench) | Q-Bench1_[VAL/TEST] | MCQ | [**A-Bench**](https://github.com/Q-Future/A-Bench) | A-Bench_[VAL/TEST] | MCQ |
|
| 78 |
+
| [**DUDE**](https://arxiv.org/abs/2305.08455)+ | DUDE | VQA (MTI) | [**SlideVQA**](https://arxiv.org/abs/2301.04883)+ | SLIDEVQA<br>SLIDEVQA_MINI | VQA (MTI) |
|
| 79 |
+
| [**TaskMeAnything ImageQA Random**](https://huggingface.co/datasets/weikaih/TaskMeAnything-v1-imageqa-random)+ | TaskMeAnything_v1_imageqa_random | MCQ | [**MMMB and Multilingual MMBench**](https://sun-hailong.github.io/projects/Parrot/)+ | MMMB\_[ar/cn/en/pt/ru/tr]<br>MMBench_dev\_[ar/cn/en/pt/ru/tr]<br>MMMB<br>MTL_MMBench_DEV<br>PS: MMMB & MTL_MMBench_DEV <br>are **all-in-one** names for 6 langs | MCQ |
|
| 80 |
+
| [**A-OKVQA**](https://arxiv.org/abs/2206.01718)+ | A-OKVQA | MCQ | [**MuirBench**](https://muirbench.github.io)+ | MUIRBench | MCQ |
|
| 81 |
+
| [**GMAI-MMBench**](https://huggingface.co/papers/2408.03361)+ | GMAI-MMBench_VAL | MCQ | [**TableVQABench**](https://arxiv.org/abs/2404.19205)+ | TableVQABench | VQA |
|
| 82 |
+
| [**MME-RealWorld**](https://arxiv.org/abs/2408.13257)+ | MME-RealWorld[-CN]<br/>[MME-RealWorld-Lite](https://huggingface.co/datasets/yifanzhang114/MME-RealWorld-Lite) | MCQ | [**HRBench**](https://arxiv.org/abs/2408.15556)+ | HRBench[4K/8K] | MCQ |
|
| 83 |
+
| [**MathVerse**](https://mathverse-cuhk.github.io/)+ | MathVerse_MINI<br/>MathVerse_MINI_Vision_Only <br/>MathVerse_MINI_Vision_Dominant<br/>MathVerse_MINI_Vision_Intensive<br/>MathVerse_MINI_Text_Lite<br/>MathVerse_MINI_Text_Dominant | VQA | [**AMBER**](https://github.com/junyangwang0410/AMBER)+ | AMBER | Y/N |
|
| 84 |
+
| [**CRPE**](https://huggingface.co/datasets/OpenGVLab/CRPE)+ | CRPE_[EXIST/RELATION] | VQA | **[MMSearch](https://mmsearch.github.io/)**$$^1$$ | - | **-** |
|
| 85 |
+
| **[R-Bench](https://arxiv.org/abs/2410.05474)**+ | R-Bench-[Dis/Ref] | MCQ | **[WorldMedQA-V](https://www.arxiv.org/abs/2410.12722)**+ | WorldMedQA-V | MCQ |
|
| 86 |
+
| **[GQA](https://cs.stanford.edu/people/dorarad/gqa/about.html)**+ | GQA_TestDev_Balanced | VQA | **[MIA-Bench](https://arxiv.org/abs/2407.01509)**+ | MIA-Bench | VQA |
|
| 87 |
+
| **[WildVision](https://huggingface.co/datasets/WildVision/wildvision-bench)**+ | WildVision | VQA | **[OlympiadBench](https://github.com/OpenBMB/OlympiadBench)**+ | OlympiadBench | VQA |
|
| 88 |
+
| **[MM-Math](https://github.com/kge-sun/mm-math)**+ | MM-Math | VQA | **[Dynamath](https://huggingface.co/datasets/DynaMath/DynaMath_Sample)** | DynaMath | VQA |
|
| 89 |
+
| **[MMGenBench](https://mmgenbench.alsoai.com/)**- | MMGenBench-Test<br>MMGenBench-Domain | - | **[QSpatial](https://andrewliao11.github.io/spatial_prompt/)**+ | QSpatial_[plus/scannet] | VQA |
|
| 90 |
+
| **[VizWiz](https://vizwiz.org/tasks/vqa/)**+ | VizWiz | VQA | **[VisOnlyQA](https://github.com/psunlpgroup/VisOnlyQA/)**+ | VisOnlyQA-VLMEvalKit | MCQ |
|
| 91 |
+
|
| 92 |
+
**\*** We only provide a subset of the evaluation results, since some VLMs do not yield reasonable results under the zero-shot setting
|
| 93 |
+
|
| 94 |
+
**\+** The evaluation results are not available yet
|
| 95 |
+
|
| 96 |
+
**\-** Only inference is supported in VLMEvalKit (That includes the `TEST` splits of some benchmarks that do not include the ground truth answers).
|
| 97 |
+
|
| 98 |
+
$$^1$$ VLMEvalKit is integrated in its official repository.
|
| 99 |
+
|
| 100 |
+
VLMEvalKit will use a **judge LLM** to extract answer from the output if you set the key, otherwise it uses the **exact matching** mode (find "Yes", "No", "A", "B", "C"... in the output strings). **The exact matching can only be applied to the Yes-or-No tasks and the Multi-choice tasks.**
|
| 101 |
+
|
| 102 |
+
**Supported Video Understanding Dataset**
|
| 103 |
+
|
| 104 |
+
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|
| 105 |
+
| ---------------------------------------------------- | -------------------------- | ---- | ------- | -------------------------- | ---- |
|
| 106 |
+
| **[MMBench-Video](https://mmbench-video.github.io)** | MMBench-Video | VQA | **[Video-MME](https://video-mme.github.io/)** | Video-MME | MCQ |
|
| 107 |
+
| **[MVBench](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/MVBENCH.md)**| MVBench/MVBench_MP4 | MCQ | **[MLVU](https://github.com/JUNJIE99/MLVU)** | MLVU | MCQ & VQA |
|
| 108 |
+
| **[TempCompass](https://arxiv.org/abs/2403.00476)** | TempCompass | MCQ & Y/N & Caption | **[LongVideoBench](https://longvideobench.github.io/)** | LongVideoBench | MCQ |
|
| 109 |
+
|
| 110 |
+
### Supported Models
|
| 111 |
+
|
| 112 |
+
**Supported API Models**
|
| 113 |
+
|
| 114 |
+
| [**GPT-4v (20231106, 20240409)**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**GPT-4o**](https://openai.com/index/hello-gpt-4o/) 🎞️🚅 | [**Gemini-1.0-Pro**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**Gemini-1.5-Pro**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**Step-1V**](https://www.stepfun.com/#step1v) 🎞️🚅 |
|
| 115 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------- |
|
| 116 |
+
| [**Reka-[Edge / Flash / Core]**](https://www.reka.ai)🚅 | [**Qwen-VL-[Plus / Max]**](https://huggingface.co/spaces/Qwen/Qwen-VL-Max) 🎞️🚅<br>[**Qwen-VL-[Plus / Max]-0809**](https://huggingface.co/spaces/Qwen/Qwen-VL-Max) 🎞️🚅 | [**Claude3-[Haiku / Sonnet / Opus]**](https://www.anthropic.com/news/claude-3-family) 🎞️🚅 | [**GLM-4v**](https://open.bigmodel.cn/dev/howuse/glm4v) 🚅 | [**CongRong**](https://mllm.cloudwalk.com/web) 🎞️🚅 |
|
| 117 |
+
| [**Claude3.5-Sonnet (20240620, 20241022)**](https://www.anthropic.com/news/claude-3-5-sonnet) 🎞️🚅 | [**GPT-4o-Mini**](https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/) 🎞️🚅 | [**Yi-Vision**](https://platform.lingyiwanwu.com)🎞️🚅 | [**Hunyuan-Vision**](https://cloud.tencent.com/document/product/1729)🎞️🚅 | [**BlueLM-V**](https://developers.vivo.com/) 🎞️🚅 |
|
| 118 |
+
| [**TeleMM**](https://cloud.siliconflow.cn/playground/chat/17885302607)🎞️🚅 |
|
| 119 |
+
|
| 120 |
+
**Supported PyTorch / HF Models**
|
| 121 |
+
|
| 122 |
+
| [**IDEFICS-[9B/80B/v2-8B/v3-8B]-Instruct**](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct)🚅🎞️ | [**InstructBLIP-[7B/13B]**](https://github.com/salesforce/LAVIS/blob/main/projects/instructblip/README.md) | [**LLaVA-[v1-7B/v1.5-7B/v1.5-13B]**](https://github.com/haotian-liu/LLaVA) | [**MiniGPT-4-[v1-7B/v1-13B/v2-7B]**](https://github.com/Vision-CAIR/MiniGPT-4) |
|
| 123 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
| 124 |
+
| [**mPLUG-Owl[2/3]**](https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2)🎞️ | [**OpenFlamingo-v2**](https://github.com/mlfoundations/open_flamingo)🎞️ | [**PandaGPT-13B**](https://github.com/yxuansu/PandaGPT) | [**Qwen-VL**](https://huggingface.co/Qwen/Qwen-VL)🚅🎞️ <br>[**Qwen-VL-Chat**](https://huggingface.co/Qwen/Qwen-VL-Chat)🚅🎞️ |
|
| 125 |
+
| [**VisualGLM-6B**](https://huggingface.co/THUDM/visualglm-6b)🚅 | [**InternLM-XComposer-[1/2]**](https://huggingface.co/internlm/internlm-xcomposer-7b)🚅 | [**ShareGPT4V-[7B/13B]**](https://sharegpt4v.github.io)🚅 | [**TransCore-M**](https://github.com/PCIResearch/TransCore-M) |
|
| 126 |
+
| [**LLaVA (XTuner)**](https://huggingface.co/xtuner/llava-internlm-7b)🚅 | [**CogVLM-[Chat/Llama3]**](https://huggingface.co/THUDM/cogvlm-chat-hf)🚅 | [**ShareCaptioner**](https://huggingface.co/spaces/Lin-Chen/Share-Captioner)🚅 | [**CogVLM-Grounding-Generalist**](https://huggingface.co/THUDM/cogvlm-grounding-generalist-hf)🚅 |
|
| 127 |
+
| [**Monkey**](https://github.com/Yuliang-Liu/Monkey)🚅<br>[**Monkey-Chat**](https://github.com/Yuliang-Liu/Monkey)🚅 | [**EMU2-Chat**](https://github.com/baaivision/Emu)🚅🎞️ | [**Yi-VL-[6B/34B]**](https://huggingface.co/01-ai/Yi-VL-6B) | [**MMAlaya**](https://huggingface.co/DataCanvas/MMAlaya)🚅 |
|
| 128 |
+
| [**InternLM-XComposer-2.5**](https://github.com/InternLM/InternLM-XComposer)🚅🎞️ | [**MiniCPM-[V1/V2/V2.5/V2.6]**](https://github.com/OpenBMB/MiniCPM-V)🚅🎞️ | [**OmniLMM-12B**](https://huggingface.co/openbmb/OmniLMM-12B) | [**InternVL-Chat-[V1-1/V1-2/V1-5/V2]**](https://github.com/OpenGVLab/InternVL)🚅🎞️ |
|
| 129 |
+
| [**DeepSeek-VL**](https://github.com/deepseek-ai/DeepSeek-VL/tree/main)🎞️ | [**LLaVA-NeXT**](https://llava-vl.github.io/blog/2024-01-30-llava-next/)🚅🎞️ | [**Bunny-Llama3**](https://huggingface.co/BAAI/Bunny-v1_1-Llama-3-8B-V)🚅 | [**XVERSE-V-13B**](https://github.com/xverse-ai/XVERSE-V-13B/blob/main/vxverse/models/vxverse.py) |
|
| 130 |
+
| [**PaliGemma-3B**](https://huggingface.co/google/paligemma-3b-pt-448) 🚅 | [**360VL-70B**](https://huggingface.co/qihoo360/360VL-70B) 🚅 | [**Phi-3-Vision**](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)🚅🎞️<br>[**Phi-3.5-Vision**](https://huggingface.co/microsoft/Phi-3.5-vision-instruct)🚅🎞️ | [**WeMM**](https://github.com/scenarios/WeMM)🚅 |
|
| 131 |
+
| [**GLM-4v-9B**](https://huggingface.co/THUDM/glm-4v-9b) 🚅 | [**Cambrian-[8B/13B/34B]**](https://cambrian-mllm.github.io/) | [**LLaVA-Next-[Qwen-32B]**](https://huggingface.co/lmms-lab/llava-next-qwen-32b) 🎞️ | [**Chameleon-[7B/30B]**](https://huggingface.co/facebook/chameleon-7b)🚅🎞️ |
|
| 132 |
+
| [**Video-LLaVA-7B-[HF]**](https://github.com/PKU-YuanGroup/Video-LLaVA) 🎬 | [**VILA1.5-[3B/8B/13B/40B]**](https://github.com/NVlabs/VILA/)🎞️ | [**Ovis[1.5-Llama3-8B/1.5-Gemma2-9B/1.6-Gemma2-9B/1.6-Llama3.2-3B/1.6-Gemma2-27B]**](https://github.com/AIDC-AI/Ovis) 🚅🎞️ | [**Mantis-8B-[siglip-llama3/clip-llama3/Idefics2/Fuyu]**](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) 🎞️ |
|
| 133 |
+
| [**Llama-3-MixSenseV1_1**](https://huggingface.co/Zero-Vision/Llama-3-MixSenseV1_1)🚅 | [**Parrot-7B**](https://github.com/AIDC-AI/Parrot) 🚅 | [**OmChat-v2.0-13B-sinlge-beta**](https://huggingface.co/omlab/omchat-v2.0-13B-single-beta_hf) 🚅 | [**Video-ChatGPT**](https://github.com/mbzuai-oryx/Video-ChatGPT) 🎬 |
|
| 134 |
+
| [**Chat-UniVi-7B[-v1.5]**](https://github.com/PKU-YuanGroup/Chat-UniVi) 🎬 | [**LLaMA-VID-7B**](https://github.com/dvlab-research/LLaMA-VID) 🎬 | [**VideoChat2-HD**](https://huggingface.co/OpenGVLab/VideoChat2_HD_stage4_Mistral_7B) 🎬 | [**PLLaVA-[7B/13B/34B]**](https://huggingface.co/ermu2001/pllava-7b) 🎬 |
|
| 135 |
+
| [**RBDash_72b**](https://github.com/RBDash-Team/RBDash) 🚅🎞️ | [**xgen-mm-phi3-[interleave/dpo]-r-v1.5**](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-interleave-r-v1.5) 🚅🎞️ | [**Qwen2-VL-[2B/7B/72B]**](https://github.com/QwenLM/Qwen2-VL)🚅🎞️ | [**slime_[7b/8b/13b]**](https://github.com/yfzhang114/SliME)🎞️ |
|
| 136 |
+
| [**Eagle-X4-[8B/13B]**](https://github.com/NVlabs/EAGLE)🚅🎞️, <br>[**Eagle-X5-[7B/13B/34B]**](https://github.com/NVlabs/EAGLE)🚅🎞️ | [**Moondream1**](https://github.com/vikhyat/moondream)🚅, <br>[**Moondream2**](https://github.com/vikhyat/moondream)🚅 | [**XinYuan-VL-2B-Instruct**](https://huggingface.co/Cylingo/Xinyuan-VL-2B)🚅🎞️ | [**Llama-3.2-[11B/90B]-Vision-Instruct**](https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct)🚅 |
|
| 137 |
+
| [**Kosmos2**](https://huggingface.co/microsoft/kosmos-2-patch14-224)🚅 | [**H2OVL-Mississippi-[0.8B/2B]**](https://huggingface.co/h2oai/h2ovl-mississippi-2b)🚅🎞️ | **[Pixtral-12B](https://huggingface.co/mistralai/Pixtral-12B-2409)**🎞️ | **[Falcon2-VLM-11B](https://huggingface.co/tiiuae/falcon-11B-vlm)**🚅 |
|
| 138 |
+
| **[MiniMonkey](https://huggingface.co/mx262/MiniMonkey)**🚅🎞️ | **[LLaVA-OneVision](https://huggingface.co/lmms-lab/llava-onevision-qwen2-72b-ov-sft)**🚅🎞️ | **[LLaVA-Video](https://huggingface.co/collections/lmms-lab/llava-video-661e86f5e8dabc3ff793c944)**🚅🎞️ | **[Aquila-VL-2B](https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen)**🚅🎞️ |
|
| 139 |
+
| [**Mini-InternVL-Chat-[2B/4B]-V1-5**](https://github.com/OpenGVLab/InternVL)🚅🎞️ | **[InternVL2 Series](https://huggingface.co/OpenGVLab/InternVL2-8B)** 🚅🎞️ | **[Janus-1.3B](https://huggingface.co/deepseek-ai/Janus-1.3B)**🚅🎞️ | **[molmoE-1B/molmo-7B/molmo-72B](https://huggingface.co/allenai/Molmo-7B-D-0924)**🚅 |
|
| 140 |
+
| **[Points-[Yi-1.5-9B/Qwen-2.5-7B]](https://huggingface.co/WePOINTS/POINTS-Yi-1-5-9B-Chat)**🚅 | **[NVLM](https://huggingface.co/nvidia/NVLM-D-72B)**🚅 | **[VIntern](https://huggingface.co/5CD-AI/Vintern-3B-beta)**🚅🎞️ | **[Aria](https://huggingface.co/rhymes-ai/Aria)**🚅🎞️ |
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
🎞️: Support multiple images as inputs.
|
| 144 |
+
|
| 145 |
+
🚅: Models can be used without any additional configuration/operation.
|
| 146 |
+
|
| 147 |
+
🎬: Support Video as inputs.
|
| 148 |
+
|
| 149 |
+
**Transformers Version Recommendation:**
|
| 150 |
+
|
| 151 |
+
Note that some VLMs may not be able to run under certain transformer versions, we recommend the following settings to evaluate each VLM:
|
| 152 |
+
|
| 153 |
+
- **Please use** `transformers==4.33.0` **for**: `Qwen series`, `Monkey series`, `InternLM-XComposer Series`, `mPLUG-Owl2`, `OpenFlamingo v2`, `IDEFICS series`, `VisualGLM`, `MMAlaya`, `ShareCaptioner`, `MiniGPT-4 series`, `InstructBLIP series`, `PandaGPT`, `VXVERSE`.
|
| 154 |
+
- **Please use** `transformers==4.36.2` **for**: `Moondream1`.
|
| 155 |
+
- **Please use** `transformers==4.37.0` **for**: `LLaVA series`, `ShareGPT4V series`, `TransCore-M`, `LLaVA (XTuner)`, `CogVLM Series`, `EMU2 Series`, `Yi-VL Series`, `MiniCPM-[V1/V2]`, `OmniLMM-12B`, `DeepSeek-VL series`, `InternVL series`, `Cambrian Series`, `VILA Series`, `Llama-3-MixSenseV1_1`, `Parrot-7B`, `PLLaVA Series`.
|
| 156 |
+
- **Please use** `transformers==4.40.0` **for**: `IDEFICS2`, `Bunny-Llama3`, `MiniCPM-Llama3-V2.5`, `360VL-70B`, `Phi-3-Vision`, `WeMM`.
|
| 157 |
+
- **Please use** `transformers==4.44.0` **for**: `Moondream2`, `H2OVL series`.
|
| 158 |
+
- **Please use** `transformers==4.45.0` **for**: `Aria`.
|
| 159 |
+
- **Please use** `transformers==latest` **for**: `LLaVA-Next series`, `PaliGemma-3B`, `Chameleon series`, `Video-LLaVA-7B-HF`, `Ovis series`, `Mantis series`, `MiniCPM-V2.6`, `OmChat-v2.0-13B-sinlge-beta`, `Idefics-3`, `GLM-4v-9B`, `VideoChat2-HD`, `RBDash_72b`, `Llama-3.2 series`, `Kosmos series`.
|
| 160 |
+
|
| 161 |
+
**Torchvision Version Recommendation:**
|
| 162 |
+
|
| 163 |
+
Note that some VLMs may not be able to run under certain torchvision versions, we recommend the following settings to evaluate each VLM:
|
| 164 |
+
|
| 165 |
+
- **Please use** `torchvision>=0.16` **for**: `Moondream series` and `Aria`
|
| 166 |
+
|
| 167 |
+
**Flash-attn Version Recommendation:**
|
| 168 |
+
|
| 169 |
+
Note that some VLMs may not be able to run under certain flash-attention versions, we recommend the following settings to evaluate each VLM:
|
| 170 |
+
|
| 171 |
+
- **Please use** `pip install flash-attn --no-build-isolation` **for**: `Aria`
|
| 172 |
+
|
| 173 |
+
```python
|
| 174 |
+
# Demo
|
| 175 |
+
from vlmeval.config import supported_VLM
|
| 176 |
+
model = supported_VLM['idefics_9b_instruct']()
|
| 177 |
+
# Forward Single Image
|
| 178 |
+
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
|
| 179 |
+
print(ret) # The image features a red apple with a leaf on it.
|
| 180 |
+
# Forward Multiple Images
|
| 181 |
+
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
|
| 182 |
+
print(ret) # There are two apples in the provided images.
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
## 🛠️ Development Guide
|
| 186 |
+
|
| 187 |
+
To develop custom benchmarks, VLMs, or simply contribute other codes to **VLMEvalKit**, please refer to [[Development_Guide](/docs/en/Development.md) | [开发指南](/docs/zh-CN/Development.md)].
|
| 188 |
+
|
| 189 |
+
**Call for contributions**
|
| 190 |
+
|
| 191 |
+
To promote the contribution from the community and share the corresponding credit (in the next report update):
|
| 192 |
+
|
| 193 |
+
- All Contributions will be acknowledged in the report.
|
| 194 |
+
- Contributors with 3 or more major contributions (implementing an MLLM, benchmark, or major feature) can join the author list of [VLMEvalKit Technical Report](https://www.arxiv.org/abs/2407.11691) on ArXiv. Eligible contributors can create an issue or dm kennyutc in [VLMEvalKit Discord Channel](https://discord.com/invite/evDT4GZmxN).
|
| 195 |
+
|
| 196 |
+
Here is a [contributor list](/docs/en/Contributors.md) we curated based on the records.
|
| 197 |
+
|
| 198 |
+
## 🎯 The Goal of VLMEvalKit
|
| 199 |
+
|
| 200 |
+
**The codebase is designed to:**
|
| 201 |
+
|
| 202 |
+
1. Provide an **easy-to-use**, **opensource evaluation toolkit** to make it convenient for researchers & developers to evaluate existing LVLMs and make evaluation results **easy to reproduce**.
|
| 203 |
+
2. Make it easy for VLM developers to evaluate their own models. To evaluate the VLM on multiple supported benchmarks, one just need to **implement a single `generate_inner()` function**, all other workloads (data downloading, data preprocessing, prediction inference, metric calculation) are handled by the codebase.
|
| 204 |
+
|
| 205 |
+
**The codebase is not designed to:**
|
| 206 |
+
|
| 207 |
+
1. Reproduce the exact accuracy number reported in the original papers of all **3rd party benchmarks**. The reason can be two-fold:
|
| 208 |
+
1. VLMEvalKit uses **generation-based evaluation** for all VLMs (and optionally with **LLM-based answer extraction**). Meanwhile, some benchmarks may use different approaches (SEEDBench uses PPL-based evaluation, *eg.*). For those benchmarks, we compare both scores in the corresponding result. We encourage developers to support other evaluation paradigms in the codebase.
|
| 209 |
+
2. By default, we use the same prompt template for all VLMs to evaluate on a benchmark. Meanwhile, **some VLMs may have their specific prompt templates** (some may not covered by the codebase at this time). We encourage VLM developers to implement their own prompt template in VLMEvalKit, if that is not covered currently. That will help to improve the reproducibility.
|
| 210 |
+
|
| 211 |
+
## 🖊️ Citation
|
| 212 |
+
|
| 213 |
+
If you find this work helpful, please consider to **star🌟** this repo. Thanks for your support!
|
| 214 |
+
|
| 215 |
+
[](https://github.com/open-compass/VLMEvalKit/stargazers)
|
| 216 |
+
|
| 217 |
+
If you use VLMEvalKit in your research or wish to refer to published OpenSource evaluation results, please use the following BibTeX entry and the BibTex entry corresponding to the specific VLM / benchmark you used.
|
| 218 |
+
|
| 219 |
+
```bib
|
| 220 |
+
@misc{duan2024vlmevalkit,
|
| 221 |
+
title={VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models},
|
| 222 |
+
author={Haodong Duan and Junming Yang and Yuxuan Qiao and Xinyu Fang and Lin Chen and Yuan Liu and Xiaoyi Dong and Yuhang Zang and Pan Zhang and Jiaqi Wang and Dahua Lin and Kai Chen},
|
| 223 |
+
year={2024},
|
| 224 |
+
eprint={2407.11691},
|
| 225 |
+
archivePrefix={arXiv},
|
| 226 |
+
primaryClass={cs.CV},
|
| 227 |
+
url={https://arxiv.org/abs/2407.11691},
|
| 228 |
+
}
|
| 229 |
+
```
|
| 230 |
+
|
| 231 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 232 |
+
|
| 233 |
+
[github-contributors-link]: https://github.com/open-compass/VLMEvalKit/graphs/contributors
|
| 234 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/VLMEvalKit?color=c4f042&labelColor=black&style=flat-square
|
| 235 |
+
[github-forks-link]: https://github.com/open-compass/VLMEvalKit/network/members
|
| 236 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/VLMEvalKit?color=8ae8ff&labelColor=black&style=flat-square
|
| 237 |
+
[github-issues-link]: https://github.com/open-compass/VLMEvalKit/issues
|
| 238 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/VLMEvalKit?color=ff80eb&labelColor=black&style=flat-square
|
| 239 |
+
[github-license-link]: https://github.com/open-compass/VLMEvalKit/blob/main/LICENSE
|
| 240 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/VLMEvalKit?color=white&labelColor=black&style=flat-square
|
| 241 |
+
[github-stars-link]: https://github.com/open-compass/VLMEvalKit/stargazers
|
| 242 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/VLMEvalKit?color=ffcb47&labelColor=black&style=flat-square
|
assets/LOGO.svg
ADDED
|
|
assets/apple.jpg
ADDED

|
docs/en/.readthedocs.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2
|
| 2 |
+
|
| 3 |
+
# Set the version of Python and other tools you might need
|
| 4 |
+
build:
|
| 5 |
+
os: ubuntu-22.04
|
| 6 |
+
tools:
|
| 7 |
+
python: "3.8"
|
| 8 |
+
|
| 9 |
+
formats:
|
| 10 |
+
- epub
|
| 11 |
+
|
| 12 |
+
sphinx:
|
| 13 |
+
configuration: docs/en/conf.py
|
| 14 |
+
|
| 15 |
+
python:
|
| 16 |
+
install:
|
| 17 |
+
- requirements: requirements/docs.txt
|
docs/en/ConfigSystem.md
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Config System
|
| 2 |
+
|
| 3 |
+
By default, VLMEvalKit launches the evaluation by setting the model name(s) (defined in `/vlmeval/config.py`) and dataset name(s) (defined in `vlmeval/dataset/__init__.py`) in the `run.py` script with the `--model` and `--data` arguments. Such approach is simple and efficient in most scenarios, however, it may not be flexible enough when the user wants to evaluate multiple models / datasets with different settings.
|
| 4 |
+
|
| 5 |
+
To address this, VLMEvalKit provides a more flexible config system. The user can specify the model and dataset settings in a json file, and pass the path to the config file to the `run.py` script with the `--config` argument. Here is a sample config json:
|
| 6 |
+
|
| 7 |
+
```json
|
| 8 |
+
{
|
| 9 |
+
"model": {
|
| 10 |
+
"GPT4o_20240806_T00_HIGH": {
|
| 11 |
+
"class": "GPT4V",
|
| 12 |
+
"model": "gpt-4o-2024-08-06",
|
| 13 |
+
"temperature": 0,
|
| 14 |
+
"img_detail": "high"
|
| 15 |
+
},
|
| 16 |
+
"GPT4o_20240806_T10_Low": {
|
| 17 |
+
"class": "GPT4V",
|
| 18 |
+
"model": "gpt-4o-2024-08-06",
|
| 19 |
+
"temperature": 1.0,
|
| 20 |
+
"img_detail": "low"
|
| 21 |
+
}
|
| 22 |
+
},
|
| 23 |
+
"data": {
|
| 24 |
+
"MME-RealWorld-Lite": {
|
| 25 |
+
"class": "MMERealWorld",
|
| 26 |
+
"dataset": "MME-RealWorld-Lite"
|
| 27 |
+
},
|
| 28 |
+
"MMBench_DEV_EN_V11": {
|
| 29 |
+
"class": "ImageMCQDataset",
|
| 30 |
+
"dataset": "MMBench_DEV_EN_V11"
|
| 31 |
+
}
|
| 32 |
+
}
|
| 33 |
+
}
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Explanation of the config json:
|
| 37 |
+
|
| 38 |
+
1. Now we support two fields: `model` and `data`, each of which is a dictionary. The key of the dictionary is the name of the model / dataset (set by the user), and the value is the setting of the model / dataset.
|
| 39 |
+
2. For items in `model`, the value is a dictionary containing the following keys:
|
| 40 |
+
- `class`: The class name of the model, which should be a class name defined in `vlmeval/vlm/__init__.py` (open-source models) or `vlmeval/api/__init__.py` (API models).
|
| 41 |
+
- Other kwargs: Other kwargs are model-specific parameters, please refer to the definition of the model class for detailed usage. For example, `model`, `temperature`, `img_detail` are arguments of the `GPT4V` class. It's noteworthy that the `model` argument is required by most model classes.
|
| 42 |
+
3. For the dictionary `data`, we suggest users to use the official dataset name as the key (or part of the key), since we frequently determine the post-processing / judging settings based on the dataset name. For items in `data`, the value is a dictionary containing the following keys:
|
| 43 |
+
- `class`: The class name of the dataset, which should be a class name defined in `vlmeval/dataset/__init__.py`.
|
| 44 |
+
- Other kwargs: Other kwargs are dataset-specific parameters, please refer to the definition of the dataset class for detailed usage. Typically, the `dataset` argument is required by most dataset classes.
|
| 45 |
+
|
| 46 |
+
Saving the example config json to `config.json`, you can launch the evaluation by:
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
python run.py --config config.json
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
That will generate the following output files under the working directory `$WORK_DIR` (Following the format `{$WORK_DIR}/{$MODEL_NAME}/{$MODEL_NAME}_{$DATASET_NAME}_*`):
|
| 53 |
+
|
| 54 |
+
- `$WORK_DIR/GPT4o_20240806_T00_HIGH/GPT4o_20240806_T00_HIGH_MME-RealWorld-Lite*`
|
| 55 |
+
- `$WORK_DIR/GPT4o_20240806_T10_Low/GPT4o_20240806_T10_Low_MME-RealWorld-Lite*`
|
| 56 |
+
- `$WORK_DIR/GPT4o_20240806_T00_HIGH/GPT4o_20240806_T00_HIGH_MMBench_DEV_EN_V11*`
|
| 57 |
+
- `$WORK_DIR/GPT4o_20240806_T10_Low/GPT4o_20240806_T10_Low_MMBench_DEV_EN_V11*`
|
docs/en/Contributors.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributors
|
| 2 |
+
|
| 3 |
+
## Contributors w. 3+ Major Contributions
|
| 4 |
+
|
| 5 |
+
> In this section, we list all the contributors who have made significant contributions (3+) to the development of VLMEvalKit.
|
| 6 |
+
|
| 7 |
+
New Qualified Contributors (2024.09):
|
| 8 |
+
|
| 9 |
+
1. [amitbcp](https://github.com/amitbcp): The contributor helped support MUIRBench, Phi-3.5, Idefics3, VILA, and xGen-MM
|
| 10 |
+
2. [czczup](https://github.com/czczup): The contributor helped support the InternVL Series (V1.5, Mini-InternVL, V2, etc.)
|
| 11 |
+
3. [DseidLi](https://github.com/DseidLi): The contributor helped support LLaVA-OneVision, GQA, and developed the readthedocs site for VLMEvalKit
|
| 12 |
+
4. [mayubo2333](https://github.com/mayubo2333): The contributor helped support MMLongBench, SlideVQA, and DUDE
|
| 13 |
+
5. [sun-hailong](https://github.com/sun-hailong): The contributor helped support A-OKVQA, Parrot, MMMB, and MTL-MMBench
|
| 14 |
+
6. [PhoenixZ810](https://github.com/PhoenixZ810): The contributor helped support Video-ChatGPT, Chat-UniVI, and Llama-VID
|
| 15 |
+
7. [Cuiunbo](https://github.com/Cuiunbo): The contributor helped support OmniLMM-12B, MiniCPM-V Series (V1, V2, V2.5)
|
| 16 |
+
|
| 17 |
+
## Full Contributor List
|
| 18 |
+
|
| 19 |
+
> In this section, we list all the contributors as well as their corresponding contributions to the development of VLMEvalKit.
|
| 20 |
+
|
| 21 |
+
TBD.
|
docs/en/Development.md
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Develop new Benchmark / MLLM
|
| 2 |
+
|
| 3 |
+
> 🛠️ How to implement a new Benchmark / VLM in VLMEvalKit?
|
| 4 |
+
|
| 5 |
+
## Implement a new benchmark
|
| 6 |
+
|
| 7 |
+
Example PR: **Math-Vision Benchmark** ([#292](https://github.com/open-compass/VLMEvalKit/pull/292/files))
|
| 8 |
+
|
| 9 |
+
In VLMEvalKit, benchmarks are organized as dataset classes. When you try to implement a new benchmark, you can either reuse existing dataset classes (*e.g.*, You can reuse `ImageMCQDataset` when implementing a new multi-choice benchmark), or support a new dataset class. Each dataset must have the following two member functions (either reuse the one of the parent class or implement your own):
|
| 10 |
+
|
| 11 |
+
- `build_prompt(self, line)`: The function input `line` is an integer (the sample index) or a `pd.Series` object (the raw record of the sample). The function outputs a `multi-modal message`, serving as the input of an MLLM. The `multi-modal message` is an interleaved list of multi-modal messages adopting the following format (the example includes an image and a text message): `[dict(type='image', value=IMAGE_PTH), dict(type='text', value=prompt)]`.
|
| 12 |
+
- `evaluate(self, eval_file, **judge_kwargs)`: The function input `eval_file` is the MLLM prediction (typically in `.xlsx` format). If the benchmark requires an external LLM (typically GPT) for evaluation, then `judge_kwargs` can pass the arguments for the LLM. The function outputs the benchmark evaluation results (metrics) in the form of `dict` or `pd.DataFrame`.
|
| 13 |
+
|
| 14 |
+
We then brief the typical steps to implement a new benchmark under VLMEvalKit:
|
| 15 |
+
|
| 16 |
+
### 1. Prepare your benchmark tsv file
|
| 17 |
+
|
| 18 |
+
Currently, we organize a benchmark as one single TSV file. During inference, the data file will be automatically downloaded from the definited `DATASET_URL` link to `$LMUData` file (default path is `$HOME/LMUData`, if not set explicitly). You can upload the prepared TSV file to a downloadable address (e.g., Huggingface) or send it to us at <opencompass@pjlab.org.cn>. We will assist in uploading the dataset to the server. You can also customize `LMUData` path in the environment variable `LMUData=/path/to/your/data`.
|
| 19 |
+
|
| 20 |
+
The contents of the TSV file consist of:
|
| 21 |
+
|
| 22 |
+
| Dataset Name \ Fields | index | image | image_path | question | hint | multi-choice<br>options | answer | category | l2-category | split |
|
| 23 |
+
| --------------------------------------- | ----- | ----- | ---------- | -------- | ---- | ----------------------- | ------ | -------- | ----------- | ----- |
|
| 24 |
+
| MMBench_DEV_[CN/EN] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 25 |
+
| MMBench_TEST_[CN/EN] | ✅ | ✅ | | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ |
|
| 26 |
+
| CCBench | ✅ | ✅ | | ✅ | | ✅ | ✅ | ✅ | | |
|
| 27 |
+
| SEEDBench_IMG | ✅ | ✅ | | ✅ | | ✅ | ✅ | ✅ | | |
|
| 28 |
+
| MME | ✅ | ✅ | | ✅ | | | ✅ | ✅ | | |
|
| 29 |
+
| CORE_MM | ✅ | ✅ | ✅ | ✅ | | | | ✅ | | |
|
| 30 |
+
| MMVet | ✅ | ✅ | | ✅ | | | ✅ | ✅ | | |
|
| 31 |
+
| MMMU_DEV_VAL | ✅ | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 32 |
+
| COCO_VAL | ✅ | ✅ | | | | | ✅ | | | |
|
| 33 |
+
| OCRVQA_[TEST/TESTCORE] | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 34 |
+
| TextVQA_VAL | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 35 |
+
| VCR_[EN/ZH]\_[EASY/HARD]\_[ALL/500/100] | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 36 |
+
| MMMB_[en/cn/pt/ar/tr/ru] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | |✅ |
|
| 37 |
+
| MMBench_dev_[en/cn/pt/ar/tr/ru] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |✅ |
|
| 38 |
+
|
| 39 |
+
<div align="center"><b>Table 1. TSV fields of supported datasets.</b></div>
|
| 40 |
+
|
| 41 |
+
**Intro to mandatory fields in the `TSV` file:**
|
| 42 |
+
|
| 43 |
+
- **index:** Integer, Unique for each line in `tsv`
|
| 44 |
+
- **image:** The base64 of the image, you can use APIs implemented in `vlmeval/smp/vlm.py` for encoding and decoding:
|
| 45 |
+
- Encoding: `encode_image_to_base64 `(for PIL Image) / `encode_image_file_to_base64` (for image file path)
|
| 46 |
+
- Decoding: `decode_base64_to_image`(for PIL Image) / `decode_base64_to_image_file` (for image file path)
|
| 47 |
+
- **question**: The question corresponding to the image, a string
|
| 48 |
+
- **answer**: The answer to the question, a string. The `test` split does not need this field
|
| 49 |
+
|
| 50 |
+
### 2. Cutomize your benchmark prompt
|
| 51 |
+
|
| 52 |
+
`ImageBaseDataset` defines the default prompt format. If you need to add prompts specific to the dataset or input data in the `Interleave` format to the model, you can implement this through the `build_prompt(line)` function. This function takes a line from a TSV file as input, containing fields such as index, image, question, etc. The function returns a dictionary list of multimodal messages `msg` in the format `[dict(type='image', value=IMAGE_PTH), dict(type='text', value=prompt)]`, including the image path and the text prompt to be input into VLMs. For interleave type inputs, you can directly place the dictionary of the image path at the image token position.
|
| 53 |
+
|
| 54 |
+
### 3. Cutomize your benchmark metrics
|
| 55 |
+
|
| 56 |
+
To add evaluation for a new benchmark, you need to customize a class object to implement the dataset’s metrics calculation. Multimodal datasets inherit from the `ImageBaseDataset` object in `vlmeval/dataset/image_base.py`. The TYPE defines the type of dataset, `DATASET_URL` is the download address of the dataset, and `DATASET_MD5` is the MD5 checksum for consistency checking of the dataset file.
|
| 57 |
+
|
| 58 |
+
In this class, **you need to implement** the `evaluate(eval_file, **judge_kwargs)` class function to calculate metrics and output results for the custom dataset. The function input `eval_file` is the path to the model prediction results file `{model_name}_{dataset}.xlsx`. This file can be read as a pandas.DataFrame using the `load(eval_file)` method, containing fields such as index, question, answer, category, prediction, etc. The judge_kwargs will pass a dictionary related to evaluation, such as the name of the `judge model`, the number of API request threads, etc. **The return value** of the function is the calculated accuracy and other metrics, formatted as a dictionary composed of lists, organized into a pandas.DataFrame.
|
| 59 |
+
|
| 60 |
+
## Implement a new model
|
| 61 |
+
|
| 62 |
+
Example PR: **Support LLaVA-Next-Interleave** ([#294](https://github.com/open-compass/VLMEvalKit/pull/294))
|
| 63 |
+
|
| 64 |
+
**1. Support `generate_inner` API (mandatory).**
|
| 65 |
+
|
| 66 |
+
All existing models are implemented in `vlmeval/vlm`. For a minimal model, your model class **must implement the method** `generate_inner(msgs, dataset=None)`. In this function, you feed a multi-modal message to your VLM and return the VLM prediction (which is a string). The optional argument `dataset` can be used as the flag for the model to switch among various inference strategies.
|
| 67 |
+
|
| 68 |
+
The multi-modal messages `msgs` is a list of dictionaries, each dictionary has two keys: type and value:
|
| 69 |
+
- `type`: We currently support two types, choices are ["image", "text"].
|
| 70 |
+
- `value`: When type=='text' , the value is the text message (a single string); when type=='image', the value can be the local path of an image file, or the image URL.
|
| 71 |
+
|
| 72 |
+
Currently a multi-modal message may contain arbitrarily interleaved images and texts. If your model do not support that, a practice can be taking the 1st image and concatenated text messages as the input. You can set the `INTERLEAVE = False` in your model class and use `self.message_to_promptimg(message, dataset=dataset)` to build your prompt and the first image's path.
|
| 73 |
+
|
| 74 |
+
Here are some examples of multi-modal messages:
|
| 75 |
+
|
| 76 |
+
```python
|
| 77 |
+
IMAGE_PTH = 'assets/apple.jpg'
|
| 78 |
+
IMAGE_URL = 'https://raw.githubusercontent.com/open-compass/VLMEvalKit/main/assets/apple.jpg'
|
| 79 |
+
msg1 = [
|
| 80 |
+
dict(type='image', value=IMAGE_PTH),
|
| 81 |
+
dict(type='text', value='What is in this image?')
|
| 82 |
+
]
|
| 83 |
+
msg2 = [
|
| 84 |
+
dict(type='image', value=IMAGE_URL),
|
| 85 |
+
dict(type='image', value=IMAGE_URL),
|
| 86 |
+
dict(type='text', value='How many apples are there in these images?')
|
| 87 |
+
]
|
| 88 |
+
response = model.generate(msg1)
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
For convenience sake, we also support to take a list of string as inputs. In that case, we will check if a string is an image path or image URL and automatically convert it to the list[dict] format:
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
IMAGE_PTH = 'assets/apple.jpg'
|
| 95 |
+
IMAGE_URL = 'https://raw.githubusercontent.com/open-compass/VLMEvalKit/main/assets/apple.jpg'
|
| 96 |
+
msg1 = [IMAGE_PTH, 'What is in this image?']
|
| 97 |
+
msg2 = [IMAGE_URL, IMAGE_URL, 'How many apples are there in these images?']
|
| 98 |
+
response = model.generate(msg1)
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
**Support Custom Prompt (optional).**
|
| 102 |
+
|
| 103 |
+
Besides, your model can support **custom prompt building** by implementing two optional methods: `use_custom_prompt(dataset)` and `build_prompt(line, dataset=None)`.
|
| 104 |
+
|
| 105 |
+
Both functions take the dataset name as the input:
|
| 106 |
+
|
| 107 |
+
- `use_custom_prompt(dataset)` returns a boolean flag, indicating whether the model should use the custom prompt building strategy.
|
| 108 |
+
- If `use_custom_prompt(dataset)` returns True, `build_prompt(line, dataset)` should return a customly bulit multimodal message for the corresponding `dataset`, given `line`, which is a dictionary that includes the necessary information of a data sample. If `use_custom_prompt(dataset)` returns False, the default prompt building strategy will be used.
|
| 109 |
+
|
| 110 |
+
**Support multi-turn chatting (optional).**
|
| 111 |
+
|
| 112 |
+
You can also support the multi-turn chatting and evaluation with your VLM by supporting the `chat_inner(message, dataset)` function. The function outputs a single string response, and the `message` is a list of chat history, following the below format.
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
# Assume msg1, msg2, msg3, ... are multi-modal messages following the previously described format
|
| 116 |
+
# `chat_inner` take the following chat history list as input:
|
| 117 |
+
message = [
|
| 118 |
+
dict(role='user', content=msg1),
|
| 119 |
+
dict(role='assistant', content=msg2),
|
| 120 |
+
dict(role='user', content=msg3),
|
| 121 |
+
dict(role='assistant', content=msg4),
|
| 122 |
+
......
|
| 123 |
+
dict(role='user', content=msgn),
|
| 124 |
+
]
|
| 125 |
+
# `message` should contain an odd number of chat utterances, the role of utterances should be interleaved "user" and "assistant", with the role of the last utterance to be "user".
|
| 126 |
+
# The chat function will call `chat_inner`
|
| 127 |
+
response = model.chat(message)
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
### Example PRs:
|
| 131 |
+
|
| 132 |
+
- VLM that doesn't support interleaved images and texts, and does not use custom prompts: [[Model] Support glm-4v-9b](https://github.com/open-compass/VLMEvalKit/pull/221)
|
| 133 |
+
- VLM that supports interleaved images and texts and custom prompts: [Add MiniCPM-Llama3-V-2.5](https://github.com/open-compass/VLMEvalKit/pull/205)
|
| 134 |
+
- VLM API: [Feature add glmv](https://github.com/open-compass/VLMEvalKit/pull/201)
|
| 135 |
+
|
| 136 |
+
## Contribute to VLMEvalKit
|
| 137 |
+
|
| 138 |
+
If you want to contribute codes to **VLMEvalKit**, please do the pre-commit check before you submit a PR. That helps to keep the code tidy.
|
| 139 |
+
|
| 140 |
+
```bash
|
| 141 |
+
# Under the directory of VLMEvalKit, install the pre-commit hook:
|
| 142 |
+
pip install pre-commit
|
| 143 |
+
pre-commit install
|
| 144 |
+
pre-commit run --all-files
|
| 145 |
+
# Then you can commit your code.
|
| 146 |
+
```
|
docs/en/Makefile
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SOURCEDIR = .
|
| 9 |
+
BUILDDIR = _build
|
| 10 |
+
|
| 11 |
+
# Put it first so that "make" without argument is like "make help".
|
| 12 |
+
help:
|
| 13 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 14 |
+
|
| 15 |
+
.PHONY: help Makefile
|
| 16 |
+
|
| 17 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 18 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 19 |
+
%: Makefile
|
| 20 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
docs/en/Quickstart.md
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Quickstart
|
| 2 |
+
|
| 3 |
+
Before running the evaluation script, you need to **configure** the VLMs and set the model_paths properly.
|
| 4 |
+
|
| 5 |
+
After that, you can use a single script `run.py` to inference and evaluate multiple VLMs and benchmarks at a same time.
|
| 6 |
+
|
| 7 |
+
## Step 0. Installation & Setup essential keys
|
| 8 |
+
|
| 9 |
+
**Installation.**
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
git clone https://github.com/open-compass/VLMEvalKit.git
|
| 13 |
+
cd VLMEvalKit
|
| 14 |
+
pip install -e .
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
**Setup Keys.**
|
| 18 |
+
|
| 19 |
+
To infer with API models (GPT-4v, Gemini-Pro-V, etc.) or use LLM APIs as the **judge or choice extractor**, you need to first setup API keys. VLMEvalKit will use an judge **LLM** to extract answer from the output if you set the key, otherwise it uses the **exact matching** mode (find "Yes", "No", "A", "B", "C"... in the output strings). **The exact matching can only be applied to the Yes-or-No tasks and the Multi-choice tasks.**
|
| 20 |
+
- You can place the required keys in `$VLMEvalKit/.env` or directly set them as the environment variable. If you choose to create a `.env` file, its content will look like:
|
| 21 |
+
|
| 22 |
+
```bash
|
| 23 |
+
# The .env file, place it under $VLMEvalKit
|
| 24 |
+
# API Keys of Proprietary VLMs
|
| 25 |
+
# QwenVL APIs
|
| 26 |
+
DASHSCOPE_API_KEY=
|
| 27 |
+
# Gemini w. Google Cloud Backends
|
| 28 |
+
GOOGLE_API_KEY=
|
| 29 |
+
# OpenAI API
|
| 30 |
+
OPENAI_API_KEY=
|
| 31 |
+
OPENAI_API_BASE=
|
| 32 |
+
# StepAI API
|
| 33 |
+
STEPAI_API_KEY=
|
| 34 |
+
# REKA API
|
| 35 |
+
REKA_API_KEY=
|
| 36 |
+
# GLMV API
|
| 37 |
+
GLMV_API_KEY=
|
| 38 |
+
# CongRong API
|
| 39 |
+
CW_API_BASE=
|
| 40 |
+
CW_API_KEY=
|
| 41 |
+
# SenseChat-V API
|
| 42 |
+
SENSECHAT_AK=
|
| 43 |
+
SENSECHAT_SK=
|
| 44 |
+
# Hunyuan-Vision API
|
| 45 |
+
HUNYUAN_SECRET_KEY=
|
| 46 |
+
HUNYUAN_SECRET_ID=
|
| 47 |
+
# You can also set a proxy for calling api models during the evaluation stage
|
| 48 |
+
EVAL_PROXY=
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
- Fill the blanks with your API keys (if necessary). Those API keys will be automatically loaded when doing the inference and evaluation.
|
| 52 |
+
## Step 1. Configuration
|
| 53 |
+
|
| 54 |
+
**VLM Configuration**: All VLMs are configured in `vlmeval/config.py`. Few legacy VLMs (like MiniGPT-4, LLaVA-v1-7B) requires additional configuration (configuring the code / model_weight root in the config file). During evaluation, you should use the model name specified in `supported_VLM` in `vlmeval/config.py` to select the VLM. Make sure you can successfully infer with the VLM before starting the evaluation with the following command `vlmutil check {MODEL_NAME}`.
|
| 55 |
+
|
| 56 |
+
## Step 2. Evaluation
|
| 57 |
+
|
| 58 |
+
**New!!!** We integrated a new config system to enable more flexible evaluation settings. Check the [Document](/docs/en/ConfigSystem.md) or run `python run.py --help` for more details 🔥🔥🔥
|
| 59 |
+
|
| 60 |
+
We use `run.py` for evaluation. To use the script, you can use `$VLMEvalKit/run.py` or create a soft-link of the script (to use the script anywhere):
|
| 61 |
+
|
| 62 |
+
**Arguments**
|
| 63 |
+
|
| 64 |
+
- `--data (list[str])`: Set the dataset names that are supported in VLMEvalKit (names can be found in the codebase README).
|
| 65 |
+
- `--model (list[str])`: Set the VLM names that are supported in VLMEvalKit (defined in `supported_VLM` in `vlmeval/config.py`).
|
| 66 |
+
- `--mode (str, default to 'all', choices are ['all', 'infer'])`: When `mode` set to "all", will perform both inference and evaluation; when set to "infer", will only perform the inference.
|
| 67 |
+
- `--nproc (int, default to 4)`: The number of threads for OpenAI API calling.
|
| 68 |
+
- `--work-dir (str, default to '.')`: The directory to save evaluation results.
|
| 69 |
+
- `--nframe (int, default to 8)`: The number of frames to sample from a video, only applicable to the evaluation of video benchmarks.
|
| 70 |
+
- `--pack (bool, store_true)`: A video may associate with multiple questions, if `pack==True`, will ask all questions for a video in a single query.
|
| 71 |
+
|
| 72 |
+
**Command for Evaluating Image Benchmarks **
|
| 73 |
+
|
| 74 |
+
You can run the script with `python` or `torchrun`:
|
| 75 |
+
|
| 76 |
+
```bash
|
| 77 |
+
# When running with `python`, only one VLM instance is instantiated, and it might use multiple GPUs (depending on its default behavior).
|
| 78 |
+
# That is recommended for evaluating very large VLMs (like IDEFICS-80B-Instruct).
|
| 79 |
+
|
| 80 |
+
# IDEFICS-80B-Instruct on MMBench_DEV_EN, MME, and SEEDBench_IMG, Inference and Evalution
|
| 81 |
+
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose
|
| 82 |
+
# IDEFICS-80B-Instruct on MMBench_DEV_EN, MME, and SEEDBench_IMG, Inference only
|
| 83 |
+
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose --mode infer
|
| 84 |
+
|
| 85 |
+
# When running with `torchrun`, one VLM instance is instantiated on each GPU. It can speed up the inference.
|
| 86 |
+
# However, that is only suitable for VLMs that consume small amounts of GPU memory.
|
| 87 |
+
|
| 88 |
+
# IDEFICS-9B-Instruct, Qwen-VL-Chat, mPLUG-Owl2 on MMBench_DEV_EN, MME, and SEEDBench_IMG. On a node with 8 GPU. Inference and Evaluation.
|
| 89 |
+
torchrun --nproc-per-node=8 run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct qwen_chat mPLUG-Owl2 --verbose
|
| 90 |
+
# Qwen-VL-Chat on MME. On a node with 2 GPU. Inference and Evaluation.
|
| 91 |
+
torchrun --nproc-per-node=2 run.py --data MME --model qwen_chat --verbose
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
**Command for Evaluating Video Benchmarks**
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
# When running with `python`, only one VLM instance is instantiated, and it might use multiple GPUs (depending on its default behavior).
|
| 98 |
+
# That is recommended for evaluating very large VLMs (like IDEFICS-80B-Instruct).
|
| 99 |
+
|
| 100 |
+
# IDEFICS2-8B on MMBench-Video, with 8 frames as inputs and vanilla evaluation. On a node with 8 GPUs.
|
| 101 |
+
torchrun --nproc-per-node=8 run.py --data MMBench-Video --model idefics2_8b --nframe 8
|
| 102 |
+
# GPT-4o (API model) on MMBench-Video, with 16 frames as inputs and pack evaluation (all questions of a video in a single query).
|
| 103 |
+
python run.py --data MMBench-Video --model GPT4o --nframe 16 --pack
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
The evaluation results will be printed as logs, besides. **Result Files** will also be generated in the directory `$YOUR_WORKING_DIRECTORY/{model_name}`. Files ending with `.csv` contain the evaluated metrics.
|
| 107 |
+
|
| 108 |
+
## Deploy a local language model as the judge / choice extractor
|
| 109 |
+
The default setting mentioned above uses OpenAI's GPT as the judge LLM. However, you can also deploy a local judge LLM with [LMDeploy](https://github.com/InternLM/lmdeploy).
|
| 110 |
+
|
| 111 |
+
First install:
|
| 112 |
+
```
|
| 113 |
+
pip install lmdeploy openai
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
And then deploy a local judge LLM with the single line of code. LMDeploy will automatically download the model from Huggingface. Assuming we use internlm2-chat-1_8b as the judge, port 23333, and the key sk-123456 (the key must start with "sk-" and follow with any number you like):
|
| 117 |
+
```
|
| 118 |
+
lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
You need to get the model name registered by LMDeploy with the following python code:
|
| 122 |
+
```
|
| 123 |
+
from openai import OpenAI
|
| 124 |
+
client = OpenAI(
|
| 125 |
+
api_key='sk-123456',
|
| 126 |
+
base_url="http://0.0.0.0:23333/v1"
|
| 127 |
+
)
|
| 128 |
+
model_name = client.models.list().data[0].id
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
Now set some environment variables to tell VLMEvalKit how to use the local judge LLM. As mentioned above, you can also set them in `$VLMEvalKit/.env` file:
|
| 132 |
+
```
|
| 133 |
+
OPENAI_API_KEY=sk-123456
|
| 134 |
+
OPENAI_API_BASE=http://0.0.0.0:23333/v1/chat/completions
|
| 135 |
+
LOCAL_LLM=<model_name you get>
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
Finally, you can run the commands in step 2 to evaluate your VLM with the local judge LLM.
|
| 139 |
+
|
| 140 |
+
Note that
|
| 141 |
+
|
| 142 |
+
- If you hope to deploy the judge LLM in a single GPU and evaluate your VLM on other GPUs because of limited GPU memory, try `CUDA_VISIBLE_DEVICES=x` like
|
| 143 |
+
```
|
| 144 |
+
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333
|
| 145 |
+
CUDA_VISIBLE_DEVICES=1,2,3 torchrun --nproc-per-node=3 run.py --data HallusionBench --model qwen_chat --verbose
|
| 146 |
+
```
|
| 147 |
+
- If the local judge LLM is not good enough in following the instructions, the evaluation may fail. Please report such failures (e.g., by issues).
|
| 148 |
+
- It's possible to deploy the judge LLM in different ways, e.g., use a private LLM (not from HuggingFace) or use a quantized LLM. Please refer to the [LMDeploy doc](https://lmdeploy.readthedocs.io/en/latest/serving/api_server.html). You can use any other deployment framework if they support OpenAI API.
|
docs/en/_static/css/readthedocs.css
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.header-logo {
|
| 2 |
+
background-image: url("../image/logo.svg");
|
| 3 |
+
background-size: 275px 80px;
|
| 4 |
+
height: 80px;
|
| 5 |
+
width: 275px;
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@media screen and (min-width: 1100px) {
|
| 10 |
+
.header-logo {
|
| 11 |
+
top: -25px;
|
| 12 |
+
}
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
pre {
|
| 16 |
+
white-space: pre;
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
@media screen and (min-width: 2000px) {
|
| 20 |
+
.pytorch-content-left {
|
| 21 |
+
width: 1200px;
|
| 22 |
+
margin-left: 30px;
|
| 23 |
+
}
|
| 24 |
+
article.pytorch-article {
|
| 25 |
+
max-width: 1200px;
|
| 26 |
+
}
|
| 27 |
+
.pytorch-breadcrumbs-wrapper {
|
| 28 |
+
width: 1200px;
|
| 29 |
+
}
|
| 30 |
+
.pytorch-right-menu.scrolling-fixed {
|
| 31 |
+
position: fixed;
|
| 32 |
+
top: 45px;
|
| 33 |
+
left: 1580px;
|
| 34 |
+
}
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
article.pytorch-article section code {
|
| 39 |
+
padding: .2em .4em;
|
| 40 |
+
background-color: #f3f4f7;
|
| 41 |
+
border-radius: 5px;
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
/* Disable the change in tables */
|
| 45 |
+
article.pytorch-article section table code {
|
| 46 |
+
padding: unset;
|
| 47 |
+
background-color: unset;
|
| 48 |
+
border-radius: unset;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
table.autosummary td {
|
| 52 |
+
width: 50%
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
img.align-center {
|
| 56 |
+
display: block;
|
| 57 |
+
margin-left: auto;
|
| 58 |
+
margin-right: auto;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
article.pytorch-article p.rubric {
|
| 62 |
+
font-weight: bold;
|
| 63 |
+
}
|
docs/en/_static/image/logo.svg
ADDED
|
|
docs/en/_static/image/logo_icon.svg
ADDED
|
|
docs/en/_static/js/custom.js
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
var collapsedSections = [];
|
| 2 |
+
|
| 3 |
+
$(document).ready(function () {
|
| 4 |
+
$('.model-summary').DataTable({
|
| 5 |
+
"stateSave": false,
|
| 6 |
+
"lengthChange": false,
|
| 7 |
+
"pageLength": 20,
|
| 8 |
+
"order": []
|
| 9 |
+
});
|
| 10 |
+
});
|
docs/en/_templates/404.html
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{% extends "layout.html" %}
|
| 2 |
+
|
| 3 |
+
{% block body %}
|
| 4 |
+
|
| 5 |
+
<h1>Page Not Found</h1>
|
| 6 |
+
<p>
|
| 7 |
+
The page you are looking for cannot be found.
|
| 8 |
+
</p>
|
| 9 |
+
<p>
|
| 10 |
+
If you just switched documentation versions, it is likely that the page you were on is moved. You can look for it in
|
| 11 |
+
the content table left, or go to <a href="{{ pathto(root_doc) }}">the homepage</a>.
|
| 12 |
+
</p>
|
| 13 |
+
<!-- <p>
|
| 14 |
+
If you cannot find documentation you want, please <a
|
| 15 |
+
href="">open an issue</a> to tell us!
|
| 16 |
+
</p> -->
|
| 17 |
+
|
| 18 |
+
{% endblock %}
|
docs/en/_templates/autosummary/class.rst
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
|
| 11 |
+
..
|
| 12 |
+
autogenerated from _templates/autosummary/class.rst
|
| 13 |
+
note it does not have :inherited-members:
|
docs/en/_templates/callable.rst
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
:special-members: __call__
|
| 11 |
+
|
| 12 |
+
..
|
| 13 |
+
autogenerated from _templates/callable.rst
|
| 14 |
+
note it does not have :inherited-members:
|
docs/en/conf.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
# Configuration file for the Sphinx documentation builder.
|
| 3 |
+
#
|
| 4 |
+
# This file only contains a selection of the most common options. For a full
|
| 5 |
+
# list see the documentation:
|
| 6 |
+
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
| 7 |
+
|
| 8 |
+
# -- Path setup --------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 11 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 12 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 13 |
+
#
|
| 14 |
+
import os
|
| 15 |
+
import ast
|
| 16 |
+
import subprocess
|
| 17 |
+
import sys
|
| 18 |
+
|
| 19 |
+
import pytorch_sphinx_theme
|
| 20 |
+
from sphinx.builders.html import StandaloneHTMLBuilder
|
| 21 |
+
|
| 22 |
+
sys.path.insert(0, os.path.abspath('../../'))
|
| 23 |
+
|
| 24 |
+
# -- Project information -----------------------------------------------------
|
| 25 |
+
|
| 26 |
+
project = 'VLMEvalKit'
|
| 27 |
+
copyright = '2023, VLMEvalKit'
|
| 28 |
+
author = 'VLMEvalKit Authors'
|
| 29 |
+
|
| 30 |
+
# The full version, including alpha/beta/rc tags
|
| 31 |
+
version_file = '../../vlmeval/__init__.py'
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_version():
|
| 35 |
+
with open(version_file, 'r') as f:
|
| 36 |
+
file_content = f.read()
|
| 37 |
+
# Parse the file content into an abstract syntax tree (AST)
|
| 38 |
+
tree = ast.parse(file_content, filename=version_file)
|
| 39 |
+
|
| 40 |
+
# Iterate through the body of the AST, looking for an assignment to __version__
|
| 41 |
+
for node in tree.body:
|
| 42 |
+
if isinstance(node, ast.Assign):
|
| 43 |
+
for target in node.targets:
|
| 44 |
+
if isinstance(target, ast.Name) and target.id == '__version__':
|
| 45 |
+
return node.value.s
|
| 46 |
+
raise ValueError('__version__ not found')
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
release = get_version()
|
| 50 |
+
|
| 51 |
+
# -- General configuration ---------------------------------------------------
|
| 52 |
+
|
| 53 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 54 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 55 |
+
# ones.
|
| 56 |
+
extensions = [
|
| 57 |
+
'sphinx.ext.autodoc',
|
| 58 |
+
'sphinx.ext.autosummary',
|
| 59 |
+
'sphinx.ext.intersphinx',
|
| 60 |
+
'sphinx.ext.napoleon',
|
| 61 |
+
'sphinx.ext.viewcode',
|
| 62 |
+
'myst_parser',
|
| 63 |
+
'sphinx_copybutton',
|
| 64 |
+
'sphinx_tabs.tabs',
|
| 65 |
+
'notfound.extension',
|
| 66 |
+
'sphinxcontrib.jquery',
|
| 67 |
+
'sphinx_design',
|
| 68 |
+
]
|
| 69 |
+
|
| 70 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 71 |
+
templates_path = ['_templates']
|
| 72 |
+
|
| 73 |
+
# The suffix(es) of source filenames.
|
| 74 |
+
# You can specify multiple suffix as a list of string:
|
| 75 |
+
#
|
| 76 |
+
source_suffix = {
|
| 77 |
+
'.rst': 'restructuredtext',
|
| 78 |
+
'.md': 'markdown',
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
language = 'en'
|
| 82 |
+
|
| 83 |
+
# The master toctree document.
|
| 84 |
+
root_doc = 'index'
|
| 85 |
+
html_context = {
|
| 86 |
+
'github_version': 'latest',
|
| 87 |
+
}
|
| 88 |
+
# List of patterns, relative to source directory, that match files and
|
| 89 |
+
# directories to ignore when looking for source files.
|
| 90 |
+
# This pattern also affects html_static_path and html_extra_path.
|
| 91 |
+
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
| 92 |
+
|
| 93 |
+
# -- Options for HTML output -------------------------------------------------
|
| 94 |
+
|
| 95 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 96 |
+
# a list of builtin themes.
|
| 97 |
+
#
|
| 98 |
+
html_theme = 'pytorch_sphinx_theme'
|
| 99 |
+
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
| 100 |
+
|
| 101 |
+
# Theme options are theme-specific and customize the look and feel of a theme
|
| 102 |
+
# further. For a list of options available for each theme, see the
|
| 103 |
+
# documentation.
|
| 104 |
+
# yapf: disable
|
| 105 |
+
html_theme_options = {
|
| 106 |
+
'menu': [
|
| 107 |
+
{
|
| 108 |
+
'name': 'GitHub',
|
| 109 |
+
'url': 'https://github.com/open-compass/VLMEvalKit'
|
| 110 |
+
},
|
| 111 |
+
],
|
| 112 |
+
# Specify the language of shared menu
|
| 113 |
+
'menu_lang': 'en',
|
| 114 |
+
# Disable the default edit on GitHub
|
| 115 |
+
'default_edit_on_github': False,
|
| 116 |
+
}
|
| 117 |
+
# yapf: enable
|
| 118 |
+
|
| 119 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 120 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 121 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 122 |
+
html_static_path = ['_static']
|
| 123 |
+
html_css_files = [
|
| 124 |
+
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.css',
|
| 125 |
+
'css/readthedocs.css'
|
| 126 |
+
]
|
| 127 |
+
html_js_files = [
|
| 128 |
+
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.js',
|
| 129 |
+
'js/custom.js'
|
| 130 |
+
]
|
| 131 |
+
|
| 132 |
+
# -- Options for HTMLHelp output ---------------------------------------------
|
| 133 |
+
|
| 134 |
+
# Output file base name for HTML help builder.
|
| 135 |
+
htmlhelp_basename = 'vlmevalkitdoc'
|
| 136 |
+
|
| 137 |
+
# -- Options for LaTeX output ------------------------------------------------
|
| 138 |
+
|
| 139 |
+
latex_elements = {
|
| 140 |
+
# The paper size ('letterpaper' or 'a4paper').
|
| 141 |
+
#
|
| 142 |
+
# 'papersize': 'letterpaper',
|
| 143 |
+
|
| 144 |
+
# The font size ('10pt', '11pt' or '12pt').
|
| 145 |
+
#
|
| 146 |
+
# 'pointsize': '10pt',
|
| 147 |
+
|
| 148 |
+
# Additional stuff for the LaTeX preamble.
|
| 149 |
+
#
|
| 150 |
+
# 'preamble': '',
|
| 151 |
+
}
|
| 152 |
+
|
| 153 |
+
# Grouping the document tree into LaTeX files. List of tuples
|
| 154 |
+
# (source start file, target name, title,
|
| 155 |
+
# author, documentclass [howto, manual, or own class]).
|
| 156 |
+
latex_documents = [
|
| 157 |
+
(root_doc, 'vlmevalkit.tex', 'VLMEvalKit Documentation', author,
|
| 158 |
+
'manual'),
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
# -- Options for manual page output ------------------------------------------
|
| 162 |
+
|
| 163 |
+
# One entry per manual page. List of tuples
|
| 164 |
+
# (source start file, name, description, authors, manual section).
|
| 165 |
+
man_pages = [(root_doc, 'vlmevalkit', 'VLMEvalKit Documentation', [author],
|
| 166 |
+
1)]
|
| 167 |
+
|
| 168 |
+
# -- Options for Texinfo output ----------------------------------------------
|
| 169 |
+
|
| 170 |
+
# Grouping the document tree into Texinfo files. List of tuples
|
| 171 |
+
# (source start file, target name, title, author,
|
| 172 |
+
# dir menu entry, description, category)
|
| 173 |
+
texinfo_documents = [
|
| 174 |
+
(root_doc, 'vlmevalkit', 'VLMEvalKit Documentation', author,
|
| 175 |
+
'VLMEvalKit Authors', 'AGI evaluation toolbox and benchmark.',
|
| 176 |
+
'Miscellaneous'),
|
| 177 |
+
]
|
| 178 |
+
|
| 179 |
+
# -- Options for Epub output -------------------------------------------------
|
| 180 |
+
|
| 181 |
+
# Bibliographic Dublin Core info.
|
| 182 |
+
epub_title = project
|
| 183 |
+
|
| 184 |
+
# The unique identifier of the text. This can be a ISBN number
|
| 185 |
+
# or the project homepage.
|
| 186 |
+
#
|
| 187 |
+
# epub_identifier = ''
|
| 188 |
+
|
| 189 |
+
# A unique identification for the text.
|
| 190 |
+
#
|
| 191 |
+
# epub_uid = ''
|
| 192 |
+
|
| 193 |
+
# A list of files that should not be packed into the epub file.
|
| 194 |
+
epub_exclude_files = ['search.html']
|
| 195 |
+
|
| 196 |
+
# set priority when building html
|
| 197 |
+
StandaloneHTMLBuilder.supported_image_types = [
|
| 198 |
+
'image/svg+xml', 'image/gif', 'image/png', 'image/jpeg'
|
| 199 |
+
]
|
| 200 |
+
|
| 201 |
+
# -- Extension configuration -------------------------------------------------
|
| 202 |
+
# Ignore >>> when copying code
|
| 203 |
+
copybutton_prompt_text = r'>>> |\.\.\. '
|
| 204 |
+
copybutton_prompt_is_regexp = True
|
| 205 |
+
|
| 206 |
+
# Auto-generated header anchors
|
| 207 |
+
myst_heading_anchors = 3
|
| 208 |
+
# Enable "colon_fence" extension of myst.
|
| 209 |
+
myst_enable_extensions = ['colon_fence', 'dollarmath']
|
| 210 |
+
|
| 211 |
+
# Configuration for intersphinx
|
| 212 |
+
intersphinx_mapping = {
|
| 213 |
+
'python': ('https://docs.python.org/3', None),
|
| 214 |
+
'numpy': ('https://numpy.org/doc/stable', None),
|
| 215 |
+
'torch': ('https://pytorch.org/docs/stable/', None),
|
| 216 |
+
'mmengine': ('https://mmengine.readthedocs.io/en/latest/', None),
|
| 217 |
+
'transformers':
|
| 218 |
+
('https://huggingface.co/docs/transformers/main/en/', None),
|
| 219 |
+
}
|
| 220 |
+
napoleon_custom_sections = [
|
| 221 |
+
# Custom sections for data elements.
|
| 222 |
+
('Meta fields', 'params_style'),
|
| 223 |
+
('Data fields', 'params_style'),
|
| 224 |
+
]
|
| 225 |
+
|
| 226 |
+
# Disable docstring inheritance
|
| 227 |
+
autodoc_inherit_docstrings = False
|
| 228 |
+
# Mock some imports during generate API docs.
|
| 229 |
+
autodoc_mock_imports = ['rich', 'attr', 'einops']
|
| 230 |
+
# Disable displaying type annotations, these can be very verbose
|
| 231 |
+
autodoc_typehints = 'none'
|
| 232 |
+
|
| 233 |
+
# The not found page
|
| 234 |
+
notfound_template = '404.html'
|
docs/en/docutils.conf
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[html writers]
|
| 2 |
+
table_style: colwidths-auto
|
docs/en/index.rst
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Welcome to the VLMEvalKit Tutorial!
|
| 2 |
+
==========================================
|
| 3 |
+
|
| 4 |
+
VLMEvalKit Getting Started Guide
|
| 5 |
+
-------------------------------
|
| 6 |
+
|
| 7 |
+
To help users get started quickly, we recommend the following process:
|
| 8 |
+
|
| 9 |
+
- For users who want to use VLMEvalKit, we recommend reading the "Start Your First Step" section to set up the environment and start a mini-experiment to familiarize yourself with the process.
|
| 10 |
+
|
| 11 |
+
- If you want to customize more modules, such as adding datasets and models, we provide an "Advanced Tutorial."
|
| 12 |
+
|
| 13 |
+
We always welcome users' PRs (Pull Requests) and Issues to improve VLMEvalKit!
|
| 14 |
+
|
| 15 |
+
.. _Start Your First Step:
|
| 16 |
+
.. toctree::
|
| 17 |
+
:maxdepth: 1
|
| 18 |
+
:caption: Start Your First Step
|
| 19 |
+
|
| 20 |
+
Quickstart.md
|
| 21 |
+
|
| 22 |
+
.. _Advanced Tutorial:
|
| 23 |
+
.. toctree::
|
| 24 |
+
:maxdepth: 1
|
| 25 |
+
:caption: Advanced Tutorial
|
| 26 |
+
|
| 27 |
+
Development.md
|
| 28 |
+
ConfigSystem.md
|
| 29 |
+
|
| 30 |
+
.. _Other Notes:
|
| 31 |
+
.. toctree::
|
| 32 |
+
:maxdepth: 1
|
| 33 |
+
:caption: Other Notes
|
| 34 |
+
|
| 35 |
+
Contributors.md
|
| 36 |
+
|
| 37 |
+
Index and Tables
|
| 38 |
+
==================
|
| 39 |
+
|
| 40 |
+
* :ref:`genindex`
|
| 41 |
+
* :ref:`search`
|
docs/ja/README_ja.md
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
<b>VLMEvalKit: 大規模視覚言語モデルの評価ツールキット</b>
|
| 6 |
+
|
| 7 |
+
[![][github-contributors-shield]][github-contributors-link] • [![][github-forks-shield]][github-forks-link] • [![][github-stars-shield]][github-stars-link] • [![][github-issues-shield]][github-issues-link] • [![][github-license-shield]][github-license-link]
|
| 8 |
+
|
| 9 |
+
[English](/README.md) | [简体中文](/docs/zh-CN/README_zh-CN.md) | 日本語
|
| 10 |
+
|
| 11 |
+
<a href="https://rank.opencompass.org.cn/leaderboard-multimodal">🏆 OpenCompass Learderboard </a> •
|
| 12 |
+
<a href="#-datasets-models-and-evaluation-results">📊Datasets & Models </a> •
|
| 13 |
+
<a href="#%EF%B8%8F-quickstart">🏗️Quickstart </a> •
|
| 14 |
+
<a href="#%EF%B8%8F-development-guide">🛠️Development </a> •
|
| 15 |
+
<a href="#-the-goal-of-vlmevalkit">🎯Goal </a> •
|
| 16 |
+
<a href="#%EF%B8%8F-citation">🖊️Citation </a>
|
| 17 |
+
|
| 18 |
+
<a href="https://huggingface.co/spaces/opencompass/open_vlm_leaderboard">🤗 HF Leaderboard</a> •
|
| 19 |
+
<a href="https://huggingface.co/datasets/VLMEval/OpenVLMRecords">🤗 Evaluation Records</a> •
|
| 20 |
+
<a href="https://discord.gg/evDT4GZmxN">🔊 Discord Channel</a> •
|
| 21 |
+
<a href="https://www.arxiv.org/abs/2407.11691">📝 Technical Report</a>
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
**VLMEvalKit**(pythonパッケージ名は**vlmeval**)は、**大規模視覚言語モデル(LVLMs)**の**オープンソース評価ツールキット**です。このツールキットは、複数のリポジトリでのデータ準備という重労働なしに、さまざまなベンチマークでLVLMsの**ワンコマンド評価**を可能にします。VLMEvalKitでは、すべてのLVLMsに対して**生成ベースの評価**を採用し、**正確なマッチング**と**LLMベースの回答抽出**の両方で得られた評価結果を提供します。
|
| 25 |
+
|
| 26 |
+
PS: 日本語の README には最新のアップデートがすべて含まれていない場合があります。英語版をご確認ください。
|
| 27 |
+
|
| 28 |
+
## 📊 データセット、モデル、および評価結果
|
| 29 |
+
|
| 30 |
+
**公式のマルチモーダルリーダーボードでのパフォーマンス数値は、ここからダウンロードできます!**
|
| 31 |
+
|
| 32 |
+
[**OpenVLM Leaderboard**](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard): [すべての詳細な結果をダウンロード](http://opencompass.openxlab.space/assets/OpenVLM.json)。
|
| 33 |
+
|
| 34 |
+
**Supported Image Understanding Dataset**
|
| 35 |
+
|
| 36 |
+
- デフォルトでは、すべての評価結果は[**OpenVLM Leaderboard**](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard)に表示されます。
|
| 37 |
+
|
| 38 |
+
| データセット | データセット名 (run.py用) | タスク | データセット | データセット名 (run.py用) | タスク |
|
| 39 |
+
| ------------------------------------------------------------ | ------------------------------------------------------ | --------- | --------- | --------- | --------- |
|
| 40 |
+
| [**MMBench シリーズ**](https://github.com/open-compass/mmbench/): <br>MMBench, MMBench-CN, CCBench | MMBench\_DEV\_[EN/CN] <br>MMBench\_TEST\_[EN/CN]<br>MMBench\_DEV\_[EN/CN]\_V11<br>MMBench\_TEST\_[EN/CN]\_V11<br>CCBench | 多肢選択問題 (MCQ) | [**MMStar**](https://github.com/MMStar-Benchmark/MMStar) | MMStar | MCQ |
|
| 41 |
+
| [**MME**](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation) | MME | はい/いいえ (Y/N) | [**SEEDBench シリーズ**](https://github.com/AILab-CVC/SEED-Bench) | SEEDBench_IMG <br>SEEDBench2 <br>SEEDBench2_Plus | MCQ |
|
| 42 |
+
| [**MM-Vet**](https://github.com/yuweihao/MM-Vet) | MMVet | VQA | [**MMMU**](https://mmmu-benchmark.github.io) | MMMU_[DEV_VAL/TEST] | MCQ |
|
| 43 |
+
| [**MathVista**](https://mathvista.github.io) | MathVista_MINI | VQA | [**ScienceQA_IMG**](https://scienceqa.github.io) | ScienceQA_[VAL/TEST] | MCQ |
|
| 44 |
+
| [**COCO Caption**](https://cocodataset.org) | COCO_VAL | キャプション | [**HallusionBench**](https://github.com/tianyi-lab/HallusionBench) | HallusionBench | Y/N |
|
| 45 |
+
| [**OCRVQA**](https://ocr-vqa.github.io)* | OCRVQA_[TESTCORE/TEST] | VQA | [**TextVQA**](https://textvqa.org)* | TextVQA_VAL | VQA |
|
| 46 |
+
| [**ChartQA**](https://github.com/vis-nlp/ChartQA)* | ChartQA_TEST | VQA | [**AI2D**](https://allenai.org/data/diagrams) | AI2D_[TEST/TEST_NO_MASK] | MCQ |
|
| 47 |
+
| [**LLaVABench**](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) | LLaVABench | VQA | [**DocVQA**](https://www.docvqa.org)+ | DocVQA_[VAL/TEST] | VQA |
|
| 48 |
+
| [**InfoVQA**](https://www.docvqa.org/datasets/infographicvqa)+ | InfoVQA_[VAL/TEST] | VQA | [**OCRBench**](https://github.com/Yuliang-Liu/MultimodalOCR) | OCRBench | VQA |
|
| 49 |
+
| [**RealWorldQA**](https://x.ai/blog/grok-1.5v) | RealWorldQA | MCQ | [**POPE**](https://github.com/AoiDragon/POPE) | POPE | Y/N |
|
| 50 |
+
| [**Core-MM**](https://github.com/core-mm/core-mm)- | CORE_MM | VQA | [**MMT-Bench**](https://mmt-bench.github.io) | MMT-Bench_[VAL/VAL_MI/ALL/ALL_MI] | MCQ |
|
| 51 |
+
| [**MLLMGuard**](https://github.com/Carol-gutianle/MLLMGuard) - | MLLMGuard_DS | VQA | [**AesBench**](https://github.com/yipoh/AesBench) | AesBench_[VAL/TEST] | MCQ |
|
| 52 |
+
| [**VCR-wiki**](https://huggingface.co/vcr-org/) + | VCR\_[EN/ZH]\_[EASY/HARD]_[ALL/500/100] | VQA | [**MMLongBench-Doc**](https://mayubo2333.github.io/MMLongBench-Doc/)+ | MMLongBench_DOC | VQA |
|
| 53 |
+
| [**BLINK**](https://zeyofu.github.io/blink/) + | BLINK | MCQ | [**MathVision**](https://mathvision-cuhk.github.io)+ | MathVision<br>MathVision_MINI | VQA |
|
| 54 |
+
| [**MT-VQA**](https://github.com/bytedance/MTVQA)+ | MTVQA_TEST | VQA | [**MMDU**](https://liuziyu77.github.io/MMDU/)+ | MMDU | VQA (multi-turn) |
|
| 55 |
+
| [**Q-Bench1**](https://github.com/Q-Future/Q-Bench)+ | Q-Bench1_[VAL/TEST] | MCQ | [**A-Bench**](https://github.com/Q-Future/A-Bench)+ | A-Bench_[VAL/TEST] | MCQ |
|
| 56 |
+
| [**TaskMeAnything ImageQA Random**](https://huggingface.co/datasets/weikaih/TaskMeAnything-v1-imageqa-random)+ | TaskMeAnything_v1_imageqa_random | MCQ | | | |
|
| 57 |
+
|
| 58 |
+
**\*** ゼロショット設定で合理的な結果を出せないVLMの一部の評価結果のみを提供しています
|
| 59 |
+
|
| 60 |
+
**\+** 評価結果はまだ利用できません
|
| 61 |
+
|
| 62 |
+
**\-** VLMEvalKitでは推論のみがサポートされています
|
| 63 |
+
|
| 64 |
+
VLMEvalKitは、キーを設定すると**判定LLM**を使用して出力から回答を抽出し、それ以外の場合は**正確なマッチング**モード(出力文字列で「はい」、「いいえ」、「A」、「B」、「C」...を検索)を使用します。**正確なマッチングは、はい/いいえのタスクと多肢選択問題にのみ適用できます。**
|
| 65 |
+
|
| 66 |
+
**Supported Video Understanding Dataset**
|
| 67 |
+
|
| 68 |
+
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|
| 69 |
+
| ---------------------------------------------------- | -------------------------- | ---- | --------------------------------------------- | -------------------------- | ---- |
|
| 70 |
+
| [**MMBench-Video**](https://mmbench-video.github.io) | MMBench-Video | VQA | [**Video-MME**](https://video-mme.github.io/) | Video-MME | MCQ |
|
| 71 |
+
|
| 72 |
+
**Supported API Models**
|
| 73 |
+
|
| 74 |
+
| [**GPT-4v (20231106, 20240409)**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**GPT-4o**](https://openai.com/index/hello-gpt-4o/) 🎞️🚅 | [**Gemini-1.0-Pro**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**Gemini-1.5-Pro**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**Step-1V**](https://www.stepfun.com/#step1v) 🎞️🚅 |
|
| 75 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------- |
|
| 76 |
+
| [**Reka-[Edge / Flash / Core]**](https://www.reka.ai)🚅 | [**Qwen-VL-[Plus / Max]**](https://huggingface.co/spaces/Qwen/Qwen-VL-Max) 🎞️🚅 | [**Claude-3v-[Haiku / Sonnet / Opus]**](https://www.anthropic.com/news/claude-3-family) 🎞️🚅 | [**GLM-4v**](https://open.bigmodel.cn/dev/howuse/glm4v) 🚅 | [**CongRong**](https://mllm.cloudwalk.com/web) 🎞️🚅 |
|
| 77 |
+
| [**Claude3.5-Sonnet**](https://www.anthropic.com/news/claude-3-5-sonnet) 🎞️🚅 | [**GPT-4o-Mini**](https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/) 🎞️🚅 | [**Yi-Vision**](https://platform.lingyiwanwu.com)🎞️🚅 | [**Hunyuan-Vision**](https://cloud.tencent.com/document/product/1729)🎞️🚅 | [**BlueLM-V**](https://developers.vivo.com/) 🎞️🚅 |
|
| 78 |
+
|
| 79 |
+
**Supported PyTorch / HF Models**
|
| 80 |
+
|
| 81 |
+
| [**IDEFICS-[9B/80B/v2-8B]-Instruct**](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct)🎞️🚅 | [**InstructBLIP-[7B/13B]**](https://github.com/salesforce/LAVIS/blob/main/projects/instructblip/README.md) | [**LLaVA-[v1-7B/v1.5-7B/v1.5-13B]**](https://github.com/haotian-liu/LLaVA) | [**MiniGPT-4-[v1-7B/v1-13B/v2-7B]**](https://github.com/Vision-CAIR/MiniGPT-4) |
|
| 82 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
| 83 |
+
| [**mPLUG-Owl2**](https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2)🎞️ | [**OpenFlamingo-v2**](https://github.com/mlfoundations/open_flamingo)🎞️ | [**PandaGPT-13B**](https://github.com/yxuansu/PandaGPT) | [**Qwen-VL**](https://huggingface.co/Qwen/Qwen-VL)🎞️🚅, [**Qwen-VL-Chat**](https://huggingface.co/Qwen/Qwen-VL-Chat)🎞️**🚅** |
|
| 84 |
+
| [**VisualGLM-6B**](https://huggingface.co/THUDM/visualglm-6b)🚅 | [**InternLM-XComposer-[1/2]**](https://huggingface.co/internlm/internlm-xcomposer-7b)🚅 | [**ShareGPT4V-[7B/13B]**](https://sharegpt4v.github.io)🚅 | [**TransCore-M**](https://github.com/PCIResearch/TransCore-M) |
|
| 85 |
+
| [**LLaVA (XTuner)**](https://huggingface.co/xtuner/llava-internlm-7b)🚅 | [**CogVLM-[Chat/Llama3]**](https://huggingface.co/THUDM/cogvlm-chat-hf)🚅 | [**ShareCaptioner**](https://huggingface.co/spaces/Lin-Chen/Share-Captioner)🚅 | [**CogVLM-Grounding-Generalist**](https://huggingface.co/THUDM/cogvlm-grounding-generalist-hf)🚅 |
|
| 86 |
+
| [**Monkey**](https://github.com/Yuliang-Liu/Monkey)🚅, [**Monkey-Chat**](https://github.com/Yuliang-Liu/Monkey)🚅 | [**EMU2-Chat**](https://github.com/baaivision/Emu)🚅🎞️ | [**Yi-VL-[6B/34B]**](https://huggingface.co/01-ai/Yi-VL-6B) | [**MMAlaya**](https://huggingface.co/DataCanvas/MMAlaya)🚅 |
|
| 87 |
+
| [**InternLM-XComposer-2.5**](https://github.com/InternLM/InternLM-XComposer)🚅🎞️ | [**MiniCPM-[V1/V2/V2.5/V2.6]**](https://github.com/OpenBMB/MiniCPM-V)🚅🎞️ | [**OmniLMM-12B**](https://huggingface.co/openbmb/OmniLMM-12B) | [**InternVL-Chat-[V1-1/V1-2/V1-5/V2]**](https://github.com/OpenGVLab/InternVL)🚅🎞️, <br>[**Mini-InternVL-Chat-[2B/4B]-V1-5**](https://github.com/OpenGVLab/InternVL)🚅🎞️ |
|
| 88 |
+
| [**DeepSeek-VL**](https://github.com/deepseek-ai/DeepSeek-VL/tree/main)🎞️ | [**LLaVA-NeXT**](https://llava-vl.github.io/blog/2024-01-30-llava-next/)🚅🎞️ | [**Bunny-Llama3**](https://huggingface.co/BAAI/Bunny-v1_1-Llama-3-8B-V)🚅 | [**XVERSE-V-13B**](https://github.com/xverse-ai/XVERSE-V-13B/blob/main/vxverse/models/vxverse.py) |
|
| 89 |
+
| [**PaliGemma-3B**](https://huggingface.co/google/paligemma-3b-pt-448) 🚅 | [**360VL-70B**](https://huggingface.co/qihoo360/360VL-70B) 🚅 | [**Phi-3-Vision**](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)🚅 | [**WeMM**](https://github.com/scenarios/WeMM)🚅 |
|
| 90 |
+
| [**GLM-4v-9B**](https://huggingface.co/THUDM/glm-4v-9b) 🚅 | [**Cambrian-[8B/13B/34B]**](https://cambrian-mllm.github.io/) | [**LLaVA-Next-[Qwen-32B]**](https://huggingface.co/lmms-lab/llava-next-qwen-32b) 🎞️ | [**Chameleon-[7B/30B]**](https://huggingface.co/facebook/chameleon-7b)🚅🎞️ |
|
| 91 |
+
| [**Video-LLaVA-7B-[HF]**](https://github.com/PKU-YuanGroup/Video-LLaVA) 🎬 | [**VILA1.5-[8B/13B/40B]**](https://github.com/NVlabs/VILA/)🎞️ | [**Ovis1.5-Llama3-8B**](https://github.com/AIDC-AI/Ovis) 🚅🎞 | [**Mantis-8B-[siglip-llama3/clip-llama3/Idefics2/Fuyu]**](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) 🎞️ |
|
| 92 |
+
|
| 93 |
+
🎞️: 複数の画像を入力としてサポートします。
|
| 94 |
+
|
| 95 |
+
🚅: 追加の設定/操作なしで使用できるモデルです。
|
| 96 |
+
|
| 97 |
+
🎬: 入力としてビデオをサポート。
|
| 98 |
+
|
| 99 |
+
**Transformersバージョンの推奨事項:**
|
| 100 |
+
|
| 101 |
+
特定のtransformerバージョンで一部のVLMが実行できない可能性があることに注意してください。各VLMを評価するために、以下の設定を推奨します:
|
| 102 |
+
|
| 103 |
+
- **`transformers==4.33.0`を使用してください**: `Qwenシリーズ`, `Monkeyシリーズ`, `InternLM-XComposerシリーズ`, `mPLUG-Owl2`, `OpenFlamingo v2`, `IDEFICSシリーズ`, `VisualGLM`, `MMAlaya`, `ShareCaptioner`, `MiniGPT-4シリーズ`, `InstructBLIPシリーズ`, `PandaGPT`, `VXVERSE`, `GLM-4v-9B`.
|
| 104 |
+
- **`transformers==4.37.0`を使用してください**: `LLaVAシリーズ`, `ShareGPT4Vシリーズ`, `TransCore-M`, `LLaVA (XTuner)`, `CogVLMシリーズ`, `EMU2シリーズ`, `Yi-VLシリーズ`, `MiniCPM-[V1/V2]`, `OmniLMM-12B`, `DeepSeek-VLシリーズ`, `InternVLシリーズ`, `Cambrianシリーズ`, `VILA-VLシリーズ`.
|
| 105 |
+
- **`transformers==4.40.0`を使用してください**: `IDEFICS2`, `Bunny-Llama3`, `MiniCPM-Llama3-V2.5`, `360VL-70B`, `Phi-3-Vision`, `WeMM`.
|
| 106 |
+
- **`transformers==latest`を使用してください**: `LLaVA-Nextシリーズ`, `PaliGemma-3B`, `Chameleon-VLシリーズ`, `Video-LLaVA-7B-HF`, `Ovis1.5シリーズ`, `Mantisシリーズ`, `MiniCPM-V2.6`.
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
# デモ
|
| 110 |
+
from vlmeval.config import supported_VLM
|
| 111 |
+
model = supported_VLM['idefics_9b_instruct']()
|
| 112 |
+
# 単一画像のフォワード
|
| 113 |
+
ret = model.generate(['assets/apple.jpg', 'この画像には何がありますか?'])
|
| 114 |
+
print(ret) # この画像には葉がついた赤いリンゴがあります。
|
| 115 |
+
# 複数画像のフォワード
|
| 116 |
+
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', '提供された画像にはリンゴが何個ありますか?'])
|
| 117 |
+
print(ret) # 提供された画像にはリンゴが2個あります。
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
## 🏗️ クイックスタート
|
| 121 |
+
|
| 122 |
+
クイックスタートガイドについては、[クイックスタート](/docs/en/Quickstart.md)を参照してください。
|
| 123 |
+
|
| 124 |
+
## 🛠️ 開発ガイド
|
| 125 |
+
|
| 126 |
+
カスタムベンチマーク、VLMsを開発するか、単に**VLMEvalKit**に他のコードを貢献する場合は、[開発ガイド](/docs/en/Development.md)を参照してください。
|
| 127 |
+
|
| 128 |
+
コミュニティからの共有を奨励し、それに応じたクレジットを共有するために、次回のレポート更新では以下のことを実施します:
|
| 129 |
+
|
| 130 |
+
- 全ての貢献に対して感謝の意を示します
|
| 131 |
+
- 新しいモデル、評価セット、または主要な機能への3つ以上の主要な貢献を持つ貢献者は、テクニカルレポートの著者リストに加わることができます。適格な貢献者は、issueを作成するか、または[VLM評価キット ディスコードチャンネル](https://discord.com/invite/evDT4GZmxN)で kennyutc にDMを送ることができます。私たちはそれに応じてフォローアップします。
|
| 132 |
+
|
| 133 |
+
## 🎯 VLMEvalKitの目標
|
| 134 |
+
|
| 135 |
+
**このコードベースは以下を目的として設計されています:**
|
| 136 |
+
|
| 137 |
+
1. 研究者や開発者が既存のLVLMsを評価し、評価結果を**簡単に再現できるようにする**ための**使いやすい**、**オープンソースの評価ツールキット**を提供します。
|
| 138 |
+
2. VLMの開発者が自分のモデルを簡単に評価できるようにします。複数のサポートされているベンチマークでVLMを評価するには、単一の`generate_inner()`関数を**実装するだけで**、他のすべてのワークロード(データのダウンロード、データの前処理、予測の推論、メトリックの計算)はコードベースによって処理されます。
|
| 139 |
+
|
| 140 |
+
**このコードベースは以下を目的として設計されていません:**
|
| 141 |
+
|
| 142 |
+
1. すべての**第三者ベンチマーク**の元の論文で報告された正確な精度数値を再現すること。その理由は2つあります:
|
| 143 |
+
1. VLMEvalKitは、すべてのVLMに対して**生成ベースの評価**を使用します(オプションで**LLMベースの回答抽出**を使用)。一方、一部のベンチマークは異なるアプローチを使用する場合があります(SEEDBenchはPPLベースの評価を使用します)。これらのベンチマークについては、対応する結果で両方のスコアを比較します。開発者には、コードベースで他の評価パラダイムをサポートすることをお勧めします。
|
| 144 |
+
2. デフォルトでは、すべてのVLMに対して同じプロンプトテンプレートを使用してベンチマークを評価します。一方、**一部のVLMには特定のプロンプトテンプレートがある**場合があります(現時点ではコードベースでカバーされていない場合があります)。VLMの開発者には、現在カバーされていない場合でも、VLMEvalKitで独自のプロンプトテンプレートを実装することをお勧めします。これにより、再現性が向上します。
|
| 145 |
+
|
| 146 |
+
## 🖊️ 引用
|
| 147 |
+
|
| 148 |
+
この作業が役立つ場合は、このリポジトリに**スター🌟**を付けてください。サポートありがとうございます!
|
| 149 |
+
|
| 150 |
+
[](https://github.com/open-compass/VLMEvalKit/stargazers)
|
| 151 |
+
|
| 152 |
+
研究でVLMEvalKitを使用する場合、または公開されたオープンソースの評価結果を参照する場合は、以下のBibTeXエントリと、使用した特定のVLM/ベンチマークに対応するBibTexエントリを使用してください。
|
| 153 |
+
|
| 154 |
+
```bib
|
| 155 |
+
@misc{duan2024vlmevalkit,
|
| 156 |
+
title={VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models},
|
| 157 |
+
author={Haodong Duan and Junming Yang and Yuxuan Qiao and Xinyu Fang and Lin Chen and Yuan Liu and Xiaoyi Dong and Yuhang Zang and Pan Zhang and Jiaqi Wang and Dahua Lin and Kai Chen},
|
| 158 |
+
year={2024},
|
| 159 |
+
eprint={2407.11691},
|
| 160 |
+
archivePrefix={arXiv},
|
| 161 |
+
primaryClass={cs.CV},
|
| 162 |
+
url={https://arxiv.org/abs/2407.11691},
|
| 163 |
+
}
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
<p align="right"><a href="#top">🔝Top に戻る</a></p>
|
| 167 |
+
|
| 168 |
+
[github-contributors-link]: https://github.com/open-compass/VLMEvalKit/graphs/contributors
|
| 169 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/VLMEvalKit?color=c4f042&labelColor=black&style=flat-square
|
| 170 |
+
[github-forks-link]: https://github.com/open-compass/VLMEvalKit/network/members
|
| 171 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/VLMEvalKit?color=8ae8ff&labelColor=black&style=flat-square
|
| 172 |
+
[github-issues-link]: https://github.com/open-compass/VLMEvalKit/issues
|
| 173 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/VLMEvalKit?color=ff80eb&labelColor=black&style=flat-square
|
| 174 |
+
[github-license-link]: https://github.com/open-compass/VLMEvalKit/blob/main/LICENSE
|
| 175 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/VLMEvalKit?color=white&labelColor=black&style=flat-square
|
| 176 |
+
[github-stars-link]: https://github.com/open-compass/VLMEvalKit/stargazers
|
| 177 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/VLMEvalKit?color=ffcb47&labelColor=black&style=flat-square
|
docs/zh-CN/.readthedocs.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2
|
| 2 |
+
|
| 3 |
+
# Set the version of Python and other tools you might need
|
| 4 |
+
build:
|
| 5 |
+
os: ubuntu-22.04
|
| 6 |
+
tools:
|
| 7 |
+
python: "3.8"
|
| 8 |
+
|
| 9 |
+
formats:
|
| 10 |
+
- epub
|
| 11 |
+
|
| 12 |
+
sphinx:
|
| 13 |
+
configuration: docs/zh-CN/conf.py
|
| 14 |
+
|
| 15 |
+
python:
|
| 16 |
+
install:
|
| 17 |
+
- requirements: requirements/docs.txt
|
docs/zh-CN/ConfigSystem.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# 配置系统
|
| 3 |
+
|
| 4 |
+
默认情况下,VLMEvalKit通过在`run.py`脚本中使用`--model`和`--data`参数设置模型名称(在`/vlmeval/config.py`中定义)和数据集名称(在`vlmeval/dataset/__init__.py`中定义)来启动评估。这种方法在大多数情况下简单且高效,但当用户希望使用不同设置评估多个模型/数据集时,可能不够灵活。
|
| 5 |
+
|
| 6 |
+
为了解决这个问题,VLMEvalKit提供了一个更灵活的配置系统。用户可以在json文件中指定模型和数据集设置,并通过`--config`参数将配置文件的路径传递给`run.py`脚本。以下是一个示例配置json:
|
| 7 |
+
|
| 8 |
+
```json
|
| 9 |
+
{
|
| 10 |
+
"model": {
|
| 11 |
+
"GPT4o_20240806_T00_HIGH": {
|
| 12 |
+
"class": "GPT4V",
|
| 13 |
+
"model": "gpt-4o-2024-08-06",
|
| 14 |
+
"temperature": 0,
|
| 15 |
+
"img_detail": "high"
|
| 16 |
+
},
|
| 17 |
+
"GPT4o_20240806_T10_Low": {
|
| 18 |
+
"class": "GPT4V",
|
| 19 |
+
"model": "gpt-4o-2024-08-06",
|
| 20 |
+
"temperature": 1.0,
|
| 21 |
+
"img_detail": "low"
|
| 22 |
+
}
|
| 23 |
+
},
|
| 24 |
+
"data": {
|
| 25 |
+
"MME-RealWorld-Lite": {
|
| 26 |
+
"class": "MMERealWorld",
|
| 27 |
+
"dataset": "MME-RealWorld-Lite"
|
| 28 |
+
},
|
| 29 |
+
"MMBench_DEV_EN_V11": {
|
| 30 |
+
"class": "ImageMCQDataset",
|
| 31 |
+
"dataset": "MMBench_DEV_EN_V11"
|
| 32 |
+
}
|
| 33 |
+
}
|
| 34 |
+
}
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
配置json的解释:
|
| 38 |
+
|
| 39 |
+
1. 现在我们支持两个字段:`model`和`data`,每个字段都是一个字典。字典的键是模型/数据集的名称(由用户设置),值是模型/数据集的设置。
|
| 40 |
+
2. 对于`model`中的项目,值是一个包含以下键的字典:
|
| 41 |
+
- `class`:模型的类名,应该是`vlmeval/vlm/__init__.py`(开源模型)或`vlmeval/api/__init__.py`(API模型)中定义的类名。
|
| 42 |
+
- 其他kwargs:其他kwargs是模型特定的参数,请参考模型类的定义以获取详细用法。例如,`model`、`temperature`、`img_detail`是`GPT4V`类的参数。值得注意的是,大多数模型类都需要`model`参数。
|
| 43 |
+
3. 对于字典`data`,我们建议用户使用官方数据集名称作为键(或键的一部分),因为我们经常根据数据集名称确定后处理/判断设置。对于`data`中的项目,值是一个包含以下键的字典:
|
| 44 |
+
- `class`:数据集的类名,应该是`vlmeval/dataset/__init__.py`中定义的类名。
|
| 45 |
+
- 其他kwargs:其他kwargs是数据集特定的参数,请参考数据集类的定义以获取详细用法。通常,大多数数据集类都需要`dataset`参数。
|
| 46 |
+
|
| 47 |
+
将示例配置json保存为`config.json`,您可以通过以下命令启动评估:
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
python run.py --config config.json
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
这将在工作目录`$WORK_DIR`下生成以下输出文件(格式为`{$WORK_DIR}/{$MODEL_NAME}/{$MODEL_NAME}_{$DATASET_NAME}_*`):
|
| 54 |
+
|
| 55 |
+
- `$WORK_DIR/GPT4o_20240806_T00_HIGH/GPT4o_20240806_T00_HIGH_MME-RealWorld-Lite*`
|
| 56 |
+
- `$WORK_DIR/GPT4o_20240806_T10_Low/GPT4o_20240806_T10_Low_MME-RealWorld-Lite*`
|
| 57 |
+
- `$WORK_DIR/GPT4o_20240806_T00_HIGH/GPT4o_20240806_T00_HIGH_MMBench_DEV_EN_V11*`
|
| 58 |
+
- `$WORK_DIR/GPT4o_20240806_T10_Low/GPT4o_20240806_T10_Low_MMBench_DEV_EN_V11*`
|
| 59 |
+
-
|
docs/zh-CN/Development.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 🛠️ 如何在 VLMEvalKit 中实现一个新的 Benchmark 或多模态模型(VLM)
|
| 2 |
+
|
| 3 |
+
## 实现一个新的 benchmark
|
| 4 |
+
|
| 5 |
+
示例 PR: **添加 Math-Vision Benchmark** ([#292](https://github.com/open-compass/VLMEvalKit/pull/292/files))
|
| 6 |
+
|
| 7 |
+
目前在 VLMEvalKit 中,benchmark 以数据集类的形式呈现,当你新增一个 benchmark 时,你可以选择复用现有的数据集类 (如单选题 benchmark 可复用 `ImageMCQDataset`),或是实现新的数据集类。你的数据集类必须支持以下两种方法 (复用父类或自行实现):
|
| 8 |
+
|
| 9 |
+
- `build_prompt(self, line)`: 方法输入 `line` 类型为 int (对应数据 index) 或 `pd.Series` (对应数据原始 record)。方法输出一条 `multi-modal message` 作为多模态模型输入,`multi-modal message` 是一个图文交错的列表,如以下格式 (一图一文): `[dict(type='image', value=IMAGE_PTH), dict(type='text', value=prompt)]`。
|
| 10 |
+
- `evaluate(self, eval_file, **judge_kwargs)`: 方法输入 `eval_file` 为多模态模型的预测结果 (多以 `.xlsx` 格式存在),如 benchmark evaluation 需要大语言模型 (一般为 GPT) 辅助,则 `judge_kwargs` 传入大语言模型的参数。方法输出 benchmark 的评测结果,以 `dict` 或 `pd.DataFrame` 的形式。
|
| 11 |
+
|
| 12 |
+
以下,我们简述新增数据集的通常步骤:
|
| 13 |
+
|
| 14 |
+
### 1. TSV 数据文件准备 (图文评测集)
|
| 15 |
+
|
| 16 |
+
目前,我们将每一个 benchmark 数据集设置为一个单独的 TSV 文件。在推理过程中,数据文件将从数据集定义的 `DATASET_URL` 链接地址自动下载到 `$LMUData` 中(如果没有明确设置的话,默认路径是 `$HOME/LMUData`)。你可以将准备好的 TSV 文件上传到一个可下载的地址(如:huggingface),或发送给我们 <opencompass@pjlab.org.cn>,我们将帮助上传数据集到服务器中。此外,你也可以在环境变量中自定义设置下载路径 `LMUData=/path/to/your/data`。
|
| 17 |
+
|
| 18 |
+
TSV 文件中的内容组成为:
|
| 19 |
+
|
| 20 |
+
| 数据集名称 \ 字段 | index | image | image_path | question | hint | multi-choice<br>options | answer | category | l2-category | split |
|
| 21 |
+
| ---------------------- | ----- | ----- | ---------- | -------- | ---- | ----------------------- | ------ | -------- | ----------- | ----- |
|
| 22 |
+
| MMBench_DEV_[CN/EN] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 23 |
+
| MMBench_TEST_[CN/EN] | ✅ | ✅ | | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ |
|
| 24 |
+
| CCBench | ✅ | ✅ | | ✅ | | ✅ | ✅ | ✅ | | |
|
| 25 |
+
| SEEDBench_IMG | ✅ | ✅ | | ✅ | | ✅ | ✅ | ✅ | | |
|
| 26 |
+
| MME | ✅ | ✅ | | ✅ | | | ✅ | ✅ | | |
|
| 27 |
+
| CORE_MM | ✅ | ✅ | ✅ | ✅ | | | | ✅ | | |
|
| 28 |
+
| MMVet | ✅ | ✅ | | ✅ | | | ✅ | ✅ | | |
|
| 29 |
+
| MMMU_DEV_VAL | ✅ | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 30 |
+
| COCO_VAL | ✅ | ✅ | | | | | ✅ | | | |
|
| 31 |
+
| OCRVQA_[TEST/TESTCORE] | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 32 |
+
| TextVQA_VAL | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 33 |
+
| VCR_[EN/ZH]\_[EASY/HARD]_[ALL/500/100] | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 34 |
+
|
| 35 |
+
<div align="center"><b>表 1. 支持的数据集的 TSV 字段。</b></div>
|
| 36 |
+
|
| 37 |
+
**TSV 中必须字段的介绍:**
|
| 38 |
+
|
| 39 |
+
- **index:** 一个整数,`tsv` 中每一行的唯一标识
|
| 40 |
+
- **image:** 图片的 base64 编码,你可以使用 `vlmeval/smp/vlm.py` 中实现的API进行编码和解码:
|
| 41 |
+
- 编码:`encode_image_to_base64`(对于PIL Image)/ `encode_image_file_to_base64`(对于图片文件路径)
|
| 42 |
+
- 解码:`decode_base64_to_image`(对于PIL Image)/ `decode_base64_to_image_file`(对于图片文件路径)
|
| 43 |
+
- **question:** 针对图像所提取出的问题,类型为字符串
|
| 44 |
+
- **answer:** 问题的答案,类型为字符串,Test 集可缺失这一字段
|
| 45 |
+
|
| 46 |
+
### 2. 自定义数据集的 prompt 构建
|
| 47 |
+
|
| 48 |
+
`ImageBaseDataset` 定义了默认的 prompt 格式。如果需要针对数据集添加 prompt,或给模型输入 `Interleave` 的数据格式,可以通过 `build_prompt(line)` 函数实现���该函数输入为,每次给定 TSV 文件中的一行,包含 index, image, question 等内容作为 line。该函数将返回一个多模态消息 `msg` 的字典列表 `[dict(type='image', value=IMAGE_PTH), dict(type='text', value=prompt)]`,包括图片路径和将被输入到 VLMs 的文本 prompt。对于 interleave 类型输入,可以直接将图片路径的字典放置到 image token 位置。
|
| 49 |
+
|
| 50 |
+
### 3. 自定义数据集的指标实现
|
| 51 |
+
|
| 52 |
+
增加对 benchmark 的评测需要自定义一个该数据集的 class 对象,从而实现数据集的指标计算。图文多模态数据集均继承自 `vlmeval/dataset/image_base.py` 中的 `ImageBaseDataset` 对象。其中 `TYPE` 定义了数据集的类型;`DATASET_URL` 为数据集的下载地址;`DATASET_MD5` 为数据集文件的 md5 一致性编码检查。
|
| 53 |
+
|
| 54 |
+
在 class 中**需要实现** `evaluate(eval_file, **judge_kwargs)` 类函数,对自定义的数据集结果进行指标计算和结果输出。函数输入 `eval_file` 为模型预测结果 `{model_name}_{dataset}.xlsx` 的路径。可以通过 `load(eval_file)` 文件将其读取为 panda.DataFrames 类型,其中包含 index, question, answer, category, prediction 等字段。`judge_kwargs` 参数将传递一个评测相关的字典,如:judge 模型的名称,api 请求线程数等。**函数的返回值**为评估完成的准确度等指标,其格式为由 list 组成的字典,并组织成 panda.DataFrames 类型。
|
| 55 |
+
|
| 56 |
+
## 实现一个新的模型
|
| 57 |
+
|
| 58 |
+
示例 PR: **支持 LLaVA-Next-Interleave** ([#294](https://github.com/open-compass/VLMEvalKit/pull/294))
|
| 59 |
+
|
| 60 |
+
**1. 支持 `generate_inner` API (必须)**
|
| 61 |
+
|
| 62 |
+
现有所有的模型都在 `vlmeval/vlm` 中实现。对于一个最基本的模型,你的模型类**应该实现方法** `generate_inner(msgs, dataset=None)`。这个函数将向 VLM 输入一个多模态数据,并返回 VLM 的预测(一个字符串)。可选参数 `dataset` 可以用作模型在不同推理策略之间切换的标志。
|
| 63 |
+
|
| 64 |
+
其中多模态消息 `msgs` 是一个字典列表,每个字典有两个键:类型和值:
|
| 65 |
+
- `type`:我们目前支持两种类型,选项是 ["image", "text"]。
|
| 66 |
+
- `value`:当类型为 `text` 时,值是文本消息(一个字符串);当类型为 `image` 时,值可以是图像文件的本地路径,或者是图像的URL。
|
| 67 |
+
|
| 68 |
+
> 目前,一个多模态消息可能包含任意交错的图像和文本。如果你的模型不支持这一点,我们推荐的做法是取第一张图像和连接的文本消息作为模型的输入。你可以在模型的 class 中设置 `INTERLEAVE = False` 并调用 `self.message_to_promptimg(message, dataset=dataset)` 函数来获取你的 prompt 和第一张图片的地址。
|
| 69 |
+
|
| 70 |
+
一些多模态消息的例子:
|
| 71 |
+
|
| 72 |
+
```python
|
| 73 |
+
IMAGE_PTH = 'assets/apple.jpg'
|
| 74 |
+
IMAGE_URL = 'https://raw.githubusercontent.com/open-compass/VLMEvalKit/main/assets/apple.jpg'
|
| 75 |
+
msg1 = [
|
| 76 |
+
dict(type='image', value=IMAGE_PTH),
|
| 77 |
+
dict(type='text', value='What is in this image?')
|
| 78 |
+
]
|
| 79 |
+
msg2 = [
|
| 80 |
+
dict(type='image', value=IMAGE_URL),
|
| 81 |
+
dict(type='image', value=IMAGE_URL),
|
| 82 |
+
dict(type='text', value='How many apples are there in these images?')
|
| 83 |
+
]
|
| 84 |
+
response = model.generate(msg1)
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
为了方便起见,我们还支持接受字符串列表作为输入。在这种情况下,我们将检查一个字符串是图像路径还是图像 URL,并自动将其转换为 `list[dict]` 格式:
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
IMAGE_PTH = 'assets/apple.jpg'
|
| 91 |
+
IMAGE_URL = 'https://raw.githubusercontent.com/open-compass/VLMEvalKit/main/assets/apple.jpg'
|
| 92 |
+
msg1 = [IMAGE_PTH, 'What is in this image?']
|
| 93 |
+
msg2 = [IMAGE_URL, IMAGE_URL, 'How many apples are there in these images?']
|
| 94 |
+
response = model.generate(msg1)
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
**2. 支持自定义提示词构建 (可选)**
|
| 98 |
+
|
| 99 |
+
此外,你的模型可以通过实现两个可选方法来支持自定义提示构建:`use_custom_prompt(dataset)` 和 `build_prompt(line, dataset=None)`。
|
| 100 |
+
|
| 101 |
+
- `use_custom_prompt(dataset)` 将返回一个布尔值,指示模型是否应使用自定义提示构建策略。
|
| 102 |
+
- 如果`use_custom_prompt(dataset)`返回 True,`build_prompt(line, dataset)` 应该为相应的数据集返回一个自定义构建的多模态消息,line 数据是一个包含数据样本所需信息的字典。如果`use_custom_prompt(dataset)` 返回False,则将使用默认的 prompt 构建策略。
|
| 103 |
+
|
| 104 |
+
**3. 支持多轮对话 (可选)**
|
| 105 |
+
|
| 106 |
+
你可以通过支持 `chat_inner(message, dataset)` API 为你的模型新增多轮对话功能并兼容多轮对话评测。这个 API 输出一个字符串型回复,`message` 包含一个聊天记录的列表,格式如下:
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
# Assume msg1, msg2, msg3, ... are multi-modal messages following the previously described format
|
| 110 |
+
# `chat_inner` take the following chat history list as input:
|
| 111 |
+
message = [
|
| 112 |
+
dict(role='user', content=msg1),
|
| 113 |
+
dict(role='assistant', content=msg2),
|
| 114 |
+
dict(role='user', content=msg3),
|
| 115 |
+
dict(role='assistant', content=msg4),
|
| 116 |
+
......
|
| 117 |
+
dict(role='user', content=msgn),
|
| 118 |
+
]
|
| 119 |
+
# `message` should contain an odd number of chat utterances, the role of utterances should be interleaved "user" and "assistant", with the role of the last utterance to be "user".
|
| 120 |
+
# The chat function will call `chat_inner`
|
| 121 |
+
response = model.chat(message)
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
### 示例 PRs:
|
| 125 |
+
|
| 126 |
+
- 不支持交错的图像和文本,且不使用自定义提示的VLM:[[模型] 支持 glm-4v-9b](https://github.com/open-compass/VLMEvalKit/pull/221)
|
| 127 |
+
- 支持交错的图像和文本及自定义提示的VLM:[添加 MiniCPM-Llama3-V-2.5](https://github.com/open-compass/VLMEvalKit/pull/205)
|
| 128 |
+
- VLM API:[特征添加 glmv](https://github.com/open-compass/VLMEvalKit/pull/201)
|
| 129 |
+
|
| 130 |
+
## 为 VLMEvalKit 贡献代码
|
| 131 |
+
|
| 132 |
+
如果你想为 **VLMEvalKit** 贡献代码,请在提交PR之前进行预提交检查。这有助于保持代码整洁。
|
| 133 |
+
|
| 134 |
+
```bash
|
| 135 |
+
# 在VLMEvalKit的目录下,安装预提交 hook:
|
| 136 |
+
pip install pre-commit
|
| 137 |
+
pre-commit install
|
| 138 |
+
pre-commit run --all-files
|
| 139 |
+
# 然后提交你的代码。
|
| 140 |
+
```
|
docs/zh-CN/Makefile
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SOURCEDIR = .
|
| 9 |
+
BUILDDIR = _build
|
| 10 |
+
|
| 11 |
+
# Put it first so that "make" without argument is like "make help".
|
| 12 |
+
help:
|
| 13 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 14 |
+
|
| 15 |
+
.PHONY: help Makefile
|
| 16 |
+
|
| 17 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 18 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 19 |
+
%: Makefile
|
| 20 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
docs/zh-CN/Quickstart.md
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 快速开始
|
| 2 |
+
|
| 3 |
+
在运行评测脚本之前,你需要先**配置** VLMs,并正确设置模型路径。然后你可以使用脚本 `run.py` 进行多个VLMs和基准测试的推理和评估。
|
| 4 |
+
|
| 5 |
+
## 第0步 安装和设置必要的密钥
|
| 6 |
+
|
| 7 |
+
**安装**
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
git clone https://github.com/open-compass/VLMEvalKit.git
|
| 11 |
+
cd VLMEvalKit
|
| 12 |
+
pip install -e .
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
**设置密钥**
|
| 16 |
+
|
| 17 |
+
要使用 API 模型(如 GPT-4v, Gemini-Pro-V 等)进行推理,或使用 LLM API 作为**评判者或选择提取器**,你需要首先设置 API 密钥。如果你设置了密钥,VLMEvalKit 将使用一个评判 LLM 从输出中提取答案,否则它将使用**精确匹配模式**(在输出字符串中查找 "Yes", "No", "A", "B", "C"...)。**精确匹配模式只能应用于是或否任务和多项选择任务。**
|
| 18 |
+
|
| 19 |
+
- 你可以将所需的密钥放在 `$VLMEvalKit/.env` 中,或直接将它们设置为环境变量。如果你选择创建 `.env` 文件,其内容将如下所示:
|
| 20 |
+
|
| 21 |
+
```bash
|
| 22 |
+
# .env 文件,将其放置在 $VLMEvalKit 下
|
| 23 |
+
# 专有 VLMs 的 API 密钥
|
| 24 |
+
# QwenVL APIs
|
| 25 |
+
DASHSCOPE_API_KEY=
|
| 26 |
+
# Gemini w. Google Cloud Backends
|
| 27 |
+
GOOGLE_API_KEY=
|
| 28 |
+
# OpenAI API
|
| 29 |
+
OPENAI_API_KEY=
|
| 30 |
+
OPENAI_API_BASE=
|
| 31 |
+
# StepAI API
|
| 32 |
+
STEPAI_API_KEY=
|
| 33 |
+
# REKA API
|
| 34 |
+
REKA_API_KEY=
|
| 35 |
+
# GLMV API
|
| 36 |
+
GLMV_API_KEY=
|
| 37 |
+
# CongRong API
|
| 38 |
+
CW_API_BASE=
|
| 39 |
+
CW_API_KEY=
|
| 40 |
+
# SenseChat-V API
|
| 41 |
+
SENSECHAT_AK=
|
| 42 |
+
SENSECHAT_SK=
|
| 43 |
+
# Hunyuan-Vision API
|
| 44 |
+
HUNYUAN_SECRET_KEY=
|
| 45 |
+
HUNYUAN_SECRET_ID=
|
| 46 |
+
# 你可以设置一个评估时代理,评估阶段产生的 API 调用将通过这个代理进行
|
| 47 |
+
EVAL_PROXY=
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
- 如果需要使用 API 在对应键值空白处填写上你的密钥。这些 API 密钥将在进行推理和评估时自动加载。
|
| 51 |
+
## 第1步 配置
|
| 52 |
+
|
| 53 |
+
**VLM 配置**:所有 VLMs 都在 `vlmeval/config.py` 中配置。对于某些 VLMs(如 MiniGPT-4、LLaVA-v1-7B),需要额外的配置(在配置文件中配置代码 / 模型权重根目录)。在评估时,你应该使用 `vlmeval/config.py` 中 `supported_VLM` 指定的模型名称来选择 VLM。确保在开始评估之前,你可以成功使用 VLM 进行推理,使用以下命令 `vlmutil check {MODEL_NAME}`。
|
| 54 |
+
|
| 55 |
+
## 第2步 评测
|
| 56 |
+
|
| 57 |
+
**新功能!!!** 我们集成了一个新的配置系统,以实现更灵活的评估设置。查看[文档](/docs/zh-CN/ConfigSystem.md)或运行`python run.py --help`了解更多详情 🔥🔥🔥
|
| 58 |
+
|
| 59 |
+
我们使用 `run.py` 进行评估。你可以使用 `$VLMEvalKit/run.py` 或创建脚本的软链接运行(以便在任何地方使用该脚本):
|
| 60 |
+
|
| 61 |
+
**参数**
|
| 62 |
+
|
| 63 |
+
- `--data (list[str])`: 设置在 VLMEvalKit 中支持的数据集名称(可以在代码库首页的 README 中找到支持的数据集列表)
|
| 64 |
+
- `--model (list[str])`: 设置在 VLMEvalKit 中支持的 VLM 名称(在 `vlmeval/config.py` 中的 `supported_VLM` 中定义)
|
| 65 |
+
- `--mode (str, 默认值为 'all', 可选值为 ['all', 'infer'])`:当 mode 设置为 "all" 时,将执行推理和评估;当设置为 "infer" 时,只执行推理
|
| 66 |
+
- `--nproc (int, 默认值为 4)`: 调用 API 的线程数
|
| 67 |
+
- `--work-dir (str, default to '.')`: 存放测试结果的目录
|
| 68 |
+
- `--nframe (int, default to 8)`: 从视频中采样的帧数,仅对视频多模态评测集适用
|
| 69 |
+
- `--pack (bool, store_true)`: 一个视频可能关联多个问题,如 `pack==True`,将会在一次询问中提问所有问题
|
| 70 |
+
|
| 71 |
+
**用于评测图像多模态评测集的命令**
|
| 72 |
+
|
| 73 |
+
你可以使用 `python` 或 `torchrun` 来运行脚本:
|
| 74 |
+
|
| 75 |
+
```bash
|
| 76 |
+
# 使用 `python` 运行时,只实例化一个 VLM,并且它可能使用多个 GPU。
|
| 77 |
+
# 这推荐用于评估参数量非常大的 VLMs(如 IDEFICS-80B-Instruct)。
|
| 78 |
+
|
| 79 |
+
# 在 MMBench_DEV_EN、MME 和 SEEDBench_IMG 上使用 IDEFICS-80B-Instruct 进行推理和评估
|
| 80 |
+
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose
|
| 81 |
+
# 在 MMBench_DEV_EN、MME 和 SEEDBench_IMG 上使用 IDEFICS-80B-Instruct 仅进行推理
|
| 82 |
+
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose --mode infer
|
| 83 |
+
|
| 84 |
+
# 使用 `torchrun` 运行时,每个 GPU 上实例化一个 VLM 实例。这可以加快推理速度。
|
| 85 |
+
# 但是,这仅适用于消耗少量 GPU 内存的 VLMs。
|
| 86 |
+
|
| 87 |
+
# 在 MMBench_DEV_EN、MME 和 SEEDBench_IMG 上使用 IDEFICS-9B-Instruct、Qwen-VL-Chat、mPLUG-Owl2。在具有 8 个 GPU 的节点上进行推理和评估。
|
| 88 |
+
torchrun --nproc-per-node=8 run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct qwen_chat mPLUG-Owl2 --verbose
|
| 89 |
+
# 在 MME 上使用 Qwen-VL-Chat。在具有 2 个 GPU 的节点上进行推理和评估。
|
| 90 |
+
torchrun --nproc-per-node=2 run.py --data MME --model qwen_chat --verbose
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
**用于评测视频多模态评测集的命令**
|
| 94 |
+
|
| 95 |
+
```bash
|
| 96 |
+
# 使用 `python` 运行时,只实例化一个 VLM,并且它可能使用多个 GPU。
|
| 97 |
+
# 这推荐用于评估参数量非常大的 VLMs(如 IDEFICS-80B-Instruct)。
|
| 98 |
+
|
| 99 |
+
# 在 MMBench-Video 上评测 IDEFCIS2-8B, 视频采样 8 帧作为输入��不采用 pack 模式评测
|
| 100 |
+
torchrun --nproc-per-node=8 run.py --data MMBench-Video --model idefics2_8b --nframe 8
|
| 101 |
+
# 在 MMBench-Video 上评测 GPT-4o (API 模型), 视频采样 16 帧作为输入,采用 pack 模式评测
|
| 102 |
+
python run.py --data MMBench-Video --model GPT4o --nframe 16 --pack
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
评估结果将作为日志打印出来。此外,**结果文件**也会在目录 `$YOUR_WORKING_DIRECTORY/{model_name}` 中生成。以 `.csv` 结尾的文件包含评估的指标。
|
| 106 |
+
|
| 107 |
+
### 部署本地语言模型作为评判 / 选择提取器
|
| 108 |
+
上述默认设置使用 OpenAI 的 GPT 作为评判 LLM。你也可以使用 [LMDeploy](https://github.com/InternLM/lmdeploy) 部署本地评判 LLM。
|
| 109 |
+
|
| 110 |
+
首先进行安装:
|
| 111 |
+
```
|
| 112 |
+
pip install lmdeploy openai
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
然后可以通过一行代码部署本地评判 LLM。LMDeploy 将自动从 Huggingface 下载模型。假设我们使用 internlm2-chat-1_8b 作为评判,端口为 23333,密钥为 sk-123456(密钥必须以 "sk-" 开头,后跟任意数字):
|
| 116 |
+
```
|
| 117 |
+
lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
使用以下 Python 代码获取由 LMDeploy 注册的模型名称:
|
| 121 |
+
```
|
| 122 |
+
from openai import OpenAI
|
| 123 |
+
client = OpenAI(
|
| 124 |
+
api_key='sk-123456',
|
| 125 |
+
base_url="http://0.0.0.0:23333/v1"
|
| 126 |
+
)
|
| 127 |
+
model_name = client.models.list().data[0].id
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
配置对应环境变量,以告诉 VLMEvalKit 如何使用本地评判 LLM。正如上面提到的,也可以在 `$VLMEvalKit/.env` 文件中设置:
|
| 131 |
+
```
|
| 132 |
+
OPENAI_API_KEY=sk-123456
|
| 133 |
+
OPENAI_API_BASE=http://0.0.0.0:23333/v1/chat/completions
|
| 134 |
+
LOCAL_LLM=<model_name you get>
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
最后,你可以运行第2步中的命令,使用本地评判 LLM 来评估你的 VLM。
|
| 138 |
+
|
| 139 |
+
**请注意:**
|
| 140 |
+
|
| 141 |
+
- 如果你希望将评判 LLM 部署在单独的一个 GPU 上,并且由于 GPU 内存有限而希望在其他 GPU 上评估你的 VLM,可以使用 `CUDA_VISIBLE_DEVICES=x` 这样的方法,例如:
|
| 142 |
+
```
|
| 143 |
+
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333
|
| 144 |
+
CUDA_VISIBLE_DEVICES=1,2,3 torchrun --nproc-per-node=3 run.py --data HallusionBench --model qwen_chat --verbose
|
| 145 |
+
```
|
| 146 |
+
- 如果本地评判 LLM 在遵循指令方面不够好,评估过程可能会失败。请通过 issues 报告此类失败情况。
|
| 147 |
+
- 可以以不同的方式部署评判 LLM,例如使用私有 LLM(而非来自 HuggingFace)或使用量化 LLM。请参考 [LMDeploy doc](https://lmdeploy.readthedocs.io/en/latest/serving/api_server.html) 文档。也可以使用其他支持 OpenAI API 框架的方法。
|
docs/zh-CN/README_zh-CN.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
<b>VLMEvalKit: 一种多模态大模型评测工具 </b>
|
| 6 |
+
|
| 7 |
+
[![][github-contributors-shield]][github-contributors-link] • [![][github-forks-shield]][github-forks-link] • [![][github-stars-shield]][github-stars-link] • [![][github-issues-shield]][github-issues-link] • [![][github-license-shield]][github-license-link]
|
| 8 |
+
|
| 9 |
+
[English](/README.md) | 简体中文 | [日本語](/docs/ja/README_ja.md)
|
| 10 |
+
|
| 11 |
+
<a href="https://rank.opencompass.org.cn/leaderboard-multimodal">🏆 OpenCompass 排行榜 </a> •
|
| 12 |
+
<a href="#%EF%B8%8F-quickstart">🏗️ 快速开始 </a> •
|
| 13 |
+
<a href="#-datasets-models-and-evaluation-results">📊 数据集和模型 </a> •
|
| 14 |
+
<a href="#%EF%B8%8F-development-guide">🛠️ 开发指南 </a> •
|
| 15 |
+
<a href="#-the-goal-of-vlmevalkit">🎯 我们的目标 </a> •
|
| 16 |
+
<a href="#%EF%B8%8F-citation">🖊️ 引用 </a>
|
| 17 |
+
|
| 18 |
+
<a href="https://huggingface.co/spaces/opencompass/open_vlm_leaderboard">🤗 HuggingFace 排行榜 (存档全部性能) </a> •
|
| 19 |
+
<a href="https://huggingface.co/datasets/VLMEval/OpenVLMRecords">🤗 原始评测记录</a> •
|
| 20 |
+
<a href="https://discord.gg/evDT4GZmxN">🔊 Discord</a> •
|
| 21 |
+
<a href="https://www.arxiv.org/abs/2407.11691">📝 技术报告 </a>
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
**VLMEvalKit** (python 包名为 **vlmeval**) 是一款专为大型视觉语言模型 (Large Vision-Language Models, LVLMs) 评测而设计的开源工具包。该工具支持在各种基准测试上对大型视觉语言模型进行**一键评估**,无需进行繁重的数据准备工作,让评估过程更加简便。在 VLMEvalKit 中,我们对所有大型视觉语言模型生成的结果进行评测,并提供基于**精确匹配**与基于 **LLM 的答案提取**两种评测结果。
|
| 25 |
+
|
| 26 |
+
## 🆕 更新
|
| 27 |
+
|
| 28 |
+
- **[2024-11-21]** 集成了一个新的配置系统,以实现更灵活的评估设置。查看[文档](/docs/zh-CN/ConfigSystem.md)或运行`python run.py --help`了解更多详情 🔥🔥🔥
|
| 29 |
+
- **[2024-11-21]** 支持 **[QSpatial](https://andrewliao11.github.io/spatial_prompt/)**,一个用于定量空间推理的多模态基准(例如,确定大小/距离),感谢 **[andrewliao11](https://github.com/andrewliao11)** 提供官方支持 🔥🔥🔥
|
| 30 |
+
- **[2024-11-21]** 支持 **[MM-Math](https://github.com/kge-sun/mm-math)**,一个包含约6K初中多模态推理数学问题的新多模态数学基准。GPT-4o-20240806在该基准上达到了22.5%的准确率 🔥🔥🔥
|
| 31 |
+
- **[2024-11-16]** 支持 **[OlympiadBench](https://github.com/OpenBMB/OlympiadBench)**,一个多模态基准,包含奥林匹克级别的数学和物理问题 🔥🔥🔥
|
| 32 |
+
- **[2024-11-16]** 支持 **[WildVision](https://huggingface.co/datasets/WildVision/wildvision-bench)**,一个基于多模态竞技场数据的主观多模态基准 🔥🔥🔥
|
| 33 |
+
- **[2024-11-13]** 支持 **[MIA-Bench](https://arxiv.org/abs/2407.01509)**,一个多模态指令跟随基准 🔥🔥🔥
|
| 34 |
+
- **[2024-11-08]** 支持 **[Aria](https://arxiv.org/abs/2410.05993)**,一个多模态原生 MoE 模型,感谢 **[teowu](https://github.com/teowu)** 🔥🔥🔥
|
| 35 |
+
- **[2024-11-04]** 支持 **[WorldMedQA-V](https://www.arxiv.org/abs/2410.12722)**,该基准包含 1000 多个医学 VQA 问题,涵盖巴西、以色列、日本、西班牙等四个国家的语言,以及它们的英文翻译 🔥🔥🔥
|
| 36 |
+
- **[2024-11-01]** 支持 `AUTO_SPLIT` 标志 (https://github.com/open-compass/VLMEvalKit/pull/566),用于在低配置 GPU 上进行评估。设置后,模型将自动拆分到多个 GPU(流水线并行)以减少 GPU 内存使用(目前仅支持部分 VLMs:Qwen2-VL、Llama-3.2、LLaVA-OneVision 等) 🔥🔥🔥
|
| 37 |
+
- **[2024-10-30]** 支持评估 **[MLVU](https://github.com/JUNJIE99/MLVU)** 和 **[TempCompass](https://arxiv.org/abs/2403.00476v1)**。这两个基准将很快被纳入 **[OpenVLM 视频排行榜](https://huggingface.co/spaces/opencompass/openvlm_video_leaderboard)** 🔥🔥🔥
|
| 38 |
+
|
| 39 |
+
## 🏗️ 快速开始 <a id="quickstart"></a>
|
| 40 |
+
|
| 41 |
+
请参阅[**快速开始**](/docs/zh-CN/Quickstart.md)获取入门指南。
|
| 42 |
+
|
| 43 |
+
## 📊 评测结果,支持的数据集和模型 <a id="data-model-results"></a>
|
| 44 |
+
|
| 45 |
+
### 评测结果
|
| 46 |
+
|
| 47 |
+
**[OpenVLM Leaderboard](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard)**: **[下载全部细粒度测试结果](http://opencompass.openxlab.space/assets/OpenVLM.json)**.
|
| 48 |
+
|
| 49 |
+
### 支持的图文多模态评测集
|
| 50 |
+
|
| 51 |
+
- 默认情况下,我们在 [**OpenVLM Leaderboard**](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard) 提供全部测试结果
|
| 52 |
+
- 使用的缩写:`MCQ`: 单项选择题; `Y/N`: 正误判断题; `MTT`: 多轮对话评测; `MTI`: 多图输入评测
|
| 53 |
+
-
|
| 54 |
+
- | Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|
| 55 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | --------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------------- |
|
| 56 |
+
| [**MMBench Series**](https://github.com/open-compass/mmbench/): <br>MMBench, MMBench-CN, CCBench | MMBench\_DEV\_[EN/CN] <br>MMBench\_TEST\_[EN/CN]<br>MMBench\_DEV\_[EN/CN]\_V11<br>MMBench\_TEST\_[EN/CN]\_V11<br>CCBench | MCQ | [**MMStar**](https://github.com/MMStar-Benchmark/MMStar) | MMStar | MCQ |
|
| 57 |
+
| [**MME**](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation) | MME | Y/N | [**SEEDBench Series**](https://github.com/AILab-CVC/SEED-Bench) | SEEDBench_IMG <br>SEEDBench2 <br>SEEDBench2_Plus | MCQ |
|
| 58 |
+
| [**MM-Vet**](https://github.com/yuweihao/MM-Vet) | MMVet | VQA | [**MMMU**](https://mmmu-benchmark.github.io) | MMMU_[DEV_VAL/TEST] | MCQ |
|
| 59 |
+
| [**MathVista**](https://mathvista.github.io) | MathVista_MINI | VQA | [**ScienceQA_IMG**](https://scienceqa.github.io) | ScienceQA_[VAL/TEST] | MCQ |
|
| 60 |
+
| [**COCO Caption**](https://cocodataset.org) | COCO_VAL | Caption | [**HallusionBench**](https://github.com/tianyi-lab/HallusionBench) | HallusionBench | Y/N |
|
| 61 |
+
| [**OCRVQA**](https://ocr-vqa.github.io)* | OCRVQA_[TESTCORE/TEST] | VQA | [**TextVQA**](https://textvqa.org)* | TextVQA_VAL | VQA |
|
| 62 |
+
| [**ChartQA**](https://github.com/vis-nlp/ChartQA)* | ChartQA_TEST | VQA | [**AI2D**](https://allenai.org/data/diagrams) | AI2D_[TEST/TEST_NO_MASK] | MCQ |
|
| 63 |
+
| [**LLaVABench**](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) | LLaVABench | VQA | [**DocVQA**](https://www.docvqa.org)+ | DocVQA_[VAL/TEST] | VQA |
|
| 64 |
+
| [**InfoVQA**](https://www.docvqa.org/datasets/infographicvqa)+ | InfoVQA_[VAL/TEST] | VQA | [**OCRBench**](https://github.com/Yuliang-Liu/MultimodalOCR) | OCRBench | VQA |
|
| 65 |
+
| [**RealWorldQA**](https://x.ai/blog/grok-1.5v) | RealWorldQA | MCQ | [**POPE**](https://github.com/AoiDragon/POPE) | POPE | Y/N |
|
| 66 |
+
| [**Core-MM**](https://github.com/core-mm/core-mm)- | CORE_MM (MTI) | VQA | [**MMT-Bench**](https://mmt-bench.github.io) | MMT-Bench\_[VAL/ALL]<br>MMT-Bench\_[VAL/ALL]_MI | MCQ (MTI) |
|
| 67 |
+
| [**MLLMGuard**](https://github.com/Carol-gutianle/MLLMGuard) - | MLLMGuard_DS | VQA | [**AesBench**](https://github.com/yipoh/AesBench)+ | AesBench_[VAL/TEST] | MCQ |
|
| 68 |
+
| [**VCR-wiki**](https://huggingface.co/vcr-org/) + | VCR\_[EN/ZH]\_[EASY/HARD]_[ALL/500/100] | VQA | [**MMLongBench-Doc**](https://mayubo2333.github.io/MMLongBench-Doc/)+ | MMLongBench_DOC | VQA (MTI) |
|
| 69 |
+
| [**BLINK**](https://zeyofu.github.io/blink/) | BLINK | MCQ (MTI) | [**MathVision**](https://mathvision-cuhk.github.io)+ | MathVision<br>MathVision_MINI | VQA |
|
| 70 |
+
| [**MT-VQA**](https://github.com/bytedance/MTVQA) | MTVQA_TEST | VQA | [**MMDU**](https://liuziyu77.github.io/MMDU/)+ | MMDU | VQA (MTT, MTI) |
|
| 71 |
+
| [**Q-Bench1**](https://github.com/Q-Future/Q-Bench) | Q-Bench1_[VAL/TEST] | MCQ | [**A-Bench**](https://github.com/Q-Future/A-Bench) | A-Bench_[VAL/TEST] | MCQ |
|
| 72 |
+
| [**DUDE**](https://arxiv.org/abs/2305.08455)+ | DUDE | VQA (MTI) | [**SlideVQA**](https://arxiv.org/abs/2301.04883)+ | SLIDEVQA<br>SLIDEVQA_MINI | VQA (MTI) |
|
| 73 |
+
| [**TaskMeAnything ImageQA Random**](https://huggingface.co/datasets/weikaih/TaskMeAnything-v1-imageqa-random)+ | TaskMeAnything_v1_imageqa_random | MCQ | [**MMMB and Multilingual MMBench**](https://sun-hailong.github.io/projects/Parrot/)+ | MMMB\_[ar/cn/en/pt/ru/tr]<br>MMBench_dev\_[ar/cn/en/pt/ru/tr]<br>MMMB<br>MTL_MMBench_DEV<br>PS: MMMB & MTL_MMBench_DEV <br>are **all-in-one** names for 6 langs | MCQ |
|
| 74 |
+
| [**A-OKVQA**](https://arxiv.org/abs/2206.01718)+ | A-OKVQA | MCQ | [**MuirBench**](https://muirbench.github.io)+ | MUIRBench | MCQ |
|
| 75 |
+
| [**GMAI-MMBench**](https://huggingface.co/papers/2408.03361)+ | GMAI-MMBench_VAL | MCQ | [**TableVQABench**](https://arxiv.org/abs/2404.19205)+ | TableVQABench | VQA |
|
| 76 |
+
| [**MME-RealWorld**](https://arxiv.org/abs/2408.13257)+ | MME-RealWorld[-CN] | MCQ | [**HRBench**](https://arxiv.org/abs/2408.15556)+ | HRBench[4K/8K] | MCQ |
|
| 77 |
+
| [**MathVerse**](https://mathverse-cuhk.github.io/)+ | MathVerse_MINI<br/>MathVerse_MINI_Vision_Only <br/>MathVerse_MINI_Vision_Dominant<br/>MathVerse_MINI_Vision_Intensive<br/>MathVerse_MINI_Text_Lite<br/>MathVerse_MINI_Text_Dominant | VQA | [**AMBER**](https://github.com/junyangwang0410/AMBER)+ | AMBER | Y/N |
|
| 78 |
+
| [**CRPE**](https://huggingface.co/datasets/OpenGVLab/CRPE)+ | CRPE_[EXIST/RELATION] | VQA | **[MMSearch](https://mmsearch.github.io/)**$$^1$$ | - | **-** |
|
| 79 |
+
| **[R-Bench](https://arxiv.org/abs/2410.05474)**+ | R-Bench-[Dis/Ref] | MCQ | **[WorldMedQA-V](https://www.arxiv.org/abs/2410.12722)**+ | WorldMedQA-V | MCQ |
|
| 80 |
+
| **[GQA](https://cs.stanford.edu/people/dorarad/gqa/about.html)**+ | GQA_TestDev_Balanced | VQA | **[MIA-Bench](https://arxiv.org/abs/2407.01509)**+ | MIA-Bench | VQA |
|
| 81 |
+
| **[WildVision](https://huggingface.co/datasets/WildVision/wildvision-bench)**+ | WildVision | VQA | **[OlympiadBench](https://github.com/OpenBMB/OlympiadBench)** | OlympiadBench | VQA |
|
| 82 |
+
|
| 83 |
+
**\*** 我们只提供了部分模型上的测试结果,剩余模型无法在 zero-shot 设定下测试出合理的精度
|
| 84 |
+
|
| 85 |
+
**\+** 我们尚未提供这个评测集的测试结果
|
| 86 |
+
|
| 87 |
+
**\-** VLMEvalKit 仅支持这个评测集的推理,无法输出最终精度
|
| 88 |
+
|
| 89 |
+
$$^1$$ VLMEvalKit 在评测集的官方代码库中被使用
|
| 90 |
+
|
| 91 |
+
如果您设置了 API KEY,VLMEvalKit 将使用一个 **LLM** 从输出中提取答案进行匹配判断,否则它将使用**精确匹配**模式 (直接在输出字符串中查找“yes”,“no”,“A”,“B”,“C”等)。**精确匹配只能应用于是或否任务和多选择任务**
|
| 92 |
+
|
| 93 |
+
### 支持的视频多模态评测集
|
| 94 |
+
|
| 95 |
+
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|
| 96 |
+
| ------------------------------------------------------------ | -------------------------- | ------------------- | --------------------------------------------- | -------------------------- | --------- |
|
| 97 |
+
| [**MMBench-Video**](https://mmbench-video.github.io) | MMBench-Video | VQA | [**Video-MME**](https://video-mme.github.io/) | Video-MME | MCQ |
|
| 98 |
+
| [**MVBench**](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/MVBENCH.md) | MVBench/MVBench_MP4 | MCQ | **[MLVU](https://github.com/JUNJIE99/MLVU)** | MLVU | MCQ & VQA |
|
| 99 |
+
| **[TempCompass](https://arxiv.org/abs/2403.00476)** | TempCompass | MCQ & Y/N & Caption | | | |
|
| 100 |
+
|
| 101 |
+
### 支持的模型
|
| 102 |
+
|
| 103 |
+
**API 模型**
|
| 104 |
+
|
| 105 |
+
| [**GPT-4v (20231106, 20240409)**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**GPT-4o**](https://openai.com/index/hello-gpt-4o/) 🎞️🚅 | [**Gemini-1.0-Pro**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**Gemini-1.5-Pro**](https://platform.openai.com/docs/guides/vision) 🎞️🚅 | [**Step-1V**](https://www.stepfun.com/#step1v) 🎞️🚅 |
|
| 106 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------- |
|
| 107 |
+
| [**Reka-[Edge / Flash / Core]**](https://www.reka.ai)🚅 | [**Qwen-VL-[Plus / Max]**](https://huggingface.co/spaces/Qwen/Qwen-VL-Max) 🎞️🚅<br>[**Qwen-VL-[Plus / Max]-0809**](https://huggingface.co/spaces/Qwen/Qwen-VL-Max) 🎞️🚅 | [**Claude3-[Haiku / Sonnet / Opus]**](https://www.anthropic.com/news/claude-3-family) 🎞️🚅 | [**GLM-4v**](https://open.bigmodel.cn/dev/howuse/glm4v) 🚅 | [**CongRong**](https://mllm.cloudwalk.com/web) 🎞️🚅 |
|
| 108 |
+
| [**Claude3.5-Sonnet (20240620, 20241022)**](https://www.anthropic.com/news/claude-3-5-sonnet) 🎞️🚅 | [**GPT-4o-Mini**](https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/) 🎞️🚅 | [**Yi-Vision**](https://platform.lingyiwanwu.com)🎞️🚅 | [**Hunyuan-Vision**](https://cloud.tencent.com/document/product/1729)🎞️🚅 | [**BlueLM-V**](https://developers.vivo.com/) 🎞️🚅 |
|
| 109 |
+
|
| 110 |
+
**基于 PyTorch / HF 的开源模型**
|
| 111 |
+
|
| 112 |
+
| [**IDEFICS-[9B/80B/v2-8B/v3-8B]-Instruct**](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct)🚅🎞️ | [**InstructBLIP-[7B/13B]**](https://github.com/salesforce/LAVIS/blob/main/projects/instructblip/README.md) | [**LLaVA-[v1-7B/v1.5-7B/v1.5-13B]**](https://github.com/haotian-liu/LLaVA) | [**MiniGPT-4-[v1-7B/v1-13B/v2-7B]**](https://github.com/Vision-CAIR/MiniGPT-4) |
|
| 113 |
+
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
| 114 |
+
| [**mPLUG-Owl[2/3]**](https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2)🎞️ | [**OpenFlamingo-v2**](https://github.com/mlfoundations/open_flamingo)🎞️ | [**PandaGPT-13B**](https://github.com/yxuansu/PandaGPT) | [**Qwen-VL**](https://huggingface.co/Qwen/Qwen-VL)🚅🎞️ <br>[**Qwen-VL-Chat**](https://huggingface.co/Qwen/Qwen-VL-Chat)🚅🎞️ |
|
| 115 |
+
| [**VisualGLM-6B**](https://huggingface.co/THUDM/visualglm-6b)🚅 | [**InternLM-XComposer-[1/2]**](https://huggingface.co/internlm/internlm-xcomposer-7b)🚅 | [**ShareGPT4V-[7B/13B]**](https://sharegpt4v.github.io)🚅 | [**TransCore-M**](https://github.com/PCIResearch/TransCore-M) |
|
| 116 |
+
| [**LLaVA (XTuner)**](https://huggingface.co/xtuner/llava-internlm-7b)🚅 | [**CogVLM-[Chat/Llama3]**](https://huggingface.co/THUDM/cogvlm-chat-hf)🚅 | [**ShareCaptioner**](https://huggingface.co/spaces/Lin-Chen/Share-Captioner)🚅 | [**CogVLM-Grounding-Generalist**](https://huggingface.co/THUDM/cogvlm-grounding-generalist-hf)🚅 |
|
| 117 |
+
| [**Monkey**](https://github.com/Yuliang-Liu/Monkey)🚅<br>[**Monkey-Chat**](https://github.com/Yuliang-Liu/Monkey)🚅 | [**EMU2-Chat**](https://github.com/baaivision/Emu)🚅🎞️ | [**Yi-VL-[6B/34B]**](https://huggingface.co/01-ai/Yi-VL-6B) | [**MMAlaya**](https://huggingface.co/DataCanvas/MMAlaya)🚅 |
|
| 118 |
+
| [**InternLM-XComposer-2.5**](https://github.com/InternLM/InternLM-XComposer)🚅🎞️ | [**MiniCPM-[V1/V2/V2.5/V2.6]**](https://github.com/OpenBMB/MiniCPM-V)🚅🎞️ | [**OmniLMM-12B**](https://huggingface.co/openbmb/OmniLMM-12B) | [**InternVL-Chat-[V1-1/V1-2/V1-5/V2]**](https://github.com/OpenGVLab/InternVL)🚅🎞️ |
|
| 119 |
+
| [**DeepSeek-VL**](https://github.com/deepseek-ai/DeepSeek-VL/tree/main)🎞️ | [**LLaVA-NeXT**](https://llava-vl.github.io/blog/2024-01-30-llava-next/)🚅🎞️ | [**Bunny-Llama3**](https://huggingface.co/BAAI/Bunny-v1_1-Llama-3-8B-V)🚅 | [**XVERSE-V-13B**](https://github.com/xverse-ai/XVERSE-V-13B/blob/main/vxverse/models/vxverse.py) |
|
| 120 |
+
| [**PaliGemma-3B**](https://huggingface.co/google/paligemma-3b-pt-448) 🚅 | [**360VL-70B**](https://huggingface.co/qihoo360/360VL-70B) 🚅 | [**Phi-3-Vision**](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)🚅🎞️<br>[**Phi-3.5-Vision**](https://huggingface.co/microsoft/Phi-3.5-vision-instruct)🚅🎞️ | [**WeMM**](https://github.com/scenarios/WeMM)🚅 |
|
| 121 |
+
| [**GLM-4v-9B**](https://huggingface.co/THUDM/glm-4v-9b) 🚅 | [**Cambrian-[8B/13B/34B]**](https://cambrian-mllm.github.io/) | [**LLaVA-Next-[Qwen-32B]**](https://huggingface.co/lmms-lab/llava-next-qwen-32b) 🎞️ | [**Chameleon-[7B/30B]**](https://huggingface.co/facebook/chameleon-7b)🚅🎞️ |
|
| 122 |
+
| [**Video-LLaVA-7B-[HF]**](https://github.com/PKU-YuanGroup/Video-LLaVA) 🎬 | [**VILA1.5-[3B/8B/13B/40B]**](https://github.com/NVlabs/VILA/)🎞️ | [**Ovis[1.5-Llama3-8B/1.5-Gemma2-9B/1.6-Gemma2-9B/1.6-Llama3.2-3B]**](https://github.com/AIDC-AI/Ovis) 🚅🎞️ | [**Mantis-8B-[siglip-llama3/clip-llama3/Idefics2/Fuyu]**](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) 🎞️ |
|
| 123 |
+
| [**Llama-3-MixSenseV1_1**](https://huggingface.co/Zero-Vision/Llama-3-MixSenseV1_1)🚅 | [**Parrot-7B**](https://github.com/AIDC-AI/Parrot) 🚅 | [**OmChat-v2.0-13B-sinlge-beta**](https://huggingface.co/omlab/omchat-v2.0-13B-single-beta_hf) 🚅 | [**Video-ChatGPT**](https://github.com/mbzuai-oryx/Video-ChatGPT) 🎬 |
|
| 124 |
+
| [**Chat-UniVi-7B[-v1.5]**](https://github.com/PKU-YuanGroup/Chat-UniVi) 🎬 | [**LLaMA-VID-7B**](https://github.com/dvlab-research/LLaMA-VID) 🎬 | [**VideoChat2-HD**](https://huggingface.co/OpenGVLab/VideoChat2_HD_stage4_Mistral_7B) 🎬 | [**PLLaVA-[7B/13B/34B]**](https://huggingface.co/ermu2001/pllava-7b) 🎬 |
|
| 125 |
+
| [**RBDash_72b**](https://github.com/RBDash-Team/RBDash) 🚅🎞️ | [**xgen-mm-phi3-[interleave/dpo]-r-v1.5**](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-interleave-r-v1.5) 🚅🎞️ | [**Qwen2-VL-[2B/7B/72B]**](https://github.com/QwenLM/Qwen2-VL)🚅🎞️ | [**slime_[7b/8b/13b]**](https://github.com/yfzhang114/SliME)🎞️ |
|
| 126 |
+
| [**Eagle-X4-[8B/13B]**](https://github.com/NVlabs/EAGLE)🚅🎞️, <br>[**Eagle-X5-[7B/13B/34B]**](https://github.com/NVlabs/EAGLE)🚅🎞️ | [**Moondream1**](https://github.com/vikhyat/moondream)🚅, <br>[**Moondream2**](https://github.com/vikhyat/moondream)🚅 | [**XinYuan-VL-2B-Instruct**](https://huggingface.co/Cylingo/Xinyuan-VL-2B)🚅🎞️ | [**Llama-3.2-[11B/90B]-Vision-Instruct**](https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct)🚅 |
|
| 127 |
+
| [**Kosmos2**](https://huggingface.co/microsoft/kosmos-2-patch14-224)🚅 | [**H2OVL-Mississippi-[0.8B/2B]**](https://huggingface.co/h2oai/h2ovl-mississippi-2b)🚅🎞️ | **[Pixtral-12B](https://huggingface.co/mistralai/Pixtral-12B-2409)**🎞️ | **[Falcon2-VLM-11B](https://huggingface.co/tiiuae/falcon-11B-vlm)**🚅 |
|
| 128 |
+
| **[MiniMonkey](https://huggingface.co/mx262/MiniMonkey)**🚅🎞️ | **[LLaVA-OneVision](https://huggingface.co/lmms-lab/llava-onevision-qwen2-72b-ov-sft)**🚅🎞️ | **[LLaVA-Video](https://huggingface.co/collections/lmms-lab/llava-video-661e86f5e8dabc3ff793c944)**🚅🎞️ | **[Aquila-VL-2B](https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen)**🚅🎞️ |
|
| 129 |
+
| [**Mini-InternVL-Chat-[2B/4B]-V1-5**](https://github.com/OpenGVLab/InternVL)🚅🎞️ | **[InternVL2 Series](https://huggingface.co/OpenGVLab/InternVL2-8B)** 🚅🎞️ | **[Janus-1.3B](https://huggingface.co/deepseek-ai/Janus-1.3B)**🚅🎞️ | **[molmoE-1B/molmo-7B/molmo-72B](https://huggingface.co/allenai/Molmo-7B-D-0924)**🚅 |
|
| 130 |
+
| **[Points-[Yi-1.5-9B/Qwen-2.5-7B]](https://huggingface.co/WePOINTS/POINTS-Yi-1-5-9B-Chat)**🚅 | **[NVLM](https://huggingface.co/nvidia/NVLM-D-72B)**🚅 | **[VIntern](https://huggingface.co/5CD-AI/Vintern-3B-beta)**🚅🎞️ | **[Aria](https://huggingface.co/rhymes-ai/Aria)**🚅🎞️ |
|
| 131 |
+
|
| 132 |
+
🎞️ 表示支持多图片输入。
|
| 133 |
+
|
| 134 |
+
🚅 表示模型可以被直接使用,不需任何额外的配置。
|
| 135 |
+
|
| 136 |
+
🎬 表示支持视频输入。
|
| 137 |
+
|
| 138 |
+
### 其他
|
| 139 |
+
|
| 140 |
+
**Transformers 的版本推荐:**
|
| 141 |
+
|
| 142 |
+
**请注意**,某些 VLM 可能无法在某些特定的 transformers 版本下运行,我们建议使用以下设置来评估对应的VLM:
|
| 143 |
+
|
| 144 |
+
- **请用** `transformers==4.33.0` **来运行**: `Qwen series`, `Monkey series`, `InternLM-XComposer Series`, `mPLUG-Owl2`, `OpenFlamingo v2`, `IDEFICS series`, `VisualGLM`, `MMAlaya`, `ShareCaptioner`, `MiniGPT-4 series`, `InstructBLIP series`, `PandaGPT`, `VXVERSE`.
|
| 145 |
+
- **请用** `transformers==4.37.0 ` **来运行**: `LLaVA series`, `ShareGPT4V series`, `TransCore-M`, `LLaVA (XTuner)`, `CogVLM Series`, `EMU2 Series`, `Yi-VL Series`, `MiniCPM-[V1/V2]`, `OmniLMM-12B`, `DeepSeek-VL series`, `InternVL series`, `Cambrian Series`, `VILA Series`, `Llama-3-MixSenseV1_1`, `Parrot-7B`, `PLLaVA Series`.
|
| 146 |
+
- **请用** `transformers==4.40.0 ` **来运行**: `IDEFICS2`, `Bunny-Llama3`, `MiniCPM-Llama3-V2.5`, `360VL-70B`, `Phi-3-Vision`, `WeMM`.
|
| 147 |
+
- **请用** `transformers==latest` **来运行**: `LLaVA-Next series`, `PaliGemma-3B`, `Chameleon series`, `Video-LLaVA-7B-HF`, `Ovis series`, `Mantis series`, `MiniCPM-V2.6`, `OmChat-v2.0-13B-sinlge-beta`, `Idefics-3`, `GLM-4v-9B`, `VideoChat2-HD`.
|
| 148 |
+
|
| 149 |
+
**如何测试一个 VLM 是否可以正常运行:**
|
| 150 |
+
|
| 151 |
+
```python
|
| 152 |
+
from vlmeval.config import supported_VLM
|
| 153 |
+
model = supported_VLM['idefics_9b_instruct']()
|
| 154 |
+
# 前向单张图片
|
| 155 |
+
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
|
| 156 |
+
print(ret) # 这张图片上有一个带叶子的红苹果
|
| 157 |
+
# 前向多张图片
|
| 158 |
+
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
|
| 159 |
+
print(ret) # 提供的图片中有两个苹果
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
## 🛠️ 开发指南 <a id="development"></a>
|
| 163 |
+
|
| 164 |
+
要开发自定义评测数据集,支持其他 VLMs,或为 VLMEvalKit 贡献代码,请参阅[**开发指南**](/docs/zh-CN/Development_zh-CN.md)。
|
| 165 |
+
|
| 166 |
+
为激励来自社区的共享并分享相应的 credit,在下一次 report 更新中,我们将:
|
| 167 |
+
|
| 168 |
+
- 致谢所有的 contribution
|
| 169 |
+
- 具备三个或以上主要贡献 (支持新模型、评测集、或是主要特性) 的贡献者将可以加入技术报告的作者列表 。合条件的贡献者可以创建 issue 或是在 [VLMEvalKit Discord Channel](https://discord.com/invite/evDT4GZmxN) 私信 kennyutc,我们将进行跟进
|
| 170 |
+
|
| 171 |
+
## 🎯 VLMEvalKit 的目标 <a id="goal-of-vlmevalkit"></a>
|
| 172 |
+
|
| 173 |
+
**该代码库的设计目标是:**
|
| 174 |
+
|
| 175 |
+
1. 提供一个**易于使用**的**开源评估工具包**,方便研究人员和开发人员评测现有的多模态大模型,并使评测结果**易于复现**。
|
| 176 |
+
2. 使 VLM 开发人员能够轻松地评测自己的模型。在多个支持的基准测试上评估 VLM,只需实现一个 `generate_inner()` 函数,所有其他工作负载(数据下载、数据预处理、预测推理、度量计算)都由代码库处理。
|
| 177 |
+
|
| 178 |
+
**该代码库的设计目标不是:**
|
| 179 |
+
|
| 180 |
+
复现所有**第三方基准测试**原始论文中报告的准确数字。有两个相关的原因:
|
| 181 |
+
1. VLMEvalKit 对所有 VLMs 使用基于生成的评估(可选使用基于 LLM 的答案提取)。同时,一些基准测试可能官方使用不同的方法(*例如,SEEDBench 使用基于 PPL 的评估*)。对于这些基准测试,我们在相应的结果中比较两个得分。我们鼓励开发人员在代码库中支持其他评估范式。
|
| 182 |
+
2. 默认情况下,我们对所有多模态模型使用相同的提示模板来评估基准测试。同时,**一些多模态模型可能有他们特定的提示模板**(目前可能未在代码库中涵盖)。我们鼓励 VLM 的开发人员在 VLMEvalKit 中实现自己的提示模板,如果目前未覆盖。这将有助于提高可复现性。
|
| 183 |
+
|
| 184 |
+
## 🖊️ 引用 <a id="citation"></a>
|
| 185 |
+
|
| 186 |
+
如果我们的工作对您有所帮助,请考虑 **star🌟** VLMEvalKit。感谢支持!
|
| 187 |
+
|
| 188 |
+
[](https://github.com/open-compass/VLMEvalKit/stargazers)
|
| 189 |
+
|
| 190 |
+
如果您在研究中使用了 VLMEvalKit,或希望参考已发布的开源评估结果,请使用以下 BibTeX 条目以及与您使用的特定 VLM / 基准测试相对应的 BibTex 条目。
|
| 191 |
+
|
| 192 |
+
```bib
|
| 193 |
+
@misc{duan2024vlmevalkit,
|
| 194 |
+
title={VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models},
|
| 195 |
+
author={Haodong Duan and Junming Yang and Yuxuan Qiao and Xinyu Fang and Lin Chen and Yuan Liu and Xiaoyi Dong and Yuhang Zang and Pan Zhang and Jiaqi Wang and Dahua Lin and Kai Chen},
|
| 196 |
+
year={2024},
|
| 197 |
+
eprint={2407.11691},
|
| 198 |
+
archivePrefix={arXiv},
|
| 199 |
+
primaryClass={cs.CV},
|
| 200 |
+
url={https://arxiv.org/abs/2407.11691},
|
| 201 |
+
}
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
<p align="right"><a href="#top">🔝回到顶部</a></p>
|
| 205 |
+
|
| 206 |
+
[github-contributors-link]: https://github.com/open-compass/VLMEvalKit/graphs/contributors
|
| 207 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/VLMEvalKit?color=c4f042&labelColor=black&style=flat-square
|
| 208 |
+
[github-forks-link]: https://github.com/open-compass/VLMEvalKit/network/members
|
| 209 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/VLMEvalKit?color=8ae8ff&labelColor=black&style=flat-square
|
| 210 |
+
[github-issues-link]: https://github.com/open-compass/VLMEvalKit/issues
|
| 211 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/VLMEvalKit?color=ff80eb&labelColor=black&style=flat-square
|
| 212 |
+
[github-license-link]: https://github.com/open-compass/VLMEvalKit/blob/main/LICENSE
|
| 213 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/VLMEvalKit?color=white&labelColor=black&style=flat-square
|
| 214 |
+
[github-stars-link]: https://github.com/open-compass/VLMEvalKit/stargazers
|
| 215 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/VLMEvalKit?color=ffcb47&labelColor=black&style=flat-square
|
docs/zh-CN/_static/css/readthedocs.css
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.header-logo {
|
| 2 |
+
background-image: url("../image/logo.svg");
|
| 3 |
+
background-size: 275px 80px;
|
| 4 |
+
height: 80px;
|
| 5 |
+
width: 275px;
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@media screen and (min-width: 1100px) {
|
| 10 |
+
.header-logo {
|
| 11 |
+
top: -25px;
|
| 12 |
+
}
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
pre {
|
| 16 |
+
white-space: pre;
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
@media screen and (min-width: 2000px) {
|
| 20 |
+
.pytorch-content-left {
|
| 21 |
+
width: 1200px;
|
| 22 |
+
margin-left: 30px;
|
| 23 |
+
}
|
| 24 |
+
article.pytorch-article {
|
| 25 |
+
max-width: 1200px;
|
| 26 |
+
}
|
| 27 |
+
.pytorch-breadcrumbs-wrapper {
|
| 28 |
+
width: 1200px;
|
| 29 |
+
}
|
| 30 |
+
.pytorch-right-menu.scrolling-fixed {
|
| 31 |
+
position: fixed;
|
| 32 |
+
top: 45px;
|
| 33 |
+
left: 1580px;
|
| 34 |
+
}
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
article.pytorch-article section code {
|
| 39 |
+
padding: .2em .4em;
|
| 40 |
+
background-color: #f3f4f7;
|
| 41 |
+
border-radius: 5px;
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
/* Disable the change in tables */
|
| 45 |
+
article.pytorch-article section table code {
|
| 46 |
+
padding: unset;
|
| 47 |
+
background-color: unset;
|
| 48 |
+
border-radius: unset;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
table.autosummary td {
|
| 52 |
+
width: 50%
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
img.align-center {
|
| 56 |
+
display: block;
|
| 57 |
+
margin-left: auto;
|
| 58 |
+
margin-right: auto;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
article.pytorch-article p.rubric {
|
| 62 |
+
font-weight: bold;
|
| 63 |
+
}
|
docs/zh-CN/_static/image/logo.svg
ADDED
|
|
docs/zh-CN/_static/image/logo_icon.svg
ADDED
|
|
docs/zh-CN/_static/js/custom.js
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
var collapsedSections = [];
|
| 2 |
+
|
| 3 |
+
$(document).ready(function () {
|
| 4 |
+
$('.model-summary').DataTable({
|
| 5 |
+
"stateSave": false,
|
| 6 |
+
"lengthChange": false,
|
| 7 |
+
"pageLength": 20,
|
| 8 |
+
"order": []
|
| 9 |
+
});
|
| 10 |
+
});
|
docs/zh-CN/_templates/404.html
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{% extends "layout.html" %}
|
| 2 |
+
|
| 3 |
+
{% block body %}
|
| 4 |
+
|
| 5 |
+
<h1>Page Not Found</h1>
|
| 6 |
+
<p>
|
| 7 |
+
The page you are looking for cannot be found.
|
| 8 |
+
</p>
|
| 9 |
+
<p>
|
| 10 |
+
If you just switched documentation versions, it is likely that the page you were on is moved. You can look for it in
|
| 11 |
+
the content table left, or go to <a href="{{ pathto(root_doc) }}">the homepage</a>.
|
| 12 |
+
</p>
|
| 13 |
+
<!-- <p>
|
| 14 |
+
If you cannot find documentation you want, please <a
|
| 15 |
+
href="">open an issue</a> to tell us!
|
| 16 |
+
</p> -->
|
| 17 |
+
|
| 18 |
+
{% endblock %}
|
docs/zh-CN/_templates/autosummary/class.rst
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
|
| 11 |
+
..
|
| 12 |
+
autogenerated from _templates/autosummary/class.rst
|
| 13 |
+
note it does not have :inherited-members:
|
docs/zh-CN/_templates/callable.rst
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
:special-members: __call__
|
| 11 |
+
|
| 12 |
+
..
|
| 13 |
+
autogenerated from _templates/callable.rst
|
| 14 |
+
note it does not have :inherited-members:
|
docs/zh-CN/conf.py
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
# Configuration file for the Sphinx documentation builder.
|
| 3 |
+
#
|
| 4 |
+
# This file only contains a selection of the most common options. For a full
|
| 5 |
+
# list see the documentation:
|
| 6 |
+
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
| 7 |
+
|
| 8 |
+
# -- Path setup --------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 11 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 12 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 13 |
+
#
|
| 14 |
+
import os
|
| 15 |
+
import ast
|
| 16 |
+
import subprocess
|
| 17 |
+
import sys
|
| 18 |
+
|
| 19 |
+
import pytorch_sphinx_theme
|
| 20 |
+
from sphinx.builders.html import StandaloneHTMLBuilder
|
| 21 |
+
|
| 22 |
+
sys.path.insert(0, os.path.abspath('../../'))
|
| 23 |
+
|
| 24 |
+
# -- Project information -----------------------------------------------------
|
| 25 |
+
|
| 26 |
+
project = 'VLMEvalKit'
|
| 27 |
+
copyright = '2023, VLMEvalKit'
|
| 28 |
+
author = 'VLMEvalKit Authors'
|
| 29 |
+
|
| 30 |
+
# The full version, including alpha/beta/rc tags
|
| 31 |
+
version_file = '../../vlmeval/__init__.py'
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_version():
|
| 35 |
+
with open(version_file, 'r') as f:
|
| 36 |
+
file_content = f.read()
|
| 37 |
+
# Parse the file content into an abstract syntax tree (AST)
|
| 38 |
+
tree = ast.parse(file_content, filename=version_file)
|
| 39 |
+
|
| 40 |
+
# Iterate through the body of the AST, looking for an assignment to __version__
|
| 41 |
+
for node in tree.body:
|
| 42 |
+
if isinstance(node, ast.Assign):
|
| 43 |
+
for target in node.targets:
|
| 44 |
+
if isinstance(target, ast.Name) and target.id == '__version__':
|
| 45 |
+
return node.value.s
|
| 46 |
+
raise ValueError('__version__ not found')
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
release = get_version()
|
| 50 |
+
|
| 51 |
+
# -- General configuration ---------------------------------------------------
|
| 52 |
+
|
| 53 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 54 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 55 |
+
# ones.
|
| 56 |
+
extensions = [
|
| 57 |
+
'sphinx.ext.autodoc',
|
| 58 |
+
'sphinx.ext.autosummary',
|
| 59 |
+
'sphinx.ext.intersphinx',
|
| 60 |
+
'sphinx.ext.napoleon',
|
| 61 |
+
'sphinx.ext.viewcode',
|
| 62 |
+
'myst_parser',
|
| 63 |
+
'sphinx_copybutton',
|
| 64 |
+
'sphinx_tabs.tabs',
|
| 65 |
+
'notfound.extension',
|
| 66 |
+
'sphinxcontrib.jquery',
|
| 67 |
+
'sphinx_design',
|
| 68 |
+
]
|
| 69 |
+
|
| 70 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 71 |
+
templates_path = ['_templates']
|
| 72 |
+
|
| 73 |
+
# The suffix(es) of source filenames.
|
| 74 |
+
# You can specify multiple suffix as a list of string:
|
| 75 |
+
#
|
| 76 |
+
source_suffix = {
|
| 77 |
+
'.rst': 'restructuredtext',
|
| 78 |
+
'.md': 'markdown',
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
language = 'cn'
|
| 82 |
+
|
| 83 |
+
# The master toctree document.
|
| 84 |
+
root_doc = 'index'
|
| 85 |
+
html_context = {
|
| 86 |
+
'github_version': 'latest',
|
| 87 |
+
}
|
| 88 |
+
# List of patterns, relative to source directory, that match files and
|
| 89 |
+
# directories to ignore when looking for source files.
|
| 90 |
+
# This pattern also affects html_static_path and html_extra_path.
|
| 91 |
+
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
| 92 |
+
|
| 93 |
+
# -- Options for HTML output -------------------------------------------------
|
| 94 |
+
|
| 95 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 96 |
+
# a list of builtin themes.
|
| 97 |
+
#
|
| 98 |
+
html_theme = 'pytorch_sphinx_theme'
|
| 99 |
+
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
| 100 |
+
|
| 101 |
+
# Theme options are theme-specific and customize the look and feel of a theme
|
| 102 |
+
# further. For a list of options available for each theme, see the
|
| 103 |
+
# documentation.
|
| 104 |
+
# yapf: disable
|
| 105 |
+
html_theme_options = {
|
| 106 |
+
'menu': [
|
| 107 |
+
{
|
| 108 |
+
'name': 'GitHub',
|
| 109 |
+
'url': 'https://github.com/open-compass/VLMEvalKit'
|
| 110 |
+
},
|
| 111 |
+
],
|
| 112 |
+
# Specify the language of shared menu
|
| 113 |
+
'menu_lang': 'cn',
|
| 114 |
+
# Disable the default edit on GitHub
|
| 115 |
+
'default_edit_on_github': False,
|
| 116 |
+
}
|
| 117 |
+
# yapf: enable
|
| 118 |
+
|
| 119 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 120 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 121 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 122 |
+
html_static_path = ['_static']
|
| 123 |
+
html_css_files = [
|
| 124 |
+
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.css',
|
| 125 |
+
'css/readthedocs.css'
|
| 126 |
+
]
|
| 127 |
+
html_js_files = [
|
| 128 |
+
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.js',
|
| 129 |
+
'js/custom.js'
|
| 130 |
+
]
|
| 131 |
+
|
| 132 |
+
# -- Options for HTMLHelp output ---------------------------------------------
|
| 133 |
+
|
| 134 |
+
# Output file base name for HTML help builder.
|
| 135 |
+
htmlhelp_basename = 'vlmevalkitdoc'
|
| 136 |
+
|
| 137 |
+
# -- Options for LaTeX output ------------------------------------------------
|
| 138 |
+
|
| 139 |
+
latex_elements = {
|
| 140 |
+
# The paper size ('letterpaper' or 'a4paper').
|
| 141 |
+
#
|
| 142 |
+
# 'papersize': 'letterpaper',
|
| 143 |
+
|
| 144 |
+
# The font size ('10pt', '11pt' or '12pt').
|
| 145 |
+
#
|
| 146 |
+
# 'pointsize': '10pt',
|
| 147 |
+
|
| 148 |
+
# Additional stuff for the LaTeX preamble.
|
| 149 |
+
#
|
| 150 |
+
# 'preamble': '',
|
| 151 |
+
}
|
| 152 |
+
|
| 153 |
+
# Grouping the document tree into LaTeX files. List of tuples
|
| 154 |
+
# (source start file, target name, title,
|
| 155 |
+
# author, documentclass [howto, manual, or own class]).
|
| 156 |
+
latex_documents = [
|
| 157 |
+
(root_doc, 'vlmevalkit.tex', 'VLMEvalKit Documentation', author,
|
| 158 |
+
'manual'),
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
# -- Options for manual page output ------------------------------------------
|
| 162 |
+
|
| 163 |
+
# One entry per manual page. List of tuples
|
| 164 |
+
# (source start file, name, description, authors, manual section).
|
| 165 |
+
man_pages = [(root_doc, 'vlmevalkit', 'VLMEvalKit Documentation', [author],
|
| 166 |
+
1)]
|
| 167 |
+
|
| 168 |
+
# -- Options for Texinfo output ----------------------------------------------
|
| 169 |
+
|
| 170 |
+
# Grouping the document tree into Texinfo files. List of tuples
|
| 171 |
+
# (source start file, target name, title, author,
|
| 172 |
+
# dir menu entry, description, category)
|
| 173 |
+
texinfo_documents = [
|
| 174 |
+
(root_doc, 'vlmevalkit', 'VLMEvalKit Documentation', author,
|
| 175 |
+
'VLMEvalKit Authors', 'AGI evaluation toolbox and benchmark.',
|
| 176 |
+
'Miscellaneous'),
|
| 177 |
+
]
|
| 178 |
+
|
| 179 |
+
# -- Options for Epub output -------------------------------------------------
|
| 180 |
+
|
| 181 |
+
# Bibliographic Dublin Core info.
|
| 182 |
+
epub_title = project
|
| 183 |
+
|
| 184 |
+
# The unique identifier of the text. This can be a ISBN number
|
| 185 |
+
# or the project homepage.
|
| 186 |
+
#
|
| 187 |
+
# epub_identifier = ''
|
| 188 |
+
|
| 189 |
+
# A unique identification for the text.
|
| 190 |
+
#
|
| 191 |
+
# epub_uid = ''
|
| 192 |
+
|
| 193 |
+
# A list of files that should not be packed into the epub file.
|
| 194 |
+
epub_exclude_files = ['search.html']
|
| 195 |
+
|
| 196 |
+
# set priority when building html
|
| 197 |
+
StandaloneHTMLBuilder.supported_image_types = [
|
| 198 |
+
'image/svg+xml', 'image/gif', 'image/png', 'image/jpeg'
|
| 199 |
+
]
|
| 200 |
+
|
| 201 |
+
# -- Extension configuration -------------------------------------------------
|
| 202 |
+
# Ignore >>> when copying code
|
| 203 |
+
copybutton_prompt_text = r'>>> |\.\.\. '
|
| 204 |
+
copybutton_prompt_is_regexp = True
|
| 205 |
+
|
| 206 |
+
# Auto-generated header anchors
|
| 207 |
+
myst_heading_anchors = 3
|
| 208 |
+
# Enable "colon_fence" extension of myst.
|
| 209 |
+
myst_enable_extensions = ['colon_fence', 'dollarmath']
|
| 210 |
+
|
| 211 |
+
# Configuration for intersphinx
|
| 212 |
+
intersphinx_mapping = {
|
| 213 |
+
'python': ('https://docs.python.org/3', None),
|
| 214 |
+
'numpy': ('https://numpy.org/doc/stable', None),
|
| 215 |
+
'torch': ('https://pytorch.org/docs/stable/', None),
|
| 216 |
+
'mmengine': ('https://mmengine.readthedocs.io/en/latest/', None),
|
| 217 |
+
'transformers':
|
| 218 |
+
('https://huggingface.co/docs/transformers/main/en/', None),
|
| 219 |
+
}
|
| 220 |
+
napoleon_custom_sections = [
|
| 221 |
+
# Custom sections for data elements.
|
| 222 |
+
('Meta fields', 'params_style'),
|
| 223 |
+
('Data fields', 'params_style'),
|
| 224 |
+
]
|
| 225 |
+
|
| 226 |
+
# Disable docstring inheritance
|
| 227 |
+
autodoc_inherit_docstrings = False
|
| 228 |
+
# Mock some imports during generate API docs.
|
| 229 |
+
autodoc_mock_imports = ['rich', 'attr', 'einops']
|
| 230 |
+
# Disable displaying type annotations, these can be very verbose
|
| 231 |
+
autodoc_typehints = 'none'
|
| 232 |
+
|
| 233 |
+
# The not found page
|
| 234 |
+
notfound_template = '404.html'
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def builder_inited_handler(app):
|
| 238 |
+
subprocess.run(['./cp_origin_docs.sh'])
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def setup(app):
|
| 242 |
+
app.connect('builder-inited', builder_inited_handler)
|
docs/zh-CN/cp_origin_docs.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
# Copy *.md files from docs/ if it doesn't have a Chinese translation
|
| 4 |
+
|
| 5 |
+
for filename in $(find ../en/ -name '*.md' -printf "%P\n");
|
| 6 |
+
do
|
| 7 |
+
mkdir -p $(dirname $filename)
|
| 8 |
+
cp -n ../en/$filename ./$filename
|
| 9 |
+
done
|
docs/zh-CN/docutils.conf
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[html writers]
|
| 2 |
+
table_style: colwidths-auto
|
docs/zh-CN/index.rst
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
欢迎来到 VLMEvalKit 中文教程!
|
| 2 |
+
==========================================
|
| 3 |
+
|
| 4 |
+
VLMEvalKit 上手路线
|
| 5 |
+
-------------------------------
|
| 6 |
+
|
| 7 |
+
为了用户能够快速上手,我们推荐以下流程:
|
| 8 |
+
|
| 9 |
+
- 对于想要使用 VLMEvalKit 的用户,我们推荐先阅读 开始你的第一步_ 部分来设置环境,并启动一个迷你实验熟悉流程。
|
| 10 |
+
|
| 11 |
+
- 若您想进行更多模块的自定义,例如增加数据集和模型,我们提供了 进阶教程_ 。
|
| 12 |
+
|
| 13 |
+
我们始终非常欢迎用户的 PRs 和 Issues 来完善 VLMEvalKit!
|
| 14 |
+
|
| 15 |
+
.. _快速开始:
|
| 16 |
+
.. toctree::
|
| 17 |
+
:maxdepth: 1
|
| 18 |
+
:caption: 快速开始
|
| 19 |
+
|
| 20 |
+
Quickstart.md
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
.. .. _教程:
|
| 24 |
+
.. .. toctree::
|
| 25 |
+
.. :maxdepth: 1
|
| 26 |
+
.. :caption: 教程
|
| 27 |
+
|
| 28 |
+
.. user_guides/framework_overview.md
|
| 29 |
+
|
| 30 |
+
.. _进阶教程:
|
| 31 |
+
.. toctree::
|
| 32 |
+
:maxdepth: 1
|
| 33 |
+
:caption: 进阶教程
|
| 34 |
+
|
| 35 |
+
Development.md
|
| 36 |
+
ConfigSystem.md
|
| 37 |
+
|
| 38 |
+
.. .. _其他说明:
|
| 39 |
+
.. .. toctree::
|
| 40 |
+
.. :maxdepth: 1
|
| 41 |
+
.. :caption: 其他说明
|
| 42 |
+
|
| 43 |
+
.. notes/contribution_guide.md
|
| 44 |
+
|
| 45 |
+
索引与表格
|
| 46 |
+
==================
|
| 47 |
+
|
| 48 |
+
* :ref:`genindex`
|
| 49 |
+
* :ref:`search`
|
eval.sh
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL_NAME=$1
|
| 2 |
+
PORT=$2
|
| 3 |
+
eval "$(conda shell.bash hook)"
|
| 4 |
+
|
| 5 |
+
conda activate vlmeval
|
| 6 |
+
|
| 7 |
+
torchrun \
|
| 8 |
+
--nproc_per_node=4 \
|
| 9 |
+
--rdzv_endpoint=localhost:$PORT \
|
| 10 |
+
--rdzv_id=4 --rdzv_backend=c10d --nnodes=1 \
|
| 11 |
+
run.py --verbose --reuse \
|
| 12 |
+
--data COCO_VAL \
|
| 13 |
+
--model $MODEL_NAME
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# cp ./cuda-11.8/bin ./cuda/bin
|
eval_scripts/idefics_9b_instruct.sh
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
eval "$(conda shell.bash hook)"
|
| 2 |
+
|
| 3 |
+
conda activate vlmeval
|
| 4 |
+
# pip install transformers==4.33.0
|
| 5 |
+
pip install --upgrade transformers
|
| 6 |
+
|
| 7 |
+
torchrun \
|
| 8 |
+
--nproc_per_node=4 \
|
| 9 |
+
--rdzv_endpoint=localhost:6969 \
|
| 10 |
+
--rdzv_id=4 --rdzv_backend=c10d --nnodes=1 \
|
| 11 |
+
run.py --verbose --reuse \
|
| 12 |
+
--data COCO_VAL \
|
| 13 |
+
--model idefics_9b_instruct
|
| 14 |
+
|
| 15 |
+
# pip install --upgrade transformers
|
install.sh
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pip install -r requirements.txt
|
| 2 |
+
pip installl -e .
|
load_data.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models.txt
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
TransCore_M
|
| 2 |
+
PandaGPT_13B
|
| 3 |
+
flamingov2
|
| 4 |
+
VisualGLM_6b
|
| 5 |
+
mPLUG-Owl2
|
| 6 |
+
mPLUG-Owl3
|
| 7 |
+
emu2_chat
|
| 8 |
+
OmniLMM_12B
|
| 9 |
+
MGM_7B
|
| 10 |
+
Bunny-llama3-8B
|
| 11 |
+
VXVERSE
|
| 12 |
+
paligemma-3b-mix-448
|
| 13 |
+
360VL-70B
|
| 14 |
+
Llama-3-MixSenseV1_1
|
| 15 |
+
Parrot
|
| 16 |
+
OmChat
|
| 17 |
+
RBDash_72b
|
| 18 |
+
Pixtral-12B
|
| 19 |
+
Falcon2-VLM-11B
|
| 20 |
+
GPT4V
|
| 21 |
+
GPT4V_HIGH
|
| 22 |
+
GPT4V_20240409
|
| 23 |
+
GPT4V_20240409_HIGH
|
| 24 |
+
GPT4o
|
| 25 |
+
GPT4o_HIGH
|
| 26 |
+
GPT4o_20240806
|
| 27 |
+
GPT4o_20241120
|
| 28 |
+
GPT4o_MINI
|
| 29 |
+
GeminiPro1-0
|
| 30 |
+
GeminiPro1-5
|
| 31 |
+
GeminiFlash1-5
|
| 32 |
+
GeminiPro1-5-002
|
| 33 |
+
GeminiFlash1-5-002
|
| 34 |
+
QwenVLPlus
|
| 35 |
+
QwenVLMax
|
| 36 |
+
RekaEdge
|
| 37 |
+
RekaFlash
|
| 38 |
+
RekaCore
|
| 39 |
+
Step1V
|
| 40 |
+
Yi-Vision
|
| 41 |
+
Claude3V_Opus
|
| 42 |
+
Claude3V_Sonnet
|
| 43 |
+
Claude3V_Haiku
|
| 44 |
+
Claude3-5V_Sonnet
|
| 45 |
+
Claude3-5V_Sonnet_20241022
|
| 46 |
+
GLM4V_PLUS
|
| 47 |
+
CloudWalk
|
| 48 |
+
SenseChat-5-Vision
|
| 49 |
+
HunYuan-Vision
|
| 50 |
+
bailingMM
|
| 51 |
+
BlueLM_V
|
| 52 |
+
JTVL
|
| 53 |
+
Taiyi
|
| 54 |
+
TeleMM
|
| 55 |
+
llava-internlm2-7b
|
| 56 |
+
llava-internlm2-20b
|
| 57 |
+
llava-internlm-7b
|
| 58 |
+
llava-v1.5-7b-xtuner
|
| 59 |
+
llava-v1.5-13b-xtuner
|
| 60 |
+
llava-llama-3-8b
|
| 61 |
+
qwen_base
|
| 62 |
+
qwen_chat
|
| 63 |
+
monkey
|
| 64 |
+
monkey-chat
|
| 65 |
+
minimonkey
|
| 66 |
+
llava_v1.5_7b
|
| 67 |
+
llava_v1.5_13b
|
| 68 |
+
llava_v1_7b
|
| 69 |
+
sharegpt4v_7b
|
| 70 |
+
sharegpt4v_13b
|
| 71 |
+
llava_next_vicuna_7b
|
| 72 |
+
llava_next_vicuna_13b
|
| 73 |
+
llava_next_mistral_7b
|
| 74 |
+
llava_next_yi_34b
|
| 75 |
+
llava_next_llama3
|
| 76 |
+
llava_next_72b
|
| 77 |
+
llava_next_110b
|
| 78 |
+
llava_next_qwen_32b
|
| 79 |
+
llava_next_interleave_7b
|
| 80 |
+
llava_next_interleave_7b_dpo
|
| 81 |
+
llava-onevision-qwen2-0.5b-ov-hf
|
| 82 |
+
llava-onevision-qwen2-0.5b-si-hf
|
| 83 |
+
llava-onevision-qwen2-7b-ov-hf
|
| 84 |
+
llava-onevision-qwen2-7b-si-hf
|
| 85 |
+
llava_onevision_qwen2_0.5b_si
|
| 86 |
+
llava_onevision_qwen2_7b_si
|
| 87 |
+
llava_onevision_qwen2_72b_si
|
| 88 |
+
llava_onevision_qwen2_0.5b_ov
|
| 89 |
+
llava_onevision_qwen2_7b_ov
|
| 90 |
+
llava_onevision_qwen2_72b_ov
|
| 91 |
+
Aquila-VL-2B
|
| 92 |
+
llava_video_qwen2_7b
|
| 93 |
+
llava_video_qwen2_72b
|
| 94 |
+
InternVL-Chat-V1-1
|
| 95 |
+
InternVL-Chat-V1-2
|
| 96 |
+
InternVL-Chat-V1-2-Plus
|
| 97 |
+
InternVL-Chat-V1-5
|
| 98 |
+
Mini-InternVL-Chat-2B-V1-5
|
| 99 |
+
Mini-InternVL-Chat-4B-V1-5
|
| 100 |
+
InternVL2-1B
|
| 101 |
+
InternVL2-2B
|
| 102 |
+
InternVL2-4B
|
| 103 |
+
InternVL2-8B
|
| 104 |
+
InternVL2-8B-MPO
|
| 105 |
+
InternVL2-8B-MPO-CoT
|
| 106 |
+
InternVL2-26B
|
| 107 |
+
InternVL2-40B
|
| 108 |
+
InternVL2-76B
|
| 109 |
+
InternVL-mmniah
|
| 110 |
+
Yi_VL_6B
|
| 111 |
+
Yi_VL_34B
|
| 112 |
+
XComposer
|
| 113 |
+
sharecaptioner
|
| 114 |
+
XComposer2
|
| 115 |
+
XComposer2_1.8b
|
| 116 |
+
XComposer2_4KHD
|
| 117 |
+
XComposer2d5
|
| 118 |
+
MiniGPT-4-v2
|
| 119 |
+
MiniGPT-4-v1-7B
|
| 120 |
+
MiniGPT-4-v1-13B
|
| 121 |
+
idefics_9b_instruct
|
| 122 |
+
idefics_80b_instruct
|
| 123 |
+
idefics2_8b
|
| 124 |
+
Idefics3-8B-Llama3
|
| 125 |
+
instructblip_7b
|
| 126 |
+
instructblip_13b
|
| 127 |
+
deepseek_vl_7b
|
| 128 |
+
deepseek_vl_1.3b
|
| 129 |
+
Janus-1.3B
|
| 130 |
+
MiniCPM-V
|
| 131 |
+
MiniCPM-V-2
|
| 132 |
+
MiniCPM-Llama3-V-2_5
|
| 133 |
+
MiniCPM-V-2_6
|
| 134 |
+
cogvlm-grounding-generalist
|
| 135 |
+
cogvlm-chat
|
| 136 |
+
cogvlm2-llama3-chat-19B
|
| 137 |
+
glm-4v-9b
|
| 138 |
+
WeMM
|
| 139 |
+
cambrian_8b
|
| 140 |
+
cambrian_13b
|
| 141 |
+
cambrian_34b
|
| 142 |
+
chameleon_7b
|
| 143 |
+
chameleon_30b
|
| 144 |
+
Video-LLaVA-7B
|
| 145 |
+
Video-LLaVA-7B-HF
|
| 146 |
+
VideoChat2-HD
|
| 147 |
+
Chat-UniVi-7B
|
| 148 |
+
Chat-UniVi-7B-v1.5
|
| 149 |
+
LLaMA-VID-7B
|
| 150 |
+
Video-ChatGPT
|
| 151 |
+
PLLaVA-7B
|
| 152 |
+
PLLaVA-13B
|
| 153 |
+
PLLaVA-34B
|
| 154 |
+
Ovis1.5-Llama3-8B
|
| 155 |
+
Ovis1.5-Gemma2-9B
|
| 156 |
+
Ovis1.6-Gemma2-9B
|
| 157 |
+
Ovis1.6-Llama3.2-3B
|
| 158 |
+
Ovis1.6-Gemma2-27B
|
| 159 |
+
VILA1.5-3b
|
| 160 |
+
Llama-3-VILA1.5-8b
|
| 161 |
+
VILA1.5-13b
|
| 162 |
+
VILA1.5-40b
|
| 163 |
+
Mantis-8B-siglip-llama3
|
| 164 |
+
Mantis-8B-clip-llama3
|
| 165 |
+
Mantis-8B-Idefics2
|
| 166 |
+
Mantis-8B-Fuyu
|
| 167 |
+
MMAlaya
|
| 168 |
+
MMAlaya2
|
| 169 |
+
Phi-3-Vision
|
| 170 |
+
Phi-3.5-Vision
|
| 171 |
+
xgen-mm-phi3-interleave-r-v1.5
|
| 172 |
+
xgen-mm-phi3-dpo-r-v1.5
|
| 173 |
+
Qwen-VL-Max-0809
|
| 174 |
+
Qwen-VL-Plus-0809
|
| 175 |
+
Qwen2-VL-72B-Instruct
|
| 176 |
+
Qwen2-VL-7B-Instruct
|
| 177 |
+
Qwen2-VL-7B-Instruct-AWQ
|
| 178 |
+
Qwen2-VL-7B-Instruct-GPTQ-Int4
|
| 179 |
+
Qwen2-VL-7B-Instruct-GPTQ-Int8
|
| 180 |
+
Qwen2-VL-2B-Instruct
|
| 181 |
+
Qwen2-VL-2B-Instruct-AWQ
|
| 182 |
+
Qwen2-VL-2B-Instruct-GPTQ-Int4
|
| 183 |
+
Qwen2-VL-2B-Instruct-GPTQ-Int8
|
| 184 |
+
XinYuan-VL-2B-Instruct
|
| 185 |
+
Slime-7B
|
| 186 |
+
Slime-8B
|
| 187 |
+
Slime-13B
|
| 188 |
+
Eagle-X4-8B-Plus
|
| 189 |
+
Eagle-X4-13B-Plus
|
| 190 |
+
Eagle-X5-7B
|
| 191 |
+
Eagle-X5-13B
|
| 192 |
+
Eagle-X5-13B-Chat
|
| 193 |
+
Eagle-X5-34B-Chat
|
| 194 |
+
Eagle-X5-34B-Plus
|
| 195 |
+
Moondream1
|
| 196 |
+
Moondream2
|
| 197 |
+
Llama-3.2-11B-Vision-Instruct
|
| 198 |
+
LLaVA-CoT
|
| 199 |
+
Llama-3.2-90B-Vision-Instruct
|
| 200 |
+
molmoE-1B-0924
|
| 201 |
+
molmo-7B-D-0924
|
| 202 |
+
molmo-7B-O-0924
|
| 203 |
+
molmo-72B-0924
|
| 204 |
+
Kosmos2
|
| 205 |
+
POINTS-Yi-1.5-9B-Chat
|
| 206 |
+
POINTS-Qwen-2.5-7B-Chat
|
| 207 |
+
POINTSV15-Qwen-2.5-7B-Chat
|
| 208 |
+
NVLM
|
| 209 |
+
Vintern-3B-beta
|
| 210 |
+
Vintern-1B-v2
|
| 211 |
+
h2ovl-mississippi-2b
|
| 212 |
+
h2ovl-mississippi-1b
|
| 213 |
+
Aria
|
| 214 |
+
SmolVLM
|
| 215 |
+
SmolVLM-DPO
|
| 216 |
+
SmolVLM-Synthetic
|
models_candiate.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
SmolVLM
|
requirements.txt
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ipdb
|
| 2 |
+
decord
|
| 3 |
+
gradio
|
| 4 |
+
huggingface_hub
|
| 5 |
+
imageio
|
| 6 |
+
matplotlib
|
| 7 |
+
numpy
|
| 8 |
+
omegaconf
|
| 9 |
+
openai
|
| 10 |
+
opencv-python
|
| 11 |
+
openpyxl
|
| 12 |
+
pandas
|
| 13 |
+
peft
|
| 14 |
+
pillow
|
| 15 |
+
portalocker
|
| 16 |
+
protobuf
|
| 17 |
+
python-dotenv
|
| 18 |
+
requests
|
| 19 |
+
rich
|
| 20 |
+
sentencepiece
|
| 21 |
+
setuptools
|
| 22 |
+
sty
|
| 23 |
+
tabulate
|
| 24 |
+
tiktoken
|
| 25 |
+
timeout-decorator
|
| 26 |
+
torch
|
| 27 |
+
tqdm
|
| 28 |
+
transformers
|
| 29 |
+
typing_extensions
|
| 30 |
+
validators
|
| 31 |
+
xlsxwriter
|
requirements/docs.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
docutils==0.18.1
|
| 2 |
+
modelindex
|
| 3 |
+
myst-parser
|
| 4 |
+
-e git+https://github.com/open-compass/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
|
| 5 |
+
sphinx==6.1.3
|
| 6 |
+
sphinx-copybutton
|
| 7 |
+
sphinx-design
|
| 8 |
+
sphinx-notfound-page
|
| 9 |
+
sphinx-tabs
|
| 10 |
+
sphinxcontrib-jquery
|
| 11 |
+
tabulate
|
requirements_conda.txt
ADDED
|
@@ -0,0 +1,304 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This file may be used to create an environment using:
|
| 2 |
+
# $ conda create --name <env> --file <this file>
|
| 3 |
+
# platform: linux-64
|
| 4 |
+
# created-by: conda 24.9.2
|
| 5 |
+
_libgcc_mutex=0.1=conda_forge
|
| 6 |
+
_openmp_mutex=4.5=2_kmp_llvm
|
| 7 |
+
_sysroot_linux-64_curr_repodata_hack=3=haa98f57_10
|
| 8 |
+
accelerate=1.2.0=pypi_0
|
| 9 |
+
aiofiles=23.2.1=pypi_0
|
| 10 |
+
aiohappyeyeballs=2.4.4=pypi_0
|
| 11 |
+
aiohttp=3.11.10=pypi_0
|
| 12 |
+
aiosignal=1.3.1=pypi_0
|
| 13 |
+
annotated-types=0.7.0=pypi_0
|
| 14 |
+
antlr4-python3-runtime=4.9.3=pypi_0
|
| 15 |
+
anyio=4.7.0=pypi_0
|
| 16 |
+
aom=3.6.1=h59595ed_0
|
| 17 |
+
asttokens=3.0.0=pypi_0
|
| 18 |
+
async-timeout=5.0.1=pypi_0
|
| 19 |
+
attrs=24.2.0=pypi_0
|
| 20 |
+
autoawq=0.2.7.post3=pypi_0
|
| 21 |
+
av=14.0.1=pypi_0
|
| 22 |
+
blas=1.0=openblas
|
| 23 |
+
brotli-python=1.0.9=py310h6a678d5_8
|
| 24 |
+
bzip2=1.0.8=h5eee18b_6
|
| 25 |
+
ca-certificates=2024.11.26=h06a4308_0
|
| 26 |
+
certifi=2024.8.30=py310h06a4308_0
|
| 27 |
+
charset-normalizer=3.4.0=pypi_0
|
| 28 |
+
click=8.1.7=pypi_0
|
| 29 |
+
comm=0.2.2=pypi_0
|
| 30 |
+
contourpy=1.3.1=pypi_0
|
| 31 |
+
cuda-cudart=12.1.105=0
|
| 32 |
+
cuda-cupti=12.1.105=0
|
| 33 |
+
cuda-libraries=12.1.0=0
|
| 34 |
+
cuda-nvrtc=12.1.105=0
|
| 35 |
+
cuda-nvtx=12.1.105=0
|
| 36 |
+
cuda-opencl=12.4.127=0
|
| 37 |
+
cuda-runtime=12.1.0=0
|
| 38 |
+
cuda-version=11.8=hcce14f8_3
|
| 39 |
+
cudatoolkit=11.8.0=h6a678d5_0
|
| 40 |
+
cudnn=9.3.0.75=h50b6be5_1
|
| 41 |
+
cycler=0.12.1=pypi_0
|
| 42 |
+
datasets=3.2.0=pypi_0
|
| 43 |
+
debugpy=1.8.9=pypi_0
|
| 44 |
+
decorator=5.1.1=pypi_0
|
| 45 |
+
decord=0.6.0=pypi_0
|
| 46 |
+
deepspeed=0.16.1=pypi_0
|
| 47 |
+
dill=0.3.8=pypi_0
|
| 48 |
+
distro=1.9.0=pypi_0
|
| 49 |
+
docstring-parser=0.16=pypi_0
|
| 50 |
+
einops=0.8.0=pyhd8ed1ab_0
|
| 51 |
+
et-xmlfile=2.0.0=pypi_0
|
| 52 |
+
exceptiongroup=1.2.2=pypi_0
|
| 53 |
+
executing=2.1.0=pypi_0
|
| 54 |
+
fastapi=0.115.6=pypi_0
|
| 55 |
+
ffmpeg=4.4.2=gpl_hdf48244_113
|
| 56 |
+
ffmpy=0.4.0=pypi_0
|
| 57 |
+
filelock=3.16.1=pypi_0
|
| 58 |
+
fire=0.7.0=pypi_0
|
| 59 |
+
flash-attn=2.7.2=py310haeb5a82_0
|
| 60 |
+
font-ttf-dejavu-sans-mono=2.37=hd3eb1b0_0
|
| 61 |
+
font-ttf-inconsolata=2.001=hcb22688_0
|
| 62 |
+
font-ttf-source-code-pro=2.030=hd3eb1b0_0
|
| 63 |
+
font-ttf-ubuntu=0.83=h8b1ccd4_0
|
| 64 |
+
fontconfig=2.15.0=h7e30c49_1
|
| 65 |
+
fonts-anaconda=1=h8fa9717_0
|
| 66 |
+
fonts-conda-ecosystem=1=hd3eb1b0_0
|
| 67 |
+
fonttools=4.55.3=pypi_0
|
| 68 |
+
freetype=2.12.1=h267a509_2
|
| 69 |
+
frozenlist=1.5.0=pypi_0
|
| 70 |
+
fsspec=2024.9.0=pypi_0
|
| 71 |
+
giflib=5.2.2=h5eee18b_0
|
| 72 |
+
gmp=6.2.1=h295c915_3
|
| 73 |
+
gmpy2=2.1.2=py310heeb90bb_0
|
| 74 |
+
gnutls=3.7.9=hb077bed_0
|
| 75 |
+
gradio=5.8.0=pypi_0
|
| 76 |
+
gradio-client=1.5.1=pypi_0
|
| 77 |
+
h11=0.14.0=pypi_0
|
| 78 |
+
hjson=3.1.0=pypi_0
|
| 79 |
+
httpcore=1.0.7=pypi_0
|
| 80 |
+
httpx=0.28.1=pypi_0
|
| 81 |
+
huggingface-hub=0.26.5=pypi_0
|
| 82 |
+
idna=3.10=pypi_0
|
| 83 |
+
imageio=2.36.1=pypi_0
|
| 84 |
+
ipdb=0.13.13=pypi_0
|
| 85 |
+
ipykernel=6.29.5=pypi_0
|
| 86 |
+
ipython=8.30.0=pypi_0
|
| 87 |
+
jedi=0.19.2=pypi_0
|
| 88 |
+
jinja2=3.1.4=py310h06a4308_1
|
| 89 |
+
jiter=0.8.2=pypi_0
|
| 90 |
+
jsonschema=4.23.0=pypi_0
|
| 91 |
+
jsonschema-specifications=2024.10.1=pypi_0
|
| 92 |
+
jupyter-client=8.6.3=pypi_0
|
| 93 |
+
jupyter-core=5.7.2=pypi_0
|
| 94 |
+
kernel-headers_linux-64=3.10.0=h57e8cba_10
|
| 95 |
+
kiwisolver=1.4.7=pypi_0
|
| 96 |
+
lame=3.100=h7b6447c_0
|
| 97 |
+
lcms2=2.16=hb7c19ff_0
|
| 98 |
+
ld_impl_linux-64=2.40=h12ee557_0
|
| 99 |
+
lerc=4.0.0=h27087fc_0
|
| 100 |
+
libabseil=20240722.0=cxx17_h5888daf_1
|
| 101 |
+
libblas=3.9.0=25_linux64_openblas
|
| 102 |
+
libcblas=3.9.0=25_linux64_openblas
|
| 103 |
+
libcublas=12.1.0.26=0
|
| 104 |
+
libcufft=11.0.2.4=0
|
| 105 |
+
libcufile=1.9.1.3=0
|
| 106 |
+
libcurand=10.3.5.147=0
|
| 107 |
+
libcusolver=11.4.4.55=0
|
| 108 |
+
libcusparse=12.0.2.55=0
|
| 109 |
+
libdeflate=1.22=hb9d3cd8_0
|
| 110 |
+
libdrm=2.4.124=hb9d3cd8_0
|
| 111 |
+
libedit=3.1.20230828=h5eee18b_0
|
| 112 |
+
libegl=1.7.0=ha4b6fd6_2
|
| 113 |
+
libexpat=2.6.4=h5888daf_0
|
| 114 |
+
libffi=3.4.4=h6a678d5_1
|
| 115 |
+
libgcc=14.2.0=h77fa898_1
|
| 116 |
+
libgcc-ng=14.2.0=h69a702a_1
|
| 117 |
+
libgfortran=14.2.0=h69a702a_1
|
| 118 |
+
libgfortran5=14.2.0=hd5240d6_1
|
| 119 |
+
libgl=1.7.0=ha4b6fd6_2
|
| 120 |
+
libglvnd=1.7.0=ha4b6fd6_2
|
| 121 |
+
libglx=1.7.0=ha4b6fd6_2
|
| 122 |
+
libgomp=14.2.0=h77fa898_1
|
| 123 |
+
libiconv=1.17=hd590300_2
|
| 124 |
+
libidn2=2.3.4=h5eee18b_0
|
| 125 |
+
libjpeg-turbo=3.0.3=h5eee18b_0
|
| 126 |
+
liblapack=3.9.0=25_linux64_openblas
|
| 127 |
+
liblzma=5.6.3=hb9d3cd8_1
|
| 128 |
+
libmagma=2.8.0=hfdb99dd_0
|
| 129 |
+
libmagma_sparse=2.8.0=h9ddd185_0
|
| 130 |
+
libnpp=12.0.2.50=0
|
| 131 |
+
libnsl=2.0.0=h5eee18b_0
|
| 132 |
+
libnvfatbin=12.4.127=0
|
| 133 |
+
libnvjitlink=12.1.105=0
|
| 134 |
+
libnvjpeg=12.1.1.14=0
|
| 135 |
+
libopenblas=0.3.28=pthreads_h94d23a6_1
|
| 136 |
+
libpciaccess=0.18=hd590300_0
|
| 137 |
+
libpng=1.6.44=hadc24fc_0
|
| 138 |
+
libprotobuf=5.28.2=h5b01275_0
|
| 139 |
+
libsqlite=3.47.2=hee588c1_0
|
| 140 |
+
libstdcxx=14.2.0=hc0a3c3a_1
|
| 141 |
+
libstdcxx-ng=14.2.0=h4852527_1
|
| 142 |
+
libtasn1=4.19.0=h5eee18b_0
|
| 143 |
+
libtiff=4.7.0=hc4654cb_2
|
| 144 |
+
libtorch=2.5.1=cuda118_hb34f2e8_303
|
| 145 |
+
libunistring=0.9.10=h27cfd23_0
|
| 146 |
+
libuuid=2.38.1=h0b41bf4_0
|
| 147 |
+
libuv=1.49.2=hb9d3cd8_0
|
| 148 |
+
libva=2.22.0=h8a09558_1
|
| 149 |
+
libvpx=1.13.1=h6a678d5_0
|
| 150 |
+
libwebp=1.4.0=h2c329e2_0
|
| 151 |
+
libwebp-base=1.4.0=hd590300_0
|
| 152 |
+
libxcb=1.17.0=h8a09558_0
|
| 153 |
+
libxml2=2.13.5=h0d44e9d_1
|
| 154 |
+
libzlib=1.3.1=hb9d3cd8_2
|
| 155 |
+
llava=0.0.1.dev0=pypi_0
|
| 156 |
+
llvm-openmp=19.1.5=h024ca30_0
|
| 157 |
+
markdown-it-py=3.0.0=pypi_0
|
| 158 |
+
markupsafe=2.1.5=pypi_0
|
| 159 |
+
matplotlib=3.9.3=pypi_0
|
| 160 |
+
matplotlib-inline=0.1.7=pypi_0
|
| 161 |
+
mdurl=0.1.2=pypi_0
|
| 162 |
+
mistral-common=1.5.1=pypi_0
|
| 163 |
+
mistral-inference=1.5.0=pypi_0
|
| 164 |
+
mkl=2024.2.2=ha957f24_16
|
| 165 |
+
mpc=1.1.0=h10f8cd9_1
|
| 166 |
+
mpfr=4.0.2=hb69a4c5_1
|
| 167 |
+
mpmath=1.3.0=py310h06a4308_0
|
| 168 |
+
msgpack=1.1.0=pypi_0
|
| 169 |
+
multidict=6.1.0=pypi_0
|
| 170 |
+
multiprocess=0.70.16=pypi_0
|
| 171 |
+
nccl=2.23.4.1=h03a54cd_3
|
| 172 |
+
ncurses=6.4=h6a678d5_0
|
| 173 |
+
nest-asyncio=1.6.0=pypi_0
|
| 174 |
+
nettle=3.9.1=h7ab15ed_0
|
| 175 |
+
networkx=3.4.2=pypi_0
|
| 176 |
+
ninja=1.11.1.2=pypi_0
|
| 177 |
+
numpy=2.2.0=pypi_0
|
| 178 |
+
nvidia-cublas-cu12=12.4.5.8=pypi_0
|
| 179 |
+
nvidia-cuda-cupti-cu12=12.4.127=pypi_0
|
| 180 |
+
nvidia-cuda-nvrtc-cu12=12.4.127=pypi_0
|
| 181 |
+
nvidia-cuda-runtime-cu12=12.4.127=pypi_0
|
| 182 |
+
nvidia-cudnn-cu12=9.1.0.70=pypi_0
|
| 183 |
+
nvidia-cufft-cu12=11.2.1.3=pypi_0
|
| 184 |
+
nvidia-curand-cu12=10.3.5.147=pypi_0
|
| 185 |
+
nvidia-cusolver-cu12=11.6.1.9=pypi_0
|
| 186 |
+
nvidia-cusparse-cu12=12.3.1.170=pypi_0
|
| 187 |
+
nvidia-ml-py=12.560.30=pypi_0
|
| 188 |
+
nvidia-nccl-cu12=2.21.5=pypi_0
|
| 189 |
+
nvidia-nvjitlink-cu12=12.4.127=pypi_0
|
| 190 |
+
nvidia-nvtx-cu12=12.4.127=pypi_0
|
| 191 |
+
omegaconf=2.3.0=pypi_0
|
| 192 |
+
openai=1.57.3=pypi_0
|
| 193 |
+
opencv-python=4.10.0.84=pypi_0
|
| 194 |
+
openh264=2.3.1=hcb278e6_2
|
| 195 |
+
openjpeg=2.5.2=he7f1fd0_0
|
| 196 |
+
openpyxl=3.1.5=pypi_0
|
| 197 |
+
openssl=3.0.15=h5eee18b_0
|
| 198 |
+
orjson=3.10.12=pypi_0
|
| 199 |
+
p11-kit=0.24.1=hc5aa10d_0
|
| 200 |
+
packaging=24.2=pypi_0
|
| 201 |
+
pandas=2.2.3=pypi_0
|
| 202 |
+
parso=0.8.4=pypi_0
|
| 203 |
+
peft=0.14.0=pypi_0
|
| 204 |
+
pexpect=4.9.0=pypi_0
|
| 205 |
+
pillow=10.4.0=pypi_0
|
| 206 |
+
pip=24.3.1=pypi_0
|
| 207 |
+
platformdirs=4.3.6=pypi_0
|
| 208 |
+
portalocker=3.0.0=pypi_0
|
| 209 |
+
prompt-toolkit=3.0.48=pypi_0
|
| 210 |
+
propcache=0.2.1=pypi_0
|
| 211 |
+
protobuf=5.29.1=pypi_0
|
| 212 |
+
psutil=6.1.0=pypi_0
|
| 213 |
+
pthread-stubs=0.3=h0ce48e5_1
|
| 214 |
+
ptyprocess=0.7.0=pypi_0
|
| 215 |
+
pure-eval=0.2.3=pypi_0
|
| 216 |
+
py-cpuinfo=9.0.0=pypi_0
|
| 217 |
+
pyarrow=18.1.0=pypi_0
|
| 218 |
+
pycocoevalcap=1.2=pypi_0
|
| 219 |
+
pycocotools=2.0.8=pypi_0
|
| 220 |
+
pydantic=2.10.3=pypi_0
|
| 221 |
+
pydantic-core=2.27.1=pypi_0
|
| 222 |
+
pydub=0.25.1=pypi_0
|
| 223 |
+
pygments=2.18.0=pypi_0
|
| 224 |
+
pyparsing=3.2.0=pypi_0
|
| 225 |
+
pysocks=1.7.1=py310h06a4308_0
|
| 226 |
+
python=3.10.9=he550d4f_0_cpython
|
| 227 |
+
python-dateutil=2.9.0.post0=pypi_0
|
| 228 |
+
python-dotenv=1.0.1=pypi_0
|
| 229 |
+
python-multipart=0.0.19=pypi_0
|
| 230 |
+
python_abi=3.10=5_cp310
|
| 231 |
+
pytorch-cuda=12.1=ha16c6d3_6
|
| 232 |
+
pytorch-mutex=1.0=cuda
|
| 233 |
+
pytz=2024.2=pypi_0
|
| 234 |
+
pyyaml=6.0.2=pypi_0
|
| 235 |
+
pyzmq=26.2.0=pypi_0
|
| 236 |
+
qwen-vl-utils=0.0.8=pypi_0
|
| 237 |
+
readline=8.2=h5eee18b_0
|
| 238 |
+
referencing=0.35.1=pypi_0
|
| 239 |
+
regex=2024.11.6=pypi_0
|
| 240 |
+
requests=2.32.3=py310h06a4308_1
|
| 241 |
+
rich=13.9.4=pypi_0
|
| 242 |
+
rpds-py=0.22.3=pypi_0
|
| 243 |
+
ruff=0.8.3=pypi_0
|
| 244 |
+
safehttpx=0.1.6=pypi_0
|
| 245 |
+
safetensors=0.4.5=pypi_0
|
| 246 |
+
semantic-version=2.10.0=pypi_0
|
| 247 |
+
sentencepiece=0.2.0=pypi_0
|
| 248 |
+
setuptools=75.1.0=py310h06a4308_0
|
| 249 |
+
shellingham=1.5.4=pypi_0
|
| 250 |
+
simple-parsing=0.1.6=pypi_0
|
| 251 |
+
six=1.17.0=pypi_0
|
| 252 |
+
sleef=3.7=h1b44611_2
|
| 253 |
+
sniffio=1.3.1=pypi_0
|
| 254 |
+
sqlite=3.31.1=h7b6447c_0
|
| 255 |
+
stack-data=0.6.3=pypi_0
|
| 256 |
+
starlette=0.41.3=pypi_0
|
| 257 |
+
sty=1.0.6=pypi_0
|
| 258 |
+
svt-av1=1.4.1=hcb278e6_0
|
| 259 |
+
sympy=1.13.1=pypi_0
|
| 260 |
+
sysroot_linux-64=2.17=h57e8cba_10
|
| 261 |
+
tabulate=0.9.0=pypi_0
|
| 262 |
+
tbb=2021.8.0=hdb19cb5_0
|
| 263 |
+
termcolor=2.5.0=pypi_0
|
| 264 |
+
tiktoken=0.7.0=pypi_0
|
| 265 |
+
timeout-decorator=0.5.0=pypi_0
|
| 266 |
+
tk=8.6.13=noxft_h4845f30_101
|
| 267 |
+
tokenizers=0.21.0=pypi_0
|
| 268 |
+
tomli=2.2.1=pypi_0
|
| 269 |
+
tomlkit=0.13.2=pypi_0
|
| 270 |
+
torch=2.5.1=pypi_0
|
| 271 |
+
torchaudio=2.5.1=py310_cu121
|
| 272 |
+
torchvision=0.20.1=pypi_0
|
| 273 |
+
tornado=6.4.2=pypi_0
|
| 274 |
+
tqdm=4.67.1=pypi_0
|
| 275 |
+
traitlets=5.14.3=pypi_0
|
| 276 |
+
transformers=4.47.0=pypi_0
|
| 277 |
+
triton=3.1.0=pypi_0
|
| 278 |
+
typer=0.15.1=pypi_0
|
| 279 |
+
typing-extensions=4.12.2=pypi_0
|
| 280 |
+
tzdata=2024.2=pypi_0
|
| 281 |
+
urllib3=2.2.3=py310h06a4308_0
|
| 282 |
+
uvicorn=0.32.1=pypi_0
|
| 283 |
+
validators=0.34.0=pypi_0
|
| 284 |
+
vlmeval=0.1.0=dev_0
|
| 285 |
+
wayland=1.23.1=h3e06ad9_0
|
| 286 |
+
wayland-protocols=1.37=hd8ed1ab_0
|
| 287 |
+
wcwidth=0.2.13=pypi_0
|
| 288 |
+
websockets=14.1=pypi_0
|
| 289 |
+
wheel=0.44.0=py310h06a4308_0
|
| 290 |
+
x264=1!164.3095=h166bdaf_2
|
| 291 |
+
x265=3.5=h924138e_3
|
| 292 |
+
xformers=0.0.28.post3=pypi_0
|
| 293 |
+
xlsxwriter=3.2.0=pypi_0
|
| 294 |
+
xorg-libx11=1.8.10=h4f16b4b_1
|
| 295 |
+
xorg-libxau=1.0.11=hb9d3cd8_1
|
| 296 |
+
xorg-libxdmcp=1.1.5=hb9d3cd8_0
|
| 297 |
+
xorg-libxext=1.3.6=hb9d3cd8_0
|
| 298 |
+
xorg-libxfixes=6.0.1=hb9d3cd8_0
|
| 299 |
+
xxhash=3.5.0=pypi_0
|
| 300 |
+
xz=5.4.6=h5eee18b_1
|
| 301 |
+
yarl=1.18.3=pypi_0
|
| 302 |
+
zlib=1.3.1=hb9d3cd8_2
|
| 303 |
+
zstandard=0.23.0=pypi_0
|
| 304 |
+
zstd=1.5.6=ha6fb4c9_0
|