
Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- README.md +276 -0
- added_tokens.json +24 -0
- args.json +380 -0
- config.json +260 -0
- configuration_aimv2.py +63 -0
- configuration_ovis.py +204 -0
- generation_config.json +15 -0
- merges.txt +0 -0
- model.safetensors +3 -0
- modeling_aimv2.py +198 -0
- modeling_ovis.py +590 -0
- preprocessor_config.json +27 -0
- special_tokens_map.json +31 -0
- tokenizer.json +3 -0
- tokenizer_config.json +208 -0
- trainer_state.json +64 -0
- training_args.bin +3 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
datasets:
|
| 5 |
+
- AIDC-AI/Ovis-dataset
|
| 6 |
+
library_name: transformers
|
| 7 |
+
tags:
|
| 8 |
+
- MLLM
|
| 9 |
+
pipeline_tag: image-text-to-text
|
| 10 |
+
language:
|
| 11 |
+
- en
|
| 12 |
+
- zh
|
| 13 |
+
basemodel: AIDC-AI/Ovis2-2B
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# Ovis2-1B
|
| 17 |
+
<div align="center">
|
| 18 |
+
<img src=https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/3IK823BZ8w-mz_QfeYkDn.png width="30%"/>
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
<span style="color: #ED7D31; font-size: 22px;">It is recommended to use the latest version: [Ovis2.5](https://huggingface.co/collections/AIDC-AI/ovis25-689ec1474633b2aab8809335).</span>
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Introduction
|
| 25 |
+
[GitHub](https://github.com/AIDC-AI/Ovis) | [Paper](https://arxiv.org/abs/2405.20797)
|
| 26 |
+
|
| 27 |
+
We are pleased to announce the release of **Ovis2**, our latest advancement in multi-modal large language models (MLLMs). Ovis2 inherits the innovative architectural design of the Ovis series, aimed at structurally aligning visual and textual embeddings. As the successor to Ovis1.6, Ovis2 incorporates significant improvements in both dataset curation and training methodologies.
|
| 28 |
+
|
| 29 |
+
**Key Features**:
|
| 30 |
+
|
| 31 |
+
- **Small Model Performance**: Optimized training strategies enable small-scale models to achieve higher capability density, demonstrating cross-tier leading advantages.
|
| 32 |
+
|
| 33 |
+
- **Enhanced Reasoning Capabilities**: Significantly strengthens Chain-of-Thought (CoT) reasoning abilities through the combination of instruction tuning and preference learning.
|
| 34 |
+
|
| 35 |
+
- **Video and Multi-Image Processing**: Video and multi-image data are incorporated into training to enhance the ability to handle complex visual information across frames and images.
|
| 36 |
+
|
| 37 |
+
- **Multilingual Support and OCR**: Enhances multilingual OCR beyond English and Chinese and improves structured data extraction from complex visual elements like tables and charts.
|
| 38 |
+
|
| 39 |
+
<div align="center">
|
| 40 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/XB-vgzDL6FshrSNGyZvzc.png" width="100%" />
|
| 41 |
+
</div>
|
| 42 |
+
|
| 43 |
+
## Model Zoo
|
| 44 |
+
|
| 45 |
+
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|
| 46 |
+
|:-----------|:-----------------------:|:---------------------:|:-------------------------------------------------------:|:--------------------------------------------------------:|
|
| 47 |
+
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-1B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-1B) |
|
| 48 |
+
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-2B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-2B) |
|
| 49 |
+
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-4B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-4B) |
|
| 50 |
+
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-8B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-8B) |
|
| 51 |
+
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-16B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-16B) |
|
| 52 |
+
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-34B) | - |
|
| 53 |
+
|
| 54 |
+
## Performance
|
| 55 |
+
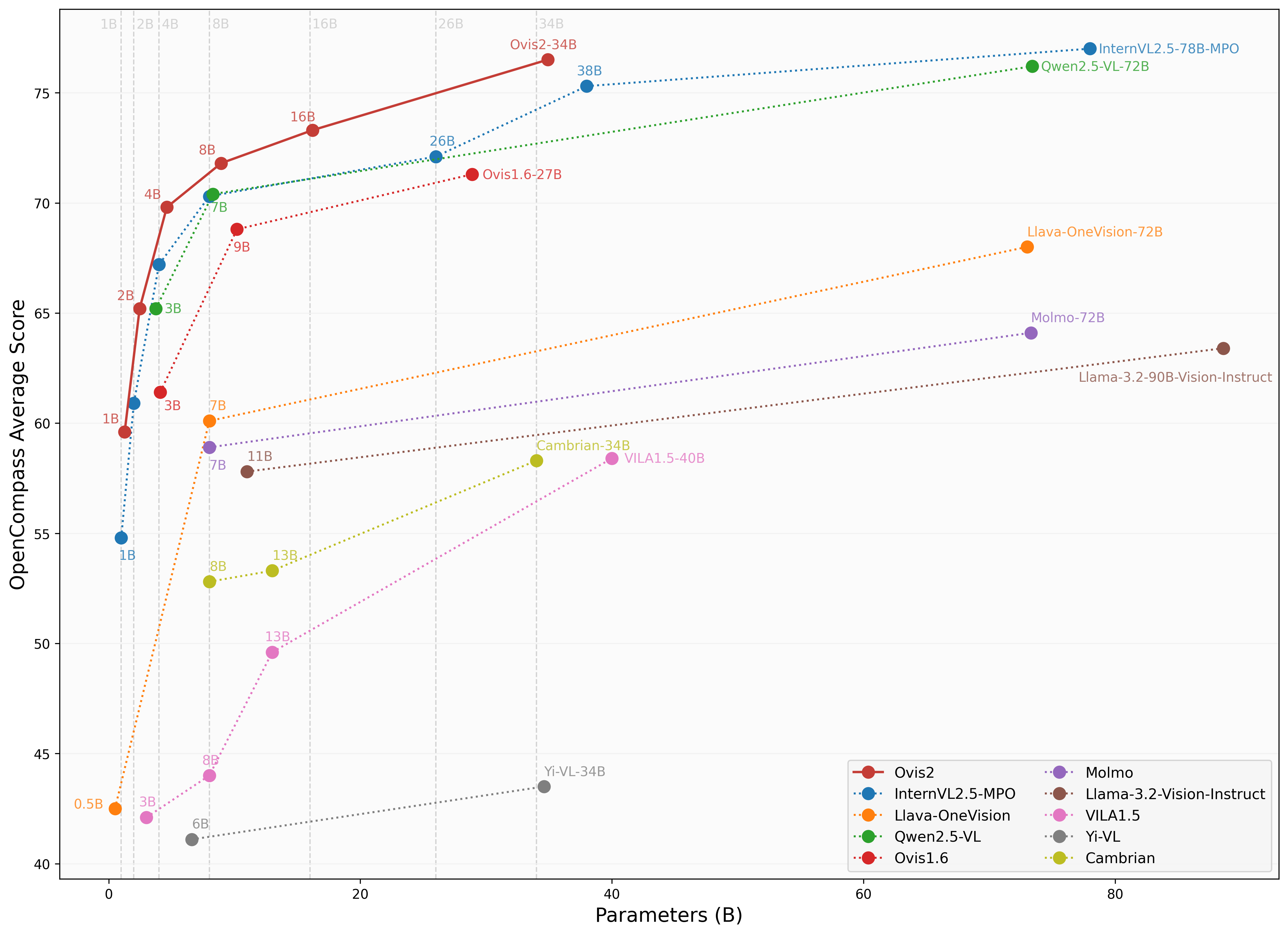
We use [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), as employed in the OpenCompass [multimodal](https://rank.opencompass.org.cn/leaderboard-multimodal) and [reasoning](https://rank.opencompass.org.cn/leaderboard-multimodal-reasoning) leaderboard, to evaluate Ovis2.
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
### Image Benchmark
|
| 60 |
+
| Benchmark | Qwen2.5-VL-3B | SAIL-VL-2B | InternVL2.5-2B-MPO | Ovis1.6-3B | InternVL2.5-1B-MPO | Ovis2-1B | Ovis2-2B |
|
| 61 |
+
|:-----------------------------|:---------------:|:------------:|:--------------------:|:------------:|:--------------------:|:----------:|:----------:|
|
| 62 |
+
| MMBench-V1.1<sub>test</sub> | **77.1** | 73.6 | 70.7 | 74.1 | 65.8 | 68.4 | 76.9 |
|
| 63 |
+
| MMStar | 56.5 | 56.5 | 54.9 | 52.0 | 49.5 | 52.1 | **56.7** |
|
| 64 |
+
| MMMU<sub>val</sub> | **51.4** | 44.1 | 44.6 | 46.7 | 40.3 | 36.1 | 45.6 |
|
| 65 |
+
| MathVista<sub>testmini</sub> | 60.1 | 62.8 | 53.4 | 58.9 | 47.7 | 59.4 | **64.1** |
|
| 66 |
+
| HallusionBench | 48.7 | 45.9 | 40.7 | 43.8 | 34.8 | 45.2 | **50.2** |
|
| 67 |
+
| AI2D | 81.4 | 77.4 | 75.1 | 77.8 | 68.5 | 76.4 | **82.7** |
|
| 68 |
+
| OCRBench | 83.1 | 83.1 | 83.8 | 80.1 | 84.3 | **89.0** | 87.3 |
|
| 69 |
+
| MMVet | 63.2 | 44.2 | **64.2** | 57.6 | 47.2 | 50.0 | 58.3 |
|
| 70 |
+
| MMBench<sub>test</sub> | 78.6 | 77 | 72.8 | 76.6 | 67.9 | 70.2 | **78.9** |
|
| 71 |
+
| MMT-Bench<sub>val</sub> | 60.8 | 57.1 | 54.4 | 59.2 | 50.8 | 55.5 | **61.7** |
|
| 72 |
+
| RealWorldQA | 66.5 | 62 | 61.3 | **66.7** | 57 | 63.9 | 66.0 |
|
| 73 |
+
| BLINK | **48.4** | 46.4 | 43.8 | 43.8 | 41 | 44.0 | 47.9 |
|
| 74 |
+
| QBench | 74.4 | 72.8 | 69.8 | 75.8 | 63.3 | 71.3 | **76.2** |
|
| 75 |
+
| ABench | 75.5 | 74.5 | 71.1 | 75.2 | 67.5 | 71.3 | **76.6** |
|
| 76 |
+
| MTVQA | 24.9 | 20.2 | 22.6 | 21.1 | 21.7 | 23.7 | **25.6** |
|
| 77 |
+
|
| 78 |
+
### Video Benchmark
|
| 79 |
+
| Benchmark | Qwen2.5-VL-3B | InternVL2.5-2B | InternVL2.5-1B | Ovis2-1B | Ovis2-2B |
|
| 80 |
+
| ------------------- |:-------------:|:--------------:|:--------------:|:---------:|:-------------:|
|
| 81 |
+
| VideoMME(wo/w-subs) | **61.5/67.6** | 51.9 / 54.1 | 50.3 / 52.3 | 48.6/49.5 | 57.2/60.8 |
|
| 82 |
+
| MVBench | 67.0 | **68.8** | 64.3 | 60.32 | 64.9 |
|
| 83 |
+
| MLVU(M-Avg/G-Avg) | 68.2/- | 61.4/- | 57.3/- | 58.5/3.66 | **68.6**/3.86 |
|
| 84 |
+
| MMBench-Video | **1.63** | 1.44 | 1.36 | 1.26 | 1.57 |
|
| 85 |
+
| TempCompass | **64.4** | - | - | 51.43 | 62.64 |
|
| 86 |
+
|
| 87 |
+
## Usage
|
| 88 |
+
Below is a code snippet demonstrating how to run Ovis with various input types. For additional usage instructions, including inference wrapper and Gradio UI, please refer to [Ovis GitHub](https://github.com/AIDC-AI/Ovis?tab=readme-ov-file#inference).
|
| 89 |
+
```bash
|
| 90 |
+
pip install numpy==1.26.4 pandas=2.2.3
|
| 91 |
+
pip install torch==2.8.0 transformers==4.51.3
|
| 92 |
+
pip install peft==0.16.0 deepspeed==0.16.5 hjson==3.1.0
|
| 93 |
+
pip install flash-attn==2.7.0.post2 --no-build-isolation
|
| 94 |
+
```
|
| 95 |
+
```python
|
| 96 |
+
import torch
|
| 97 |
+
from PIL import Image
|
| 98 |
+
from transformers import AutoModelForCausalLM
|
| 99 |
+
|
| 100 |
+
# load model
|
| 101 |
+
model = AutoModelForCausalLM.from_pretrained("Tnt3o5/Ovis2-2B-v2",
|
| 102 |
+
torch_dtype=torch.bfloat16,
|
| 103 |
+
multimodal_max_length=32768,
|
| 104 |
+
trust_remote_code=True).cuda()
|
| 105 |
+
text_tokenizer = model.get_text_tokenizer()
|
| 106 |
+
visual_tokenizer = model.get_visual_tokenizer()
|
| 107 |
+
|
| 108 |
+
# single-image input
|
| 109 |
+
image_path = '/kaggle/input/vlsp2025/train_images/train_images/train_1_3.jpg'
|
| 110 |
+
images = [Image.open(image_path)]
|
| 111 |
+
max_partition = 9
|
| 112 |
+
text = "Những loại phương tiện nào bị cấm trên đoạn đường này"
|
| 113 |
+
query = f'<image>
|
| 114 |
+
{text}'
|
| 115 |
+
|
| 116 |
+
## cot-style input
|
| 117 |
+
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
|
| 118 |
+
# image_path = '/data/images/example_1.jpg'
|
| 119 |
+
# images = [Image.open(image_path)]
|
| 120 |
+
# max_partition = 9
|
| 121 |
+
# text = "What's the area of the shape?"
|
| 122 |
+
# query = f'<image>
|
| 123 |
+
{text}
|
| 124 |
+
{cot_suffix}'
|
| 125 |
+
|
| 126 |
+
## multiple-images input
|
| 127 |
+
# image_paths = [
|
| 128 |
+
# '/data/images/example_1.jpg',
|
| 129 |
+
# '/data/images/example_2.jpg',
|
| 130 |
+
# '/data/images/example_3.jpg'
|
| 131 |
+
# ]
|
| 132 |
+
# images = [Image.open(image_path) for image_path in image_paths]
|
| 133 |
+
# max_partition = 4
|
| 134 |
+
# text = 'Describe each image.'
|
| 135 |
+
# query = '
|
| 136 |
+
'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '
|
| 137 |
+
' + text
|
| 138 |
+
|
| 139 |
+
## video input (require `pip install moviepy==1.0.3`)
|
| 140 |
+
# from moviepy.editor import VideoFileClip
|
| 141 |
+
# video_path = '/data/videos/example_1.mp4'
|
| 142 |
+
# num_frames = 12
|
| 143 |
+
# max_partition = 1
|
| 144 |
+
# text = 'Describe the video.'
|
| 145 |
+
# with VideoFileClip(video_path) as clip:
|
| 146 |
+
# total_frames = int(clip.fps * clip.duration)
|
| 147 |
+
# if total_frames <= num_frames:
|
| 148 |
+
# sampled_indices = range(total_frames)
|
| 149 |
+
# else:
|
| 150 |
+
# stride = total_frames / num_frames
|
| 151 |
+
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
|
| 152 |
+
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
|
| 153 |
+
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
|
| 154 |
+
# images = frames
|
| 155 |
+
# query = '
|
| 156 |
+
'.join(['<image>'] * len(images)) + '
|
| 157 |
+
' + text
|
| 158 |
+
|
| 159 |
+
## text-only input
|
| 160 |
+
# images = []
|
| 161 |
+
# max_partition = None
|
| 162 |
+
# text = 'Hello'
|
| 163 |
+
# query = text
|
| 164 |
+
|
| 165 |
+
# format conversation
|
| 166 |
+
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
|
| 167 |
+
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
|
| 168 |
+
input_ids = input_ids.unsqueeze(0).to(device=model.device)
|
| 169 |
+
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
|
| 170 |
+
if pixel_values is not None:
|
| 171 |
+
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
|
| 172 |
+
pixel_values = [pixel_values]
|
| 173 |
+
|
| 174 |
+
# generate output
|
| 175 |
+
with torch.inference_mode():
|
| 176 |
+
gen_kwargs = dict(
|
| 177 |
+
max_new_tokens=1024,
|
| 178 |
+
do_sample=False,
|
| 179 |
+
top_p=None,
|
| 180 |
+
top_k=None,
|
| 181 |
+
temperature=None,
|
| 182 |
+
repetition_penalty=None,
|
| 183 |
+
eos_token_id=model.generation_config.eos_token_id,
|
| 184 |
+
pad_token_id=text_tokenizer.pad_token_id,
|
| 185 |
+
use_cache=True
|
| 186 |
+
)
|
| 187 |
+
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
|
| 188 |
+
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
|
| 189 |
+
print(f'Output:
|
| 190 |
+
{output}')
|
| 191 |
+
```
|
| 192 |
+
|
| 193 |
+
<details>
|
| 194 |
+
<summary>Batch Inference</summary>
|
| 195 |
+
|
| 196 |
+
```python
|
| 197 |
+
import torch
|
| 198 |
+
from PIL import Image
|
| 199 |
+
from transformers import AutoModelForCausalLM
|
| 200 |
+
|
| 201 |
+
# load model
|
| 202 |
+
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
|
| 203 |
+
torch_dtype=torch.bfloat16,
|
| 204 |
+
multimodal_max_length=32768,
|
| 205 |
+
trust_remote_code=True).cuda()
|
| 206 |
+
text_tokenizer = model.get_text_tokenizer()
|
| 207 |
+
visual_tokenizer = model.get_visual_tokenizer()
|
| 208 |
+
|
| 209 |
+
# preprocess inputs
|
| 210 |
+
batch_inputs = [
|
| 211 |
+
('/data/images/example_1.jpg', 'What colors dominate the image?'),
|
| 212 |
+
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
|
| 213 |
+
('/data/images/example_3.jpg', 'Is there any text in the image?')
|
| 214 |
+
]
|
| 215 |
+
|
| 216 |
+
batch_input_ids = []
|
| 217 |
+
batch_attention_mask = []
|
| 218 |
+
batch_pixel_values = []
|
| 219 |
+
|
| 220 |
+
for image_path, text in batch_inputs:
|
| 221 |
+
image = Image.open(image_path)
|
| 222 |
+
query = f'<image>
|
| 223 |
+
{text}'
|
| 224 |
+
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
|
| 225 |
+
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
|
| 226 |
+
batch_input_ids.append(input_ids.to(device=model.device))
|
| 227 |
+
batch_attention_mask.append(attention_mask.to(device=model.device))
|
| 228 |
+
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
|
| 229 |
+
|
| 230 |
+
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
|
| 231 |
+
padding_value=0.0).flip(dims=[1])
|
| 232 |
+
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
|
| 233 |
+
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
|
| 234 |
+
batch_first=True, padding_value=False).flip(dims=[1])
|
| 235 |
+
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
|
| 236 |
+
|
| 237 |
+
# generate outputs
|
| 238 |
+
with torch.inference_mode():
|
| 239 |
+
gen_kwargs = dict(
|
| 240 |
+
max_new_tokens=1024,
|
| 241 |
+
do_sample=False,
|
| 242 |
+
top_p=None,
|
| 243 |
+
top_k=None,
|
| 244 |
+
temperature=None,
|
| 245 |
+
repetition_penalty=None,
|
| 246 |
+
eos_token_id=model.generation_config.eos_token_id,
|
| 247 |
+
pad_token_id=text_tokenizer.pad_token_id,
|
| 248 |
+
use_cache=True
|
| 249 |
+
)
|
| 250 |
+
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
|
| 251 |
+
**gen_kwargs)
|
| 252 |
+
|
| 253 |
+
for i in range(len(batch_inputs)):
|
| 254 |
+
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
|
| 255 |
+
print(f'Output {i + 1}:
|
| 256 |
+
{output}
|
| 257 |
+
')
|
| 258 |
+
```
|
| 259 |
+
</details>
|
| 260 |
+
|
| 261 |
+
## Citation
|
| 262 |
+
If you find Ovis useful, please consider citing the paper
|
| 263 |
+
```
|
| 264 |
+
@article{lu2024ovis,
|
| 265 |
+
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
|
| 266 |
+
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
|
| 267 |
+
year={2024},
|
| 268 |
+
journal={arXiv:2405.20797}
|
| 269 |
+
}
|
| 270 |
+
```
|
| 271 |
+
|
| 272 |
+
## License
|
| 273 |
+
This project is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) (SPDX-License-Identifier: Apache-2.0).
|
| 274 |
+
|
| 275 |
+
## Disclaimer
|
| 276 |
+
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</tool_call>": 151658,
|
| 3 |
+
"<tool_call>": 151657,
|
| 4 |
+
"<|box_end|>": 151649,
|
| 5 |
+
"<|box_start|>": 151648,
|
| 6 |
+
"<|endoftext|>": 151643,
|
| 7 |
+
"<|file_sep|>": 151664,
|
| 8 |
+
"<|fim_middle|>": 151660,
|
| 9 |
+
"<|fim_pad|>": 151662,
|
| 10 |
+
"<|fim_prefix|>": 151659,
|
| 11 |
+
"<|fim_suffix|>": 151661,
|
| 12 |
+
"<|im_end|>": 151645,
|
| 13 |
+
"<|im_start|>": 151644,
|
| 14 |
+
"<|image_pad|>": 151655,
|
| 15 |
+
"<|object_ref_end|>": 151647,
|
| 16 |
+
"<|object_ref_start|>": 151646,
|
| 17 |
+
"<|quad_end|>": 151651,
|
| 18 |
+
"<|quad_start|>": 151650,
|
| 19 |
+
"<|repo_name|>": 151663,
|
| 20 |
+
"<|video_pad|>": 151656,
|
| 21 |
+
"<|vision_end|>": 151653,
|
| 22 |
+
"<|vision_pad|>": 151654,
|
| 23 |
+
"<|vision_start|>": 151652
|
| 24 |
+
}
|
args.json
ADDED
|
@@ -0,0 +1,380 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"output_dir": "/kaggle/working/outputs/ovis_2/v1-20250825-163329",
|
| 3 |
+
"overwrite_output_dir": false,
|
| 4 |
+
"do_train": false,
|
| 5 |
+
"do_eval": false,
|
| 6 |
+
"do_predict": false,
|
| 7 |
+
"eval_strategy": "steps",
|
| 8 |
+
"prediction_loss_only": false,
|
| 9 |
+
"per_device_train_batch_size": 1,
|
| 10 |
+
"per_device_eval_batch_size": 1,
|
| 11 |
+
"per_gpu_train_batch_size": null,
|
| 12 |
+
"per_gpu_eval_batch_size": null,
|
| 13 |
+
"gradient_accumulation_steps": 16,
|
| 14 |
+
"eval_accumulation_steps": null,
|
| 15 |
+
"eval_delay": 0,
|
| 16 |
+
"torch_empty_cache_steps": null,
|
| 17 |
+
"learning_rate": 1e-05,
|
| 18 |
+
"weight_decay": 0.1,
|
| 19 |
+
"adam_beta1": 0.9,
|
| 20 |
+
"adam_beta2": 0.95,
|
| 21 |
+
"adam_epsilon": 1e-08,
|
| 22 |
+
"max_grad_norm": 1.0,
|
| 23 |
+
"num_train_epochs": 5.0,
|
| 24 |
+
"max_steps": -1,
|
| 25 |
+
"lr_scheduler_type": "cosine",
|
| 26 |
+
"lr_scheduler_kwargs": null,
|
| 27 |
+
"warmup_ratio": 0.01,
|
| 28 |
+
"warmup_steps": 0,
|
| 29 |
+
"log_level": "passive",
|
| 30 |
+
"log_level_replica": "warning",
|
| 31 |
+
"log_on_each_node": true,
|
| 32 |
+
"logging_dir": "/kaggle/working/outputs/ovis_2/v1-20250825-163329/runs",
|
| 33 |
+
"logging_strategy": "steps",
|
| 34 |
+
"logging_first_step": true,
|
| 35 |
+
"logging_steps": 20,
|
| 36 |
+
"logging_nan_inf_filter": true,
|
| 37 |
+
"save_strategy": "steps",
|
| 38 |
+
"save_steps": 20.0,
|
| 39 |
+
"save_total_limit": null,
|
| 40 |
+
"save_safetensors": true,
|
| 41 |
+
"save_on_each_node": false,
|
| 42 |
+
"save_only_model": true,
|
| 43 |
+
"restore_callback_states_from_checkpoint": false,
|
| 44 |
+
"no_cuda": false,
|
| 45 |
+
"use_cpu": false,
|
| 46 |
+
"use_mps_device": false,
|
| 47 |
+
"seed": 42,
|
| 48 |
+
"data_seed": 42,
|
| 49 |
+
"jit_mode_eval": false,
|
| 50 |
+
"use_ipex": false,
|
| 51 |
+
"bf16": true,
|
| 52 |
+
"fp16": false,
|
| 53 |
+
"fp16_opt_level": "O1",
|
| 54 |
+
"half_precision_backend": "auto",
|
| 55 |
+
"bf16_full_eval": false,
|
| 56 |
+
"fp16_full_eval": false,
|
| 57 |
+
"tf32": null,
|
| 58 |
+
"local_rank": 0,
|
| 59 |
+
"ddp_backend": null,
|
| 60 |
+
"tpu_num_cores": null,
|
| 61 |
+
"tpu_metrics_debug": false,
|
| 62 |
+
"debug": null,
|
| 63 |
+
"dataloader_drop_last": false,
|
| 64 |
+
"eval_steps": 20.0,
|
| 65 |
+
"dataloader_num_workers": 8,
|
| 66 |
+
"dataloader_prefetch_factor": null,
|
| 67 |
+
"past_index": -1,
|
| 68 |
+
"run_name": "/kaggle/working/outputs/ovis_2/v1-20250825-163329",
|
| 69 |
+
"disable_tqdm": null,
|
| 70 |
+
"remove_unused_columns": true,
|
| 71 |
+
"label_names": null,
|
| 72 |
+
"load_best_model_at_end": false,
|
| 73 |
+
"metric_for_best_model": "loss",
|
| 74 |
+
"greater_is_better": false,
|
| 75 |
+
"ignore_data_skip": false,
|
| 76 |
+
"fsdp": "",
|
| 77 |
+
"fsdp_min_num_params": 0,
|
| 78 |
+
"fsdp_config": null,
|
| 79 |
+
"tp_size": 0,
|
| 80 |
+
"fsdp_transformer_layer_cls_to_wrap": null,
|
| 81 |
+
"accelerator_config": {
|
| 82 |
+
"dispatch_batches": false
|
| 83 |
+
},
|
| 84 |
+
"deepspeed": {
|
| 85 |
+
"fp16": {
|
| 86 |
+
"enabled": "auto",
|
| 87 |
+
"loss_scale": 0,
|
| 88 |
+
"loss_scale_window": 1000,
|
| 89 |
+
"initial_scale_power": 16,
|
| 90 |
+
"hysteresis": 2,
|
| 91 |
+
"min_loss_scale": 1
|
| 92 |
+
},
|
| 93 |
+
"bf16": {
|
| 94 |
+
"enabled": "auto"
|
| 95 |
+
},
|
| 96 |
+
"zero_optimization": {
|
| 97 |
+
"stage": 3,
|
| 98 |
+
"offload_optimizer": {
|
| 99 |
+
"device": "none",
|
| 100 |
+
"pin_memory": true
|
| 101 |
+
},
|
| 102 |
+
"offload_param": {
|
| 103 |
+
"device": "none",
|
| 104 |
+
"pin_memory": true
|
| 105 |
+
},
|
| 106 |
+
"overlap_comm": false,
|
| 107 |
+
"contiguous_gradients": true,
|
| 108 |
+
"sub_group_size": 1000000000.0,
|
| 109 |
+
"reduce_bucket_size": "auto",
|
| 110 |
+
"zero_quantized_weights": false,
|
| 111 |
+
"zero_quantized_gradients": false,
|
| 112 |
+
"stage3_prefetch_bucket_size": "auto",
|
| 113 |
+
"stage3_param_persistence_threshold": "auto",
|
| 114 |
+
"stage3_max_live_parameters": 1000000000.0,
|
| 115 |
+
"stage3_max_reuse_distance": 1000000000.0,
|
| 116 |
+
"stage3_gather_16bit_weights_on_model_save": true
|
| 117 |
+
},
|
| 118 |
+
"gradient_accumulation_steps": "auto",
|
| 119 |
+
"gradient_clipping": "auto",
|
| 120 |
+
"steps_per_print": 2000,
|
| 121 |
+
"train_batch_size": "auto",
|
| 122 |
+
"train_micro_batch_size_per_gpu": "auto",
|
| 123 |
+
"wall_clock_breakdown": false
|
| 124 |
+
},
|
| 125 |
+
"label_smoothing_factor": 0.0,
|
| 126 |
+
"optim": "adamw_torch",
|
| 127 |
+
"optim_args": null,
|
| 128 |
+
"adafactor": false,
|
| 129 |
+
"group_by_length": false,
|
| 130 |
+
"length_column_name": "length",
|
| 131 |
+
"report_to": [
|
| 132 |
+
"tensorboard"
|
| 133 |
+
],
|
| 134 |
+
"ddp_find_unused_parameters": null,
|
| 135 |
+
"ddp_bucket_cap_mb": null,
|
| 136 |
+
"ddp_broadcast_buffers": null,
|
| 137 |
+
"dataloader_pin_memory": true,
|
| 138 |
+
"dataloader_persistent_workers": false,
|
| 139 |
+
"skip_memory_metrics": true,
|
| 140 |
+
"use_legacy_prediction_loop": false,
|
| 141 |
+
"push_to_hub": false,
|
| 142 |
+
"resume_from_checkpoint": null,
|
| 143 |
+
"hub_model_id": null,
|
| 144 |
+
"hub_strategy": "every_save",
|
| 145 |
+
"hub_token": null,
|
| 146 |
+
"hub_private_repo": null,
|
| 147 |
+
"hub_always_push": false,
|
| 148 |
+
"gradient_checkpointing": true,
|
| 149 |
+
"gradient_checkpointing_kwargs": null,
|
| 150 |
+
"include_inputs_for_metrics": false,
|
| 151 |
+
"include_for_metrics": [],
|
| 152 |
+
"eval_do_concat_batches": true,
|
| 153 |
+
"fp16_backend": "auto",
|
| 154 |
+
"push_to_hub_model_id": null,
|
| 155 |
+
"push_to_hub_organization": null,
|
| 156 |
+
"push_to_hub_token": null,
|
| 157 |
+
"mp_parameters": "",
|
| 158 |
+
"auto_find_batch_size": false,
|
| 159 |
+
"full_determinism": false,
|
| 160 |
+
"torchdynamo": null,
|
| 161 |
+
"ray_scope": "last",
|
| 162 |
+
"ddp_timeout": 18000000,
|
| 163 |
+
"torch_compile": false,
|
| 164 |
+
"torch_compile_backend": null,
|
| 165 |
+
"torch_compile_mode": null,
|
| 166 |
+
"include_tokens_per_second": false,
|
| 167 |
+
"include_num_input_tokens_seen": false,
|
| 168 |
+
"neftune_noise_alpha": null,
|
| 169 |
+
"optim_target_modules": null,
|
| 170 |
+
"batch_eval_metrics": false,
|
| 171 |
+
"eval_on_start": false,
|
| 172 |
+
"use_liger_kernel": false,
|
| 173 |
+
"eval_use_gather_object": false,
|
| 174 |
+
"average_tokens_across_devices": false,
|
| 175 |
+
"sortish_sampler": false,
|
| 176 |
+
"predict_with_generate": false,
|
| 177 |
+
"generation_max_length": null,
|
| 178 |
+
"generation_num_beams": null,
|
| 179 |
+
"generation_config": null,
|
| 180 |
+
"tuner_backend": "peft",
|
| 181 |
+
"vit_gradient_checkpointing": null,
|
| 182 |
+
"router_aux_loss_coef": 0.0,
|
| 183 |
+
"enable_dft_loss": false,
|
| 184 |
+
"check_model": true,
|
| 185 |
+
"acc_strategy": "token",
|
| 186 |
+
"train_dataloader_shuffle": true,
|
| 187 |
+
"max_epochs": null,
|
| 188 |
+
"aligner_lr": null,
|
| 189 |
+
"vit_lr": null,
|
| 190 |
+
"use_logits_to_keep": null,
|
| 191 |
+
"channels": null,
|
| 192 |
+
"ds3_gather_for_generation": true,
|
| 193 |
+
"resume_only_model": false,
|
| 194 |
+
"optimizer": null,
|
| 195 |
+
"loss_type": null,
|
| 196 |
+
"metric": null,
|
| 197 |
+
"eval_use_evalscope": false,
|
| 198 |
+
"eval_dataset": [],
|
| 199 |
+
"eval_dataset_args": null,
|
| 200 |
+
"eval_limit": null,
|
| 201 |
+
"eval_generation_config": null,
|
| 202 |
+
"extra_eval_args": null,
|
| 203 |
+
"use_flash_ckpt": false,
|
| 204 |
+
"model": "/kaggle/working/outputs/ovis_2/v0-20250825-145449/checkpoint-84",
|
| 205 |
+
"model_type": "ovis2",
|
| 206 |
+
"model_revision": null,
|
| 207 |
+
"task_type": "causal_lm",
|
| 208 |
+
"torch_dtype": "bfloat16",
|
| 209 |
+
"attn_impl": "flash_attn",
|
| 210 |
+
"new_special_tokens": [],
|
| 211 |
+
"num_labels": null,
|
| 212 |
+
"problem_type": null,
|
| 213 |
+
"rope_scaling": null,
|
| 214 |
+
"device_map": null,
|
| 215 |
+
"max_memory": {},
|
| 216 |
+
"max_model_len": null,
|
| 217 |
+
"local_repo_path": null,
|
| 218 |
+
"init_strategy": null,
|
| 219 |
+
"template": "ovis2",
|
| 220 |
+
"system": null,
|
| 221 |
+
"max_length": 5001,
|
| 222 |
+
"truncation_strategy": "delete",
|
| 223 |
+
"max_pixels": null,
|
| 224 |
+
"agent_template": null,
|
| 225 |
+
"norm_bbox": null,
|
| 226 |
+
"use_chat_template": true,
|
| 227 |
+
"padding_free": false,
|
| 228 |
+
"padding_side": "right",
|
| 229 |
+
"loss_scale": "default",
|
| 230 |
+
"sequence_parallel_size": 1,
|
| 231 |
+
"response_prefix": null,
|
| 232 |
+
"template_backend": "swift",
|
| 233 |
+
"dataset": [
|
| 234 |
+
"/kaggle/input/vlsp2025/qa_supervised_finetune_keywords.jsonl"
|
| 235 |
+
],
|
| 236 |
+
"val_dataset": [],
|
| 237 |
+
"split_dataset_ratio": 0.2,
|
| 238 |
+
"dataset_num_proc": 1,
|
| 239 |
+
"load_from_cache_file": true,
|
| 240 |
+
"dataset_shuffle": true,
|
| 241 |
+
"val_dataset_shuffle": false,
|
| 242 |
+
"streaming": false,
|
| 243 |
+
"interleave_prob": null,
|
| 244 |
+
"stopping_strategy": "first_exhausted",
|
| 245 |
+
"shuffle_buffer_size": 1000,
|
| 246 |
+
"download_mode": "reuse_dataset_if_exists",
|
| 247 |
+
"columns": {},
|
| 248 |
+
"strict": false,
|
| 249 |
+
"model_name": null,
|
| 250 |
+
"model_author": null,
|
| 251 |
+
"custom_dataset_info": [],
|
| 252 |
+
"quant_method": null,
|
| 253 |
+
"quant_bits": null,
|
| 254 |
+
"hqq_axis": null,
|
| 255 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 256 |
+
"bnb_4bit_quant_type": "nf4",
|
| 257 |
+
"bnb_4bit_use_double_quant": true,
|
| 258 |
+
"bnb_4bit_quant_storage": null,
|
| 259 |
+
"max_new_tokens": 64,
|
| 260 |
+
"temperature": 0.0,
|
| 261 |
+
"top_k": null,
|
| 262 |
+
"top_p": null,
|
| 263 |
+
"repetition_penalty": null,
|
| 264 |
+
"num_beams": 1,
|
| 265 |
+
"stream": false,
|
| 266 |
+
"stop_words": [],
|
| 267 |
+
"logprobs": false,
|
| 268 |
+
"top_logprobs": null,
|
| 269 |
+
"ckpt_dir": "/kaggle/working/outputs/ovis_2/v0-20250825-145449/checkpoint-84",
|
| 270 |
+
"lora_modules": [],
|
| 271 |
+
"train_type": "full",
|
| 272 |
+
"adapters": [],
|
| 273 |
+
"external_plugins": [],
|
| 274 |
+
"model_kwargs": {},
|
| 275 |
+
"load_args": false,
|
| 276 |
+
"load_data_args": false,
|
| 277 |
+
"packing": false,
|
| 278 |
+
"packing_length": null,
|
| 279 |
+
"lazy_tokenize": true,
|
| 280 |
+
"cached_dataset": [],
|
| 281 |
+
"custom_register_path": [],
|
| 282 |
+
"use_hf": true,
|
| 283 |
+
"ignore_args_error": false,
|
| 284 |
+
"use_swift_lora": false,
|
| 285 |
+
"freeze_parameters": [],
|
| 286 |
+
"freeze_parameters_regex": null,
|
| 287 |
+
"freeze_parameters_ratio": 0.0,
|
| 288 |
+
"trainable_parameters": [],
|
| 289 |
+
"trainable_parameters_regex": null,
|
| 290 |
+
"freeze_llm": false,
|
| 291 |
+
"freeze_vit": false,
|
| 292 |
+
"freeze_aligner": true,
|
| 293 |
+
"target_modules": [
|
| 294 |
+
"all-linear"
|
| 295 |
+
],
|
| 296 |
+
"target_regex": null,
|
| 297 |
+
"target_parameters": null,
|
| 298 |
+
"modules_to_save": [],
|
| 299 |
+
"lora_rank": 8,
|
| 300 |
+
"lora_alpha": 32,
|
| 301 |
+
"lora_dropout": 0.05,
|
| 302 |
+
"lora_bias": "none",
|
| 303 |
+
"lora_dtype": null,
|
| 304 |
+
"lorap_lr_ratio": null,
|
| 305 |
+
"use_rslora": false,
|
| 306 |
+
"use_dora": false,
|
| 307 |
+
"lora_ga_batch_size": 2,
|
| 308 |
+
"lora_ga_iters": 2,
|
| 309 |
+
"lora_ga_max_length": 1024,
|
| 310 |
+
"lora_ga_direction": "ArB2r",
|
| 311 |
+
"lora_ga_scale": "stable",
|
| 312 |
+
"lora_ga_stable_gamma": 16,
|
| 313 |
+
"init_weights": true,
|
| 314 |
+
"fourier_n_frequency": 2000,
|
| 315 |
+
"fourier_scaling": 300.0,
|
| 316 |
+
"boft_block_size": 4,
|
| 317 |
+
"boft_block_num": 0,
|
| 318 |
+
"boft_n_butterfly_factor": 1,
|
| 319 |
+
"boft_dropout": 0.0,
|
| 320 |
+
"vera_rank": 256,
|
| 321 |
+
"vera_projection_prng_key": 0,
|
| 322 |
+
"vera_dropout": 0.0,
|
| 323 |
+
"vera_d_initial": 0.1,
|
| 324 |
+
"adapter_act": "gelu",
|
| 325 |
+
"adapter_length": 128,
|
| 326 |
+
"use_galore": false,
|
| 327 |
+
"galore_target_modules": null,
|
| 328 |
+
"galore_rank": 128,
|
| 329 |
+
"galore_update_proj_gap": 50,
|
| 330 |
+
"galore_scale": 1.0,
|
| 331 |
+
"galore_proj_type": "std",
|
| 332 |
+
"galore_optim_per_parameter": false,
|
| 333 |
+
"galore_with_embedding": false,
|
| 334 |
+
"galore_quantization": false,
|
| 335 |
+
"galore_proj_quant": false,
|
| 336 |
+
"galore_proj_bits": 4,
|
| 337 |
+
"galore_proj_group_size": 256,
|
| 338 |
+
"galore_cos_threshold": 0.4,
|
| 339 |
+
"galore_gamma_proj": 2,
|
| 340 |
+
"galore_queue_size": 5,
|
| 341 |
+
"adalora_target_r": 8,
|
| 342 |
+
"adalora_init_r": 12,
|
| 343 |
+
"adalora_tinit": 0,
|
| 344 |
+
"adalora_tfinal": 0,
|
| 345 |
+
"adalora_deltaT": 1,
|
| 346 |
+
"adalora_beta1": 0.85,
|
| 347 |
+
"adalora_beta2": 0.85,
|
| 348 |
+
"adalora_orth_reg_weight": 0.5,
|
| 349 |
+
"llamapro_num_new_blocks": 4,
|
| 350 |
+
"llamapro_num_groups": null,
|
| 351 |
+
"lisa_activated_layers": 0,
|
| 352 |
+
"lisa_step_interval": 20,
|
| 353 |
+
"reft_layer_key": null,
|
| 354 |
+
"reft_layers": null,
|
| 355 |
+
"reft_rank": 4,
|
| 356 |
+
"reft_intervention_type": "LoreftIntervention",
|
| 357 |
+
"reft_args": null,
|
| 358 |
+
"swanlab_token": null,
|
| 359 |
+
"swanlab_project": null,
|
| 360 |
+
"swanlab_workspace": null,
|
| 361 |
+
"swanlab_exp_name": null,
|
| 362 |
+
"swanlab_lark_webhook_url": null,
|
| 363 |
+
"swanlab_lark_secret": null,
|
| 364 |
+
"swanlab_mode": "cloud",
|
| 365 |
+
"add_version": true,
|
| 366 |
+
"create_checkpoint_symlink": false,
|
| 367 |
+
"zero_hpz_partition_size": null,
|
| 368 |
+
"deepspeed_autotp_size": null,
|
| 369 |
+
"early_stop_interval": null,
|
| 370 |
+
"rank": 0,
|
| 371 |
+
"global_world_size": 4,
|
| 372 |
+
"local_world_size": 4,
|
| 373 |
+
"model_suffix": "checkpoint-84",
|
| 374 |
+
"model_info": "ModelInfo(model_type='ovis2', model_dir='/kaggle/working/outputs/ovis_2/v0-20250825-145449/checkpoint-84', torch_dtype=torch.bfloat16, max_model_len=32768, quant_method=None, quant_bits=None, rope_scaling=None, is_moe_model=False, config=None, task_type='causal_lm', num_labels=None)",
|
| 375 |
+
"model_meta": "ModelMeta(model_type='ovis2', model_groups=[ModelGroup(models=[Model(ms_model_id='AIDC-AI/Ovis2-1B', hf_model_id='AIDC-AI/Ovis2-1B', model_path=None, ms_revision=None, hf_revision=None), Model(ms_model_id='AIDC-AI/Ovis2-2B', hf_model_id='AIDC-AI/Ovis2-2B', model_path=None, ms_revision=None, hf_revision=None), Model(ms_model_id='AIDC-AI/Ovis2-4B', hf_model_id='AIDC-AI/Ovis2-4B', model_path=None, ms_revision=None, hf_revision=None), Model(ms_model_id='AIDC-AI/Ovis2-8B', hf_model_id='AIDC-AI/Ovis2-8B', model_path=None, ms_revision=None, hf_revision=None), Model(ms_model_id='AIDC-AI/Ovis2-16B', hf_model_id='AIDC-AI/Ovis2-16B', model_path=None, ms_revision=None, hf_revision=None), Model(ms_model_id='AIDC-AI/Ovis2-34B', hf_model_id='AIDC-AI/Ovis2-34B', model_path=None, ms_revision=None, hf_revision=None)], ignore_patterns=None, requires=None, tags=[])], template='ovis2', get_function=<function get_model_tokenizer_ovis at 0x7ccb45a4efc0>, model_arch=MultiModelKeys(arch_name='ovis', embedding=None, module_list=None, lm_head=None, q_proj=None, k_proj=None, v_proj=None, o_proj=None, attention=None, mlp=None, down_proj=None, qkv_proj=None, qk_proj=None, qa_proj=None, qb_proj=None, kv_proj=None, kva_proj=None, kvb_proj=None, language_model=['llm'], aligner=[], vision_tower=['visual_tokenizer', 'vte'], generator=[]), architectures=['Ovis'], additional_saved_files=[], torch_dtype=None, is_multimodal=True, is_reward=False, task_type=None, ignore_patterns=None, requires=['transformers>=4.46.2', 'moviepy<2'], tags=['vision'])",
|
| 376 |
+
"model_dir": "/kaggle/working/outputs/ovis_2/v0-20250825-145449/checkpoint-84",
|
| 377 |
+
"hub": "<class 'swift.hub.hub.HFHub'>",
|
| 378 |
+
"evaluation_strategy": "steps",
|
| 379 |
+
"training_args": "Seq2SeqTrainingArguments(output_dir='/kaggle/working/outputs/ovis_2/v1-20250825-163329', overwrite_output_dir=False, do_train=False, do_eval=True, do_predict=False, eval_strategy=<IntervalStrategy.STEPS: 'steps'>, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=1, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=16, eval_accumulation_steps=None, eval_delay=0, torch_empty_cache_steps=None, learning_rate=1e-05, weight_decay=0.1, adam_beta1=0.9, adam_beta2=0.95, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=5.0, max_steps=-1, lr_scheduler_type=<SchedulerType.COSINE: 'cosine'>, lr_scheduler_kwargs=None, warmup_ratio=0.01, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='/kaggle/working/outputs/ovis_2/v1-20250825-163329/runs', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=True, logging_steps=20, logging_nan_inf_filter=True, save_strategy=<SaveStrategy.STEPS: 'steps'>, save_steps=20, save_total_limit=None, save_safetensors=True, save_on_each_node=False, save_only_model=True, restore_callback_states_from_checkpoint=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=42, data_seed=42, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=20, dataloader_num_workers=8, dataloader_prefetch_factor=10, past_index=-1, run_name='/kaggle/working/outputs/ovis_2/v1-20250825-163329', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model='loss', greater_is_better=False, ignore_data_skip=False, fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}, tp_size=0, fsdp_transformer_layer_cls_to_wrap=None, accelerator_config=AcceleratorConfig(split_batches=False, dispatch_batches=False, even_batches=True, use_seedable_sampler=True, non_blocking=False, gradient_accumulation_kwargs=None, use_configured_state=False), deepspeed={'fp16': {'enabled': 'auto', 'loss_scale': 0, 'loss_scale_window': 1000, 'initial_scale_power': 16, 'hysteresis': 2, 'min_loss_scale': 1}, 'bf16': {'enabled': 'auto'}, 'zero_optimization': {'stage': 3, 'offload_optimizer': {'device': 'none', 'pin_memory': True}, 'offload_param': {'device': 'none', 'pin_memory': True}, 'overlap_comm': False, 'contiguous_gradients': True, 'sub_group_size': 1000000000.0, 'reduce_bucket_size': 'auto', 'zero_quantized_weights': False, 'zero_quantized_gradients': False, 'stage3_prefetch_bucket_size': 'auto', 'stage3_param_persistence_threshold': 'auto', 'stage3_max_live_parameters': 1000000000.0, 'stage3_max_reuse_distance': 1000000000.0, 'stage3_gather_16bit_weights_on_model_save': True}, 'gradient_accumulation_steps': 'auto', 'gradient_clipping': 'auto', 'steps_per_print': 2000, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'wall_clock_breakdown': False}, label_smoothing_factor=0.0, optim=<OptimizerNames.ADAMW_TORCH: 'adamw_torch'>, optim_args=None, adafactor=False, group_by_length=False, length_column_name='length', report_to=['tensorboard'], ddp_find_unused_parameters=None, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, dataloader_persistent_workers=False, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=None, hub_always_push=False, gradient_checkpointing=True, gradient_checkpointing_kwargs=None, include_inputs_for_metrics=False, include_for_metrics=[], eval_do_concat_batches=True, fp16_backend='auto', push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=18000000, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, include_tokens_per_second=None, include_num_input_tokens_seen=None, neftune_noise_alpha=None, optim_target_modules=None, batch_eval_metrics=False, eval_on_start=False, use_liger_kernel=False, eval_use_gather_object=False, average_tokens_across_devices=None, sortish_sampler=False, predict_with_generate=False, generation_max_length=None, generation_num_beams=None, generation_config=None, tuner_backend='peft', vit_gradient_checkpointing=True, router_aux_loss_coef=0.0, enable_dft_loss=False, check_model=True, acc_strategy='token', train_dataloader_shuffle=True, max_epochs=None, aligner_lr=None, vit_lr=None, use_logits_to_keep=None, channels=None, ds3_gather_for_generation=True, resume_only_model=False, optimizer=None, loss_type=None, metric=None, eval_use_evalscope=False, eval_dataset=[], eval_dataset_args=None, eval_limit=None, eval_generation_config=None, extra_eval_args=None, use_flash_ckpt=False, sft_alpha=0, train_type='full', local_repo_path=None, galore_config=None)"
|
| 380 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,260 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Ovis"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_ovis.OvisConfig",
|
| 7 |
+
"AutoModelForCausalLM": "modeling_ovis.Ovis"
|
| 8 |
+
},
|
| 9 |
+
"conversation_formatter_class": "QwenConversationFormatter",
|
| 10 |
+
"disable_tie_weight": false,
|
| 11 |
+
"hidden_size": 1536,
|
| 12 |
+
"keys_to_ignore_at_inference": [
|
| 13 |
+
"past_key_values"
|
| 14 |
+
],
|
| 15 |
+
"llm_attn_implementation": "flash_attention_2",
|
| 16 |
+
"llm_config": {
|
| 17 |
+
"_attn_implementation_autoset": true,
|
| 18 |
+
"_name_or_path": "Qwen/Qwen2.5-1.5B-Instruct",
|
| 19 |
+
"add_cross_attention": false,
|
| 20 |
+
"architectures": [
|
| 21 |
+
"Qwen2ForCausalLM"
|
| 22 |
+
],
|
| 23 |
+
"attention_dropout": 0.0,
|
| 24 |
+
"bad_words_ids": null,
|
| 25 |
+
"begin_suppress_tokens": null,
|
| 26 |
+
"bos_token_id": 151643,
|
| 27 |
+
"chunk_size_feed_forward": 0,
|
| 28 |
+
"cross_attention_hidden_size": null,
|
| 29 |
+
"decoder_start_token_id": null,
|
| 30 |
+
"diversity_penalty": 0.0,
|
| 31 |
+
"do_sample": false,
|
| 32 |
+
"early_stopping": false,
|
| 33 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 34 |
+
"eos_token_id": 151645,
|
| 35 |
+
"exponential_decay_length_penalty": null,
|
| 36 |
+
"finetuning_task": null,
|
| 37 |
+
"forced_bos_token_id": null,
|
| 38 |
+
"forced_eos_token_id": null,
|
| 39 |
+
"hidden_act": "silu",
|
| 40 |
+
"hidden_size": 1536,
|
| 41 |
+
"id2label": {
|
| 42 |
+
"0": "LABEL_0",
|
| 43 |
+
"1": "LABEL_1"
|
| 44 |
+
},
|
| 45 |
+
"initializer_range": 0.02,
|
| 46 |
+
"intermediate_size": 8960,
|
| 47 |
+
"is_decoder": false,
|
| 48 |
+
"is_encoder_decoder": false,
|
| 49 |
+
"label2id": {
|
| 50 |
+
"LABEL_0": 0,
|
| 51 |
+
"LABEL_1": 1
|
| 52 |
+
},
|
| 53 |
+
"length_penalty": 1.0,
|
| 54 |
+
"max_length": 20,
|
| 55 |
+
"max_position_embeddings": 32768,
|
| 56 |
+
"max_window_layers": 21,
|
| 57 |
+
"min_length": 0,
|
| 58 |
+
"model_type": "qwen2",
|
| 59 |
+
"no_repeat_ngram_size": 0,
|
| 60 |
+
"num_attention_heads": 12,
|
| 61 |
+
"num_beam_groups": 1,
|
| 62 |
+
"num_beams": 1,
|
| 63 |
+
"num_hidden_layers": 28,
|
| 64 |
+
"num_key_value_heads": 2,
|
| 65 |
+
"num_return_sequences": 1,
|
| 66 |
+
"output_attentions": false,
|
| 67 |
+
"output_hidden_states": false,
|
| 68 |
+
"output_scores": false,
|
| 69 |
+
"pad_token_id": null,
|
| 70 |
+
"prefix": null,
|
| 71 |
+
"problem_type": null,
|
| 72 |
+
"pruned_heads": {},
|
| 73 |
+
"remove_invalid_values": false,
|
| 74 |
+
"repetition_penalty": 1.0,
|
| 75 |
+
"return_dict": true,
|
| 76 |
+
"return_dict_in_generate": false,
|
| 77 |
+
"rms_norm_eps": 1e-06,
|
| 78 |
+
"rope_scaling": null,
|
| 79 |
+
"rope_theta": 1000000.0,
|
| 80 |
+
"sep_token_id": null,
|
| 81 |
+
"sliding_window": null,
|
| 82 |
+
"suppress_tokens": null,
|
| 83 |
+
"task_specific_params": null,
|
| 84 |
+
"temperature": 1.0,
|
| 85 |
+
"tf_legacy_loss": false,
|
| 86 |
+
"tie_encoder_decoder": false,
|
| 87 |
+
"tie_word_embeddings": true,
|
| 88 |
+
"tokenizer_class": null,
|
| 89 |
+
"top_k": 50,
|
| 90 |
+
"top_p": 1.0,
|
| 91 |
+
"torch_dtype": "bfloat16",
|
| 92 |
+
"torchscript": false,
|
| 93 |
+
"typical_p": 1.0,
|
| 94 |
+
"use_bfloat16": false,
|
| 95 |
+
"use_cache": true,
|
| 96 |
+
"use_sliding_window": false,
|
| 97 |
+
"vocab_size": 151936
|
| 98 |
+
},
|
| 99 |
+
"model_type": "ovis",
|
| 100 |
+
"multimodal_max_length": 5001,
|
| 101 |
+
"pad_token_id": 151643,
|
| 102 |
+
"torch_dtype": "bfloat16",
|
| 103 |
+
"transformers_version": "4.51.3",
|
| 104 |
+
"use_cache": false,
|
| 105 |
+
"visual_tokenizer_config": {
|
| 106 |
+
"_attn_implementation_autoset": true,
|
| 107 |
+
"_name_or_path": "",
|
| 108 |
+
"add_cross_attention": false,
|
| 109 |
+
"architectures": null,
|
| 110 |
+
"backbone_config": {
|
| 111 |
+
"_attn_implementation_autoset": true,
|
| 112 |
+
"_name_or_path": "apple/aimv2-large-patch14-448",
|
| 113 |
+
"add_cross_attention": false,
|
| 114 |
+
"architectures": [
|
| 115 |
+
"AIMv2Model"
|
| 116 |
+
],
|
| 117 |
+
"attention_dropout": 0.0,
|
| 118 |
+
"auto_map": {
|
| 119 |
+
"AutoConfig": "configuration_aimv2.AIMv2Config",
|
| 120 |
+
"AutoModel": "modeling_aimv2.AIMv2Model",
|
| 121 |
+
"FlaxAutoModel": "modeling_flax_aimv2.FlaxAIMv2Model"
|
| 122 |
+
},
|
| 123 |
+
"bad_words_ids": null,
|
| 124 |
+
"begin_suppress_tokens": null,
|
| 125 |
+
"bos_token_id": null,
|
| 126 |
+
"chunk_size_feed_forward": 0,
|
| 127 |
+
"cross_attention_hidden_size": null,
|
| 128 |
+
"decoder_start_token_id": null,
|
| 129 |
+
"diversity_penalty": 0.0,
|
| 130 |
+
"do_sample": false,
|
| 131 |
+
"early_stopping": false,
|
| 132 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 133 |
+
"eos_token_id": null,
|
| 134 |
+
"exponential_decay_length_penalty": null,
|
| 135 |
+
"finetuning_task": null,
|
| 136 |
+
"forced_bos_token_id": null,
|
| 137 |
+
"forced_eos_token_id": null,
|
| 138 |
+
"hidden_size": 1024,
|
| 139 |
+
"id2label": {
|
| 140 |
+
"0": "LABEL_0",
|
| 141 |
+
"1": "LABEL_1"
|
| 142 |
+
},
|
| 143 |
+
"image_size": 448,
|
| 144 |
+
"intermediate_size": 2816,
|
| 145 |
+
"is_decoder": false,
|
| 146 |
+
"is_encoder_decoder": false,
|
| 147 |
+
"label2id": {
|
| 148 |
+
"LABEL_0": 0,
|
| 149 |
+
"LABEL_1": 1
|
| 150 |
+
},
|
| 151 |
+
"length_penalty": 1.0,
|
| 152 |
+
"max_length": 20,
|
| 153 |
+
"min_length": 0,
|
| 154 |
+
"model_type": "aimv2",
|
| 155 |
+
"no_repeat_ngram_size": 0,
|
| 156 |
+
"num_attention_heads": 8,
|
| 157 |
+
"num_beam_groups": 1,
|
| 158 |
+
"num_beams": 1,
|
| 159 |
+
"num_channels": 3,
|
| 160 |
+
"num_hidden_layers": 24,
|
| 161 |
+
"num_return_sequences": 1,
|
| 162 |
+
"output_attentions": false,
|
| 163 |
+
"output_hidden_states": false,
|
| 164 |
+
"output_scores": false,
|
| 165 |
+
"pad_token_id": null,
|
| 166 |
+
"patch_size": 14,
|
| 167 |
+
"prefix": null,
|
| 168 |
+
"problem_type": null,
|
| 169 |
+
"projection_dropout": 0.0,
|
| 170 |
+
"pruned_heads": {},
|
| 171 |
+
"qkv_bias": false,
|
| 172 |
+
"remove_invalid_values": false,
|
| 173 |
+
"repetition_penalty": 1.0,
|
| 174 |
+
"return_dict": true,
|
| 175 |
+
"return_dict_in_generate": false,
|
| 176 |
+
"rms_norm_eps": 1e-05,
|
| 177 |
+
"sep_token_id": null,
|
| 178 |
+
"suppress_tokens": null,
|
| 179 |
+
"task_specific_params": null,
|
| 180 |
+
"temperature": 1.0,
|
| 181 |
+
"tf_legacy_loss": false,
|
| 182 |
+
"tie_encoder_decoder": false,
|
| 183 |
+
"tie_word_embeddings": true,
|
| 184 |
+
"tokenizer_class": null,
|
| 185 |
+
"top_k": 50,
|
| 186 |
+
"top_p": 1.0,
|
| 187 |
+
"torch_dtype": "bfloat16",
|
| 188 |
+
"torchscript": false,
|
| 189 |
+
"typical_p": 1.0,
|
| 190 |
+
"use_bfloat16": false,
|
| 191 |
+
"use_bias": false
|
| 192 |
+
},
|
| 193 |
+
"backbone_kwargs": {},
|
| 194 |
+
"bad_words_ids": null,
|
| 195 |
+
"begin_suppress_tokens": null,
|
| 196 |
+
"bos_token_id": null,
|
| 197 |
+
"chunk_size_feed_forward": 0,
|
| 198 |
+
"cross_attention_hidden_size": null,
|
| 199 |
+
"decoder_start_token_id": null,
|
| 200 |
+
"depths": null,
|
| 201 |
+
"diversity_penalty": 0.0,
|
| 202 |
+
"do_sample": false,
|
| 203 |
+
"drop_cls_token": false,
|
| 204 |
+
"early_stopping": false,
|
| 205 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 206 |
+
"eos_token_id": null,
|
| 207 |
+
"exponential_decay_length_penalty": null,
|
| 208 |
+
"finetuning_task": null,
|
| 209 |
+
"forced_bos_token_id": null,
|
| 210 |
+
"forced_eos_token_id": null,
|
| 211 |
+
"hidden_stride": 2,
|
| 212 |
+
"id2label": {
|
| 213 |
+
"0": "LABEL_0",
|
| 214 |
+
"1": "LABEL_1"
|
| 215 |
+
},
|
| 216 |
+
"is_decoder": false,
|
| 217 |
+
"is_encoder_decoder": false,
|
| 218 |
+
"label2id": {
|
| 219 |
+
"LABEL_0": 0,
|
| 220 |
+
"LABEL_1": 1
|
| 221 |
+
},
|
| 222 |
+
"length_penalty": 1.0,
|
| 223 |
+
"max_length": 20,
|
| 224 |
+
"min_length": 0,
|
| 225 |
+
"model_type": "aimv2_visual_tokenizer",
|
| 226 |
+
"no_repeat_ngram_size": 0,
|
| 227 |
+
"num_beam_groups": 1,
|
| 228 |
+
"num_beams": 1,
|
| 229 |
+
"num_return_sequences": 1,
|
| 230 |
+
"output_attentions": false,
|
| 231 |
+
"output_hidden_states": false,
|
| 232 |
+
"output_scores": false,
|
| 233 |
+
"pad_token_id": null,
|
| 234 |
+
"prefix": null,
|
| 235 |
+
"problem_type": null,
|
| 236 |
+
"pruned_heads": {},
|
| 237 |
+
"remove_invalid_values": false,
|
| 238 |
+
"repetition_penalty": 1.0,
|
| 239 |
+
"return_dict": true,
|
| 240 |
+
"return_dict_in_generate": false,
|
| 241 |
+
"sep_token_id": null,
|
| 242 |
+
"suppress_tokens": null,
|
| 243 |
+
"task_specific_params": null,
|
| 244 |
+
"tau": 1.0,
|
| 245 |
+
"temperature": 1.0,
|
| 246 |
+
"tf_legacy_loss": false,
|
| 247 |
+
"tie_encoder_decoder": false,
|
| 248 |
+
"tie_word_embeddings": true,
|
| 249 |
+
"tokenize_function": "softmax",
|
| 250 |
+
"tokenizer_class": null,
|
| 251 |
+
"top_k": 50,
|
| 252 |
+
"top_p": 1.0,
|
| 253 |
+
"torch_dtype": null,
|
| 254 |
+
"torchscript": false,
|
| 255 |
+
"typical_p": 1.0,
|
| 256 |
+
"use_bfloat16": false,
|
| 257 |
+
"use_indicators": false,
|
| 258 |
+
"vocab_size": 65536
|
| 259 |
+
}
|
| 260 |
+
}
|
configuration_aimv2.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# copied from https://huggingface.co/apple/aimv2-huge-patch14-448
|
| 2 |
+
from typing import Any
|
| 3 |
+
|
| 4 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 5 |
+
|
| 6 |
+
__all__ = ["AIMv2Config"]
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class AIMv2Config(PretrainedConfig):
|
| 10 |
+
"""This is the configuration class to store the configuration of an [`AIMv2Model`].
|
| 11 |
+
|
| 12 |
+
Instantiating a configuration with the defaults will yield a similar configuration
|
| 13 |
+
to that of the [apple/aimv2-large-patch14-224](https://huggingface.co/apple/aimv2-large-patch14-224).
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
hidden_size: Dimension of the hidden representations.
|
| 17 |
+
intermediate_size: Dimension of the SwiGLU representations.
|
| 18 |
+
num_hidden_layers: Number of hidden layers in the Transformer.
|
| 19 |
+
num_attention_heads: Number of attention heads for each attention layer
|
| 20 |
+
in the Transformer.
|
| 21 |
+
num_channels: Number of input channels.
|
| 22 |
+
image_size: Image size.
|
| 23 |
+
patch_size: Patch size.
|
| 24 |
+
rms_norm_eps: Epsilon value used for the RMS normalization layer.
|
| 25 |
+
attention_dropout: Dropout ratio for attention probabilities.
|
| 26 |
+
projection_dropout: Dropout ratio for the projection layer after the attention.
|
| 27 |
+
qkv_bias: Whether to add a bias to the queries, keys and values.
|
| 28 |
+
use_bias: Whether to add a bias in the feed-forward and projection layers.
|
| 29 |
+
kwargs: Keyword arguments for the [`PretrainedConfig`].
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
model_type: str = "aimv2"
|
| 33 |
+
|
| 34 |
+
def __init__(
|
| 35 |
+
self,
|
| 36 |
+
hidden_size: int = 1024,
|
| 37 |
+
intermediate_size: int = 2816,
|
| 38 |
+
num_hidden_layers: int = 24,
|
| 39 |
+
num_attention_heads: int = 8,
|
| 40 |
+
num_channels: int = 3,
|
| 41 |
+
image_size: int = 224,
|
| 42 |
+
patch_size: int = 14,
|
| 43 |
+
rms_norm_eps: float = 1e-5,
|
| 44 |
+
attention_dropout: float = 0.0,
|
| 45 |
+
projection_dropout: float = 0.0,
|
| 46 |
+
qkv_bias: bool = False,
|
| 47 |
+
use_bias: bool = False,
|
| 48 |
+
**kwargs: Any,
|
| 49 |
+
):
|
| 50 |
+
super().__init__(**kwargs)
|
| 51 |
+
self.hidden_size = hidden_size
|
| 52 |
+
self.intermediate_size = intermediate_size
|
| 53 |
+
self.num_hidden_layers = num_hidden_layers
|
| 54 |
+
self.num_attention_heads = num_attention_heads
|
| 55 |
+
self.num_channels = num_channels
|
| 56 |
+
self.patch_size = patch_size
|
| 57 |
+
self.image_size = image_size
|
| 58 |
+
self.attention_dropout = attention_dropout
|
| 59 |
+
self.rms_norm_eps = rms_norm_eps
|
| 60 |
+
|
| 61 |
+
self.projection_dropout = projection_dropout
|
| 62 |
+
self.qkv_bias = qkv_bias
|
| 63 |
+
self.use_bias = use_bias
|
configuration_ovis.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import List, Dict, Union, Optional
|
| 3 |
+
|
| 4 |
+
from transformers import PretrainedConfig, AutoConfig, AutoModel
|
| 5 |
+
from .configuration_aimv2 import AIMv2Config
|
| 6 |
+
from .modeling_aimv2 import AIMv2Model
|
| 7 |
+
|
| 8 |
+
IGNORE_ID = -100
|
| 9 |
+
IMAGE_TOKEN_ID = -200
|
| 10 |
+
IMAGE_TOKEN = "<image>"
|
| 11 |
+
IMAGE_ATOM_ID = -300
|
| 12 |
+
IMAGE_INDICATOR_IDS = [-301, -302, -303, -304, -305]
|
| 13 |
+
|
| 14 |
+
AutoConfig.register("aimv2", AIMv2Config)
|
| 15 |
+
AutoModel.register(AIMv2Config, AIMv2Model)
|
| 16 |
+
|
| 17 |
+
# ----------------------------------------------------------------------
|
| 18 |
+
# Visual Tokenizer Configuration
|
| 19 |
+
# ----------------------------------------------------------------------
|
| 20 |
+
class BaseVisualTokenizerConfig(PretrainedConfig):
|
| 21 |
+
def __init__(
|
| 22 |
+
self,
|
| 23 |
+
vocab_size=16384,
|
| 24 |
+
tokenize_function="softmax",
|
| 25 |
+
tau=1.0,
|
| 26 |
+
depths=None,
|
| 27 |
+
drop_cls_token=False,
|
| 28 |
+
backbone_config: Optional[Union[PretrainedConfig, dict]] = None,
|
| 29 |
+
hidden_stride: int = 1,
|
| 30 |
+
**kwargs
|
| 31 |
+
):
|
| 32 |
+
super().__init__(**kwargs)
|
| 33 |
+
self.vocab_size = vocab_size
|
| 34 |
+
self.tokenize_function = tokenize_function
|
| 35 |
+
self.tau = tau
|
| 36 |
+
if isinstance(depths, str):
|
| 37 |
+
depths = [int(x) for x in depths.split('|')]
|
| 38 |
+
self.depths = depths
|
| 39 |
+
self.backbone_kwargs = {}
|
| 40 |
+
self.drop_cls_token = drop_cls_token
|
| 41 |
+
if backbone_config is not None:
|
| 42 |
+
assert isinstance(backbone_config, (PretrainedConfig, dict)), \
|
| 43 |
+
f"expect `backbone_config` to be instance of PretrainedConfig or dict, but got {type(backbone_config)} type"
|
| 44 |
+
if not isinstance(backbone_config, PretrainedConfig):
|
| 45 |
+
model_type = backbone_config['model_type']
|
| 46 |
+
backbone_config.pop('model_type')
|
| 47 |
+
backbone_config = AutoConfig.for_model(model_type, **backbone_config)
|
| 48 |
+
self.backbone_config = backbone_config
|
| 49 |
+
self.hidden_stride = hidden_stride
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class Aimv2VisualTokenizerConfig(BaseVisualTokenizerConfig):
|
| 53 |
+
model_type = "aimv2_visual_tokenizer"
|
| 54 |
+
|
| 55 |
+
def __init__(self, **kwargs):
|
| 56 |
+
super().__init__(**kwargs)
|
| 57 |
+
if self.drop_cls_token:
|
| 58 |
+
self.drop_cls_token = False
|
| 59 |
+
if self.depths:
|
| 60 |
+
assert len(self.depths) == 1
|
| 61 |
+
self.backbone_kwargs['num_hidden_layers'] = self.depths[0]
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
AutoConfig.register("aimv2_visual_tokenizer", Aimv2VisualTokenizerConfig)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
# ----------------------------------------------------------------------
|
| 68 |
+
# Ovis Configuration
|
| 69 |
+
# ----------------------------------------------------------------------
|
| 70 |
+
class OvisConfig(PretrainedConfig):
|
| 71 |
+
model_type = "ovis"
|
| 72 |
+
|
| 73 |
+
def __init__(
|
| 74 |
+
self,
|
| 75 |
+
llm_config: Optional[Union[PretrainedConfig, dict]] = None,
|
| 76 |
+
visual_tokenizer_config: Optional[Union[PretrainedConfig, dict]] = None,
|
| 77 |
+
multimodal_max_length=8192,
|
| 78 |
+
hidden_size=None,
|
| 79 |
+
conversation_formatter_class=None,
|
| 80 |
+
llm_attn_implementation=None,
|
| 81 |
+
disable_tie_weight=False,
|
| 82 |
+
**kwargs
|
| 83 |
+
):
|
| 84 |
+
super().__init__(**kwargs)
|
| 85 |
+
if llm_config is not None:
|
| 86 |
+
assert isinstance(llm_config, (PretrainedConfig, dict)), \
|
| 87 |
+
f"expect `llm_config` to be instance of PretrainedConfig or dict, but got {type(llm_config)} type"
|
| 88 |
+
if not isinstance(llm_config, PretrainedConfig):
|
| 89 |
+
model_type = llm_config['model_type']
|
| 90 |
+
llm_config.pop('model_type')
|
| 91 |
+
llm_config = AutoConfig.for_model(model_type, **llm_config)
|
| 92 |
+
self.llm_config = llm_config
|
| 93 |
+
if visual_tokenizer_config is not None:
|
| 94 |
+
assert isinstance(visual_tokenizer_config, (PretrainedConfig, dict)), \
|
| 95 |
+
f"expect `visual_tokenizer_config` to be instance of PretrainedConfig or dict, but got {type(visual_tokenizer_config)} type"
|
| 96 |
+
if not isinstance(visual_tokenizer_config, PretrainedConfig):
|
| 97 |
+
model_type = visual_tokenizer_config['model_type']
|
| 98 |
+
visual_tokenizer_config.pop('model_type')
|
| 99 |
+
visual_tokenizer_config = AutoConfig.for_model(model_type, **visual_tokenizer_config)
|
| 100 |
+
self.visual_tokenizer_config = visual_tokenizer_config
|
| 101 |
+
self.multimodal_max_length = multimodal_max_length
|
| 102 |
+
self.hidden_size = hidden_size
|
| 103 |
+
self.conversation_formatter_class = conversation_formatter_class
|
| 104 |
+
self.llm_attn_implementation = llm_attn_implementation
|
| 105 |
+
self.disable_tie_weight = disable_tie_weight
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
# ----------------------------------------------------------------------
|
| 109 |
+
# Conversation Formatter
|
| 110 |
+
# ----------------------------------------------------------------------
|
| 111 |
+
class ConversationFormatter(ABC):
|
| 112 |
+
support_tokenizer_types = None
|
| 113 |
+
|
| 114 |
+
def __init__(self, tokenizer):
|
| 115 |
+
tokenizer_type = type(tokenizer).__name__
|
| 116 |
+
assert tokenizer_type in self.support_tokenizer_types, \
|
| 117 |
+
f'Invalid tokenizer type, expected one from `{self.support_tokenizer_types}`, but got `{tokenizer_type}`'
|
| 118 |
+
self.tokenizer = tokenizer
|
| 119 |
+
self.image_token = IMAGE_TOKEN
|
| 120 |
+
self.image_token_id = IMAGE_TOKEN_ID
|
| 121 |
+
self.ignore_id = IGNORE_ID
|
| 122 |
+
|
| 123 |
+
def _tokenize_with_image_symbol(self, text):
|
| 124 |
+
text_chunks = [self.tokenizer(chunk, add_special_tokens=False).input_ids for chunk in
|
| 125 |
+
text.split(self.image_token)]
|
| 126 |
+
token_ids = []
|
| 127 |
+
num_chuck = len(text_chunks)
|
| 128 |
+
for i, chunk in enumerate(text_chunks):
|
| 129 |
+
token_ids.extend(chunk)
|
| 130 |
+
if i < num_chuck - 1:
|
| 131 |
+
token_ids.append(self.image_token_id)
|
| 132 |
+
return token_ids
|
| 133 |
+
|
| 134 |
+
@abstractmethod
|
| 135 |
+
def format(self, conversations: List[Dict], generation_preface=None):
|
| 136 |
+
pass
|
| 137 |
+
|
| 138 |
+
@abstractmethod
|
| 139 |
+
def format_query(self, query, generation_preface=""):
|
| 140 |
+
pass
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class QwenConversationFormatter(ConversationFormatter):
|
| 144 |
+
support_tokenizer_types = ['QWenTokenizer', 'Qwen2TokenizerFast']
|
| 145 |
+
|
| 146 |
+
def __init__(self, tokenizer):
|
| 147 |
+
super().__init__(tokenizer)
|
| 148 |
+
self.from2role = {
|
| 149 |
+
"system": "<|im_start|>system\n",
|
| 150 |
+
"human": "<|im_start|>user\n",
|
| 151 |
+
"gpt": "<|im_start|>assistant\n",
|
| 152 |
+
}
|
| 153 |
+
self.gpt_token_num = None
|
| 154 |
+
self.im_end = "<|im_end|>\n"
|
| 155 |
+
self.default_system_prompt = "You are a helpful assistant."
|
| 156 |
+
|
| 157 |
+
def format(self, conversations: List[Dict], generation_preface=None):
|
| 158 |
+
if self.gpt_token_num is None:
|
| 159 |
+
self.gpt_token_num = len(self.tokenizer(self.from2role["gpt"], add_special_tokens=False).input_ids)
|
| 160 |
+
|
| 161 |
+
if conversations[0]["from"] != "system":
|
| 162 |
+
conversations.insert(0, {
|
| 163 |
+
"from": "system",
|
| 164 |
+
"value": self.default_system_prompt
|
| 165 |
+
})
|
| 166 |
+
|
| 167 |
+
if generation_preface is not None:
|
| 168 |
+
conversations.append({
|
| 169 |
+
"from": "gpt",
|
| 170 |
+
"value": generation_preface
|
| 171 |
+
})
|
| 172 |
+
|
| 173 |
+
prompt = ""
|
| 174 |
+
input_ids = []
|
| 175 |
+
labels = []
|
| 176 |
+
num_conversation = len(conversations)
|
| 177 |
+
for i, conversation in enumerate(conversations):
|
| 178 |
+
frm = conversation["from"]
|
| 179 |
+
role = self.from2role[frm]
|
| 180 |
+
message = conversation["value"]
|
| 181 |
+
text = role + message
|
| 182 |
+
if i < num_conversation - 1 or generation_preface is None:
|
| 183 |
+
text += self.im_end
|
| 184 |
+
prompt += text
|
| 185 |
+
token_ids = self._tokenize_with_image_symbol(text)
|
| 186 |
+
input_ids.extend(token_ids)
|
| 187 |
+
label_ids = [self.ignore_id] * len(token_ids)
|
| 188 |
+
if frm == "gpt" and generation_preface is None:
|
| 189 |
+
# learning `\n` following `im_end` is meaningless, so the last `\n` token is ignored in label
|
| 190 |
+
label_ids[self.gpt_token_num:-1] = token_ids[self.gpt_token_num:-1]
|
| 191 |
+
labels.extend(label_ids)
|
| 192 |
+
|
| 193 |
+
assert self._tokenize_with_image_symbol(prompt) == input_ids
|
| 194 |
+
assert len(input_ids) == len(labels)
|
| 195 |
+
|
| 196 |
+
return prompt, input_ids, labels
|
| 197 |
+
|
| 198 |
+
def format_query(self, query, generation_preface=""):
|
| 199 |
+
prompt, input_ids, _ = self.format([{
|
| 200 |
+
"from": "human",
|
| 201 |
+
"value": query
|
| 202 |
+
}], generation_preface=generation_preface)
|
| 203 |
+
|
| 204 |
+
return prompt, input_ids
|
generation_config.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"multimodal_max_length": 32768,
|
| 9 |
+
"pad_token_id": 151643,
|
| 10 |
+
"repetition_penalty": 1.1,
|
| 11 |
+
"temperature": 0.7,
|
| 12 |
+
"top_k": 20,
|
| 13 |
+
"top_p": 0.8,
|
| 14 |
+
"transformers_version": "4.51.3"
|
| 15 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a409ba1902192f90ac050391dff76ddf4b086008ba7e4b486d11d79604cb9042
|
| 3 |
+
size 4445879148
|
modeling_aimv2.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# adapted from https://huggingface.co/apple/aimv2-huge-patch14-448 (modification: add gradient checkpoint support)
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from .configuration_aimv2 import AIMv2Config
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
from transformers.modeling_outputs import BaseModelOutputWithNoAttention
|
| 9 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 10 |
+
|
| 11 |
+
__all__ = ["AIMv2Model"]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class RMSNorm(nn.Module):
|
| 15 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 18 |
+
self.eps = eps
|
| 19 |
+
|
| 20 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 21 |
+
output = self._norm(x.float()).type_as(x)
|
| 22 |
+
return output * self.weight
|
| 23 |
+
|
| 24 |
+
def extra_repr(self) -> str:
|
| 25 |
+
return f"{tuple(self.weight.shape)}, eps={self.eps}"
|
| 26 |
+
|
| 27 |
+
def _norm(self, x: torch.Tensor) -> torch.Tensor:
|
| 28 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class AIMv2SwiGLUFFN(nn.Module):
|
| 32 |
+
def __init__(self, config: AIMv2Config):
|
| 33 |
+
super().__init__()
|
| 34 |
+
hidden_features = config.intermediate_size
|
| 35 |
+
in_features = config.hidden_size
|
| 36 |
+
bias = config.use_bias
|
| 37 |
+
|
| 38 |
+
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
|
| 39 |
+
self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
|
| 40 |
+
self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
|
| 41 |
+
|
| 42 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 43 |
+
x = F.silu(self.fc1(x)) * self.fc3(x)
|
| 44 |
+
x = self.fc2(x)
|
| 45 |
+
return x
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class AIMv2PatchEmbed(nn.Module):
|
| 49 |
+
def __init__(self, config: AIMv2Config):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.proj = nn.Conv2d(
|
| 52 |
+
config.num_channels,
|
| 53 |
+
config.hidden_size,
|
| 54 |
+
kernel_size=(config.patch_size, config.patch_size),
|
| 55 |
+
stride=(config.patch_size, config.patch_size),
|
| 56 |
+
)
|
| 57 |
+
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 58 |
+
|
| 59 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 60 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 61 |
+
x = self.norm(x)
|
| 62 |
+
return x
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class AIMv2ViTPreprocessor(nn.Module):
|
| 66 |
+
def __init__(self, config: AIMv2Config):
|
| 67 |
+
super().__init__()
|
| 68 |
+
num_patches = (config.image_size // config.patch_size) ** 2
|
| 69 |
+
|
| 70 |
+
self.patchifier = AIMv2PatchEmbed(config)
|
| 71 |
+
self.pos_embed = nn.Parameter(torch.zeros((1, num_patches, config.hidden_size)))
|
| 72 |
+
|
| 73 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 74 |
+
tokens = self.patchifier(x)
|
| 75 |
+
_, N, _ = tokens.shape
|
| 76 |
+
pos_embed = self.pos_embed.to(tokens.device)
|
| 77 |
+
tokens = tokens + pos_embed[:, :N]
|
| 78 |
+
return tokens
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class AIMv2Attention(nn.Module):
|
| 82 |
+
def __init__(self, config: AIMv2Config):
|
| 83 |
+
super().__init__()
|
| 84 |
+
dim = config.hidden_size
|
| 85 |
+
|
| 86 |
+
self.num_heads = config.num_attention_heads
|
| 87 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=config.qkv_bias)
|
| 88 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 89 |
+
self.proj = nn.Linear(dim, dim, bias=config.use_bias)
|
| 90 |
+
self.proj_drop = nn.Dropout(config.projection_dropout)
|
| 91 |
+
|
| 92 |
+
def forward(
|
| 93 |
+
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 94 |
+
) -> torch.Tensor:
|
| 95 |
+
B, N, C = x.shape
|
| 96 |
+
qkv = (
|
| 97 |
+
self.qkv(x)
|
| 98 |
+
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
| 99 |
+
.permute(2, 0, 3, 1, 4)
|
| 100 |
+
)
|
| 101 |
+
q, k, v = qkv.unbind(0)
|
| 102 |
+
|
| 103 |
+
x = F.scaled_dot_product_attention(q, k, v, attn_mask=mask)
|
| 104 |
+
x = x.transpose(1, 2).contiguous().reshape(B, N, C)
|
| 105 |
+
x = self.proj(x)
|
| 106 |
+
x = self.proj_drop(x)
|
| 107 |
+
return x
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class AIMv2Block(nn.Module):
|
| 111 |
+
def __init__(self, config: AIMv2Config):
|
| 112 |
+
super().__init__()
|
| 113 |
+
self.attn = AIMv2Attention(config)
|
| 114 |
+
self.norm_1 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 115 |
+
self.mlp = AIMv2SwiGLUFFN(config)
|
| 116 |
+
self.norm_2 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 117 |
+
|
| 118 |
+
def forward(
|
| 119 |
+
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 120 |
+
) -> torch.Tensor:
|
| 121 |
+
x = x + self.attn(self.norm_1(x), mask)
|
| 122 |
+
x = x + self.mlp(self.norm_2(x))
|
| 123 |
+
return x
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
class AIMv2Transformer(nn.Module):
|
| 127 |
+
def __init__(self, config: AIMv2Config):
|
| 128 |
+
super().__init__()
|
| 129 |
+
self.blocks = nn.ModuleList(
|
| 130 |
+
[AIMv2Block(config) for _ in range(config.num_hidden_layers)]
|
| 131 |
+
)
|
| 132 |
+
self.post_trunk_norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 133 |
+
self.gradient_checkpointing = False
|
| 134 |
+
|
| 135 |
+
def forward(
|
| 136 |
+
self,
|
| 137 |
+
tokens: torch.Tensor,
|
| 138 |
+
mask: Optional[torch.Tensor] = None,
|
| 139 |
+
output_hidden_states: bool = False,
|
| 140 |
+
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor, ...]]]:
|
| 141 |
+
hidden_states = () if output_hidden_states else None
|
| 142 |
+
for block in self.blocks:
|
| 143 |
+
if self.gradient_checkpointing and self.training:
|
| 144 |
+
tokens = self._gradient_checkpointing_func(block.__call__, tokens, mask)
|
| 145 |
+
else:
|
| 146 |
+
tokens = block(tokens, mask)
|
| 147 |
+
if output_hidden_states:
|
| 148 |
+
hidden_states += (tokens,)
|
| 149 |
+
tokens = self.post_trunk_norm(tokens)
|
| 150 |
+
return tokens, hidden_states
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class AIMv2PretrainedModel(PreTrainedModel):
|
| 154 |
+
config_class = AIMv2Config
|
| 155 |
+
base_model_prefix = "aimv2"
|
| 156 |
+
supports_gradient_checkpointing = True
|
| 157 |
+
main_input_name = "pixel_values"
|
| 158 |
+
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
| 159 |
+
_supports_sdpa = True
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class AIMv2Model(AIMv2PretrainedModel):
|
| 163 |
+
def __init__(self, config: AIMv2Config):
|
| 164 |
+
super().__init__(config)
|
| 165 |
+
self.preprocessor = AIMv2ViTPreprocessor(config)
|
| 166 |
+
self.trunk = AIMv2Transformer(config)
|
| 167 |
+
|
| 168 |
+
def forward(
|
| 169 |
+
self,
|
| 170 |
+
pixel_values: torch.Tensor,
|
| 171 |
+
mask: Optional[torch.Tensor] = None,
|
| 172 |
+
output_hidden_states: Optional[bool] = None,
|
| 173 |
+
return_dict: Optional[bool] = None,
|
| 174 |
+
) -> Union[
|
| 175 |
+
Tuple[torch.Tensor],
|
| 176 |
+
Tuple[torch.Tensor, Tuple[torch.Tensor, ...]],
|
| 177 |
+
BaseModelOutputWithNoAttention,
|
| 178 |
+
]:
|
| 179 |
+
if output_hidden_states is None:
|
| 180 |
+
output_hidden_states = self.config.output_hidden_states
|
| 181 |
+
if return_dict is None:
|
| 182 |
+
return_dict = self.config.use_return_dict
|
| 183 |
+
|
| 184 |
+
x = self.preprocessor(pixel_values)
|
| 185 |
+
x, hidden_states = self.trunk(
|
| 186 |
+
x, mask, output_hidden_states=output_hidden_states
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
if not return_dict:
|
| 190 |
+
res = (x,)
|
| 191 |
+
res += (hidden_states,) if output_hidden_states else ()
|
| 192 |
+
return res
|
| 193 |
+
|
| 194 |
+
return BaseModelOutputWithNoAttention(
|
| 195 |
+
last_hidden_state=x,
|
| 196 |
+
hidden_states=hidden_states,
|
| 197 |
+
)
|
| 198 |
+
|
modeling_ovis.py
ADDED
|
@@ -0,0 +1,590 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (C) 2025 AIDC-AI
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 7 |
+
#
|
| 8 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 9 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 10 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 11 |
+
#
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import logging
|
| 16 |
+
import os
|
| 17 |
+
import importlib.metadata
|
| 18 |
+
|
| 19 |
+
from packaging import version
|
| 20 |
+
from importlib import import_module
|
| 21 |
+
from typing import List, Callable, Union, Optional, Dict
|
| 22 |
+
|
| 23 |
+
import PIL.Image
|
| 24 |
+
import torch
|
| 25 |
+
from torch import Tensor
|
| 26 |
+
from torch.nn import init
|
| 27 |
+
from torch.nn.functional import softmax, gumbel_softmax, pad
|
| 28 |
+
from transformers.utils import is_flash_attn_2_available
|
| 29 |
+
from transformers import PreTrainedModel, AutoModel, AutoTokenizer, AutoModelForCausalLM, AutoImageProcessor
|
| 30 |
+
from transformers.generation.utils import GenerateOutput
|
| 31 |
+
|
| 32 |
+
from .configuration_ovis import BaseVisualTokenizerConfig, Aimv2VisualTokenizerConfig
|
| 33 |
+
from .configuration_ovis import OvisConfig, ConversationFormatter
|
| 34 |
+
from .configuration_ovis import IGNORE_ID, IMAGE_ATOM_ID, IMAGE_INDICATOR_IDS, IMAGE_TOKEN_ID
|
| 35 |
+
|
| 36 |
+
# ----------------------------------------------------------------------
|
| 37 |
+
# Visual Tokenizer
|
| 38 |
+
# ----------------------------------------------------------------------
|
| 39 |
+
class BaseVisualTokenizer(PreTrainedModel):
|
| 40 |
+
base_model_prefix = "backbone"
|
| 41 |
+
main_input_name = None
|
| 42 |
+
_image_processor_class = None
|
| 43 |
+
_image_processor_kwargs = {}
|
| 44 |
+
_backbone_class = None
|
| 45 |
+
_backbone_name_or_path = None
|
| 46 |
+
|
| 47 |
+
def __init__(self, config: BaseVisualTokenizerConfig, *inputs, **kwargs):
|
| 48 |
+
super().__init__(config, *inputs, **kwargs)
|
| 49 |
+
self.image_processor = AutoImageProcessor.from_pretrained(kwargs['image_processor_name_or_path'])
|
| 50 |
+
self.backbone = AutoModel.from_config(self.config.backbone_config)
|
| 51 |
+
head_dim = self.config.vocab_size - len(IMAGE_INDICATOR_IDS) # reserved tokens for IMAGE_INDICATORS
|
| 52 |
+
self.head = torch.nn.Sequential(
|
| 53 |
+
torch.nn.Linear(
|
| 54 |
+
self.backbone.config.hidden_size * self.config.hidden_stride * self.config.hidden_stride, head_dim,
|
| 55 |
+
bias=False
|
| 56 |
+
),
|
| 57 |
+
torch.nn.LayerNorm(head_dim)
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
assert all((self.image_processor.do_resize,
|
| 61 |
+
not getattr(self.image_processor, 'do_center_crop', False),
|
| 62 |
+
self.image_processor.do_rescale,
|
| 63 |
+
self.image_processor.do_normalize
|
| 64 |
+
)), f"image_processor `{self.image_processor}` is not supported currently"
|
| 65 |
+
|
| 66 |
+
def get_backbone(self):
|
| 67 |
+
return self.backbone
|
| 68 |
+
|
| 69 |
+
def get_image_processor(self):
|
| 70 |
+
return self.image_processor
|
| 71 |
+
|
| 72 |
+
def mock_input(self):
|
| 73 |
+
height, width = self.get_image_size()
|
| 74 |
+
return torch.zeros(1, 3, height, width), self.construct_image_placeholders((1, 1))
|
| 75 |
+
|
| 76 |
+
def get_head(self):
|
| 77 |
+
return self.head
|
| 78 |
+
|
| 79 |
+
def get_image_size(self):
|
| 80 |
+
raise NotImplementedError
|
| 81 |
+
|
| 82 |
+
@staticmethod
|
| 83 |
+
def construct_image_placeholders(grid):
|
| 84 |
+
image_placeholders = [IMAGE_INDICATOR_IDS[0], IMAGE_ATOM_ID, IMAGE_INDICATOR_IDS[1]]
|
| 85 |
+
if grid[0] * grid[1] > 1:
|
| 86 |
+
for r in range(grid[0]):
|
| 87 |
+
for c in range(grid[1]):
|
| 88 |
+
image_placeholders.append(IMAGE_ATOM_ID)
|
| 89 |
+
if c < grid[1] - 1:
|
| 90 |
+
image_placeholders.append(IMAGE_INDICATOR_IDS[2])
|
| 91 |
+
if r < grid[0] - 1:
|
| 92 |
+
image_placeholders.append(IMAGE_INDICATOR_IDS[3])
|
| 93 |
+
image_placeholders.append(IMAGE_INDICATOR_IDS[4])
|
| 94 |
+
return image_placeholders
|
| 95 |
+
|
| 96 |
+
def preprocess_image(self, image: PIL.Image.Image, max_partition=9, covering_threshold=0.9, convert_to_rgb=True):
|
| 97 |
+
def _preprocess(img: PIL.Image.Image, side):
|
| 98 |
+
# first resize and preprocess
|
| 99 |
+
w, h = img.size
|
| 100 |
+
if w == h:
|
| 101 |
+
new_width = new_height = side
|
| 102 |
+
elif w > h:
|
| 103 |
+
new_width = side
|
| 104 |
+
new_height = int(h / w * new_width)
|
| 105 |
+
else:
|
| 106 |
+
new_height = side
|
| 107 |
+
new_width = int(w / h * new_height)
|
| 108 |
+
new_size = dict(height=new_height, width=new_width)
|
| 109 |
+
pixel_values = self.image_processor.preprocess(img, size=new_size, return_tensors='pt')['pixel_values']
|
| 110 |
+
|
| 111 |
+
# then pad to square
|
| 112 |
+
square_values = torch.zeros([1, 3, side, side], dtype=pixel_values.dtype, device=pixel_values.device)
|
| 113 |
+
new_height, new_width = pixel_values.shape[2:]
|
| 114 |
+
if new_height == new_width:
|
| 115 |
+
square_values[:, :, :, :] = pixel_values
|
| 116 |
+
elif new_height > new_width:
|
| 117 |
+
from_index = (side - new_width) // 2
|
| 118 |
+
square_values[:, :, :, from_index:from_index + new_width] = pixel_values
|
| 119 |
+
else:
|
| 120 |
+
from_index = (side - new_height) // 2
|
| 121 |
+
square_values[:, :, from_index:from_index + new_height, :] = pixel_values
|
| 122 |
+
|
| 123 |
+
return square_values
|
| 124 |
+
|
| 125 |
+
def _partition(img, grid):
|
| 126 |
+
w, h = img.size
|
| 127 |
+
row_height = h // grid[0]
|
| 128 |
+
col_width = w // grid[1]
|
| 129 |
+
|
| 130 |
+
partition = []
|
| 131 |
+
for row in range(grid[0]):
|
| 132 |
+
for col in range(grid[1]):
|
| 133 |
+
left = col * col_width
|
| 134 |
+
upper = row * row_height
|
| 135 |
+
right = w if col == grid[1] - 1 else (col + 1) * col_width
|
| 136 |
+
lower = h if row == grid[0] - 1 else (row + 1) * row_height
|
| 137 |
+
partition.append((left, upper, right, lower))
|
| 138 |
+
|
| 139 |
+
return partition
|
| 140 |
+
|
| 141 |
+
def _covering_area(left, upper, right, lower, side):
|
| 142 |
+
w = right - left
|
| 143 |
+
h = lower - upper
|
| 144 |
+
w, h = max(w, h), min(w, h)
|
| 145 |
+
if w > side:
|
| 146 |
+
h = h / w * side
|
| 147 |
+
w = side
|
| 148 |
+
return w * h
|
| 149 |
+
|
| 150 |
+
def _get_best_grid(img, side):
|
| 151 |
+
img_area = img.size[0] * img.size[1]
|
| 152 |
+
|
| 153 |
+
candidate_grids = []
|
| 154 |
+
for i in range(1, max_partition + 1):
|
| 155 |
+
for j in range(1, max_partition + 1):
|
| 156 |
+
if i * j <= max_partition:
|
| 157 |
+
candidate_grids.append((i, j))
|
| 158 |
+
|
| 159 |
+
all_grids = []
|
| 160 |
+
good_grids = []
|
| 161 |
+
for grid in candidate_grids:
|
| 162 |
+
partition = _partition(img, grid)
|
| 163 |
+
covering_ratio = sum([_covering_area(*p, side) for p in partition]) / img_area
|
| 164 |
+
assert covering_ratio <= 1.0
|
| 165 |
+
all_grids.append((grid, covering_ratio))
|
| 166 |
+
if covering_ratio > covering_threshold:
|
| 167 |
+
good_grids.append((grid, covering_ratio))
|
| 168 |
+
|
| 169 |
+
if len(good_grids) > 0:
|
| 170 |
+
# pick the good partition with minimum #sub_images and break the tie using covering_ratio
|
| 171 |
+
return sorted(good_grids, key=lambda x: (x[0][0] * x[0][1], -x[1]))[0][0]
|
| 172 |
+
else:
|
| 173 |
+
# pick the partition with maximum covering_ratio and break the tie using #sub_images
|
| 174 |
+
return sorted(all_grids, key=lambda x: (-x[1], x[0][0] * x[0][1]))[0][0]
|
| 175 |
+
|
| 176 |
+
if convert_to_rgb and image.mode != 'RGB':
|
| 177 |
+
image = image.convert('RGB')
|
| 178 |
+
|
| 179 |
+
sides = self.get_image_size()
|
| 180 |
+
if sides[0] != sides[1]:
|
| 181 |
+
raise ValueError('get_image_size() returns non-square size')
|
| 182 |
+
side = sides[0]
|
| 183 |
+
grid = _get_best_grid(image, side)
|
| 184 |
+
partition = _partition(image, grid)
|
| 185 |
+
crops = [image.crop(p) for p in partition]
|
| 186 |
+
if len(crops) > 1:
|
| 187 |
+
crops.insert(0, image)
|
| 188 |
+
pixel_values = torch.cat([_preprocess(crop, side) for crop in crops], dim=0)
|
| 189 |
+
image_placeholders = self.construct_image_placeholders(grid)
|
| 190 |
+
return pixel_values, image_placeholders
|
| 191 |
+
|
| 192 |
+
def tokenize(self, logits):
|
| 193 |
+
def st_argmax(y_soft, dim): # straight-through softmax
|
| 194 |
+
index = y_soft.max(dim, keepdim=True)[1]
|
| 195 |
+
y_hard = torch.zeros_like(y_soft, memory_format=torch.legacy_contiguous_format).scatter_(dim, index, 1.0)
|
| 196 |
+
ret = y_hard - y_soft.detach() + y_soft
|
| 197 |
+
return ret
|
| 198 |
+
|
| 199 |
+
if self.config.tokenize_function == 'softmax':
|
| 200 |
+
tokens = softmax(logits, dim=-1)
|
| 201 |
+
elif self.config.tokenize_function == 'gumbel_argmax':
|
| 202 |
+
tokens = gumbel_softmax(logits, tau=self.config.tau, hard=True)
|
| 203 |
+
elif self.config.tokenize_function == 'st_argmax':
|
| 204 |
+
tokens = st_argmax(logits, dim=-1)
|
| 205 |
+
else:
|
| 206 |
+
raise ValueError(
|
| 207 |
+
f'Invalid `max_type`, expected softmax or gumbel_argmax or st_argmax, but got {self.config.tokenize_function}')
|
| 208 |
+
return tokens
|
| 209 |
+
|
| 210 |
+
def encode(self, pixel_values):
|
| 211 |
+
output = self.backbone(pixel_values, output_hidden_states=True, return_dict=True)
|
| 212 |
+
features = output.hidden_states[-1]
|
| 213 |
+
if self.config.drop_cls_token:
|
| 214 |
+
features = features[:, 1:, :]
|
| 215 |
+
|
| 216 |
+
# merge number of `hidden_stride * hidden_stride` hidden states together to reduce token sequence length
|
| 217 |
+
# e.g., for hidden_stride=2, this leads to a token length reduction: 1024 -> 256 for aimv2
|
| 218 |
+
if self.config.hidden_stride > 1:
|
| 219 |
+
n, l, d = features.shape # this `d` maybe different from the above `d
|
| 220 |
+
sqrt_l = int(l ** 0.5)
|
| 221 |
+
assert sqrt_l ** 2 == l, "The token sequence length should be a perfect square."
|
| 222 |
+
features = features.reshape(n, sqrt_l, sqrt_l, d)
|
| 223 |
+
pl = (self.config.hidden_stride - (sqrt_l % self.config.hidden_stride)) % self.config.hidden_stride
|
| 224 |
+
features = pad(features, (0, 0, 0, pl, 0, pl), "constant", 0)
|
| 225 |
+
sqrt_l += pl
|
| 226 |
+
features = features.reshape(n, sqrt_l // self.config.hidden_stride, self.config.hidden_stride,
|
| 227 |
+
sqrt_l // self.config.hidden_stride, self.config.hidden_stride, d)
|
| 228 |
+
features = features.permute(0, 1, 3, 2, 4, 5) # [n, sqrt_l/hs, sqrt_l/hs, hs, hs, d]
|
| 229 |
+
features = features.flatten(3) # [n, sqrt_l/hs, sqrt_l/hs, hs*hs*d]
|
| 230 |
+
features = features.reshape(
|
| 231 |
+
n, -1, self.config.hidden_stride * self.config.hidden_stride * d)
|
| 232 |
+
|
| 233 |
+
return features
|
| 234 |
+
|
| 235 |
+
def forward(self, pixel_values) -> torch.Tensor: # [BatchSize, ImageShape] -> [BatchSize, #Token, VocabSize]
|
| 236 |
+
features = self.encode(pixel_values)
|
| 237 |
+
logits = self.head(features)
|
| 238 |
+
tokens = self.tokenize(logits)
|
| 239 |
+
# tokens' shape is [BatchSize, #Token, VocabSize-5], so padding with [BatchSize, #Token, 5], after
|
| 240 |
+
# which, tokens' shape should become [BatchSize, #Token, VocabSize]
|
| 241 |
+
batch_size, token_len, _ = tokens.shape
|
| 242 |
+
padding_tensor = torch.zeros(size=(batch_size, token_len, len(IMAGE_INDICATOR_IDS)),
|
| 243 |
+
dtype=tokens.dtype,
|
| 244 |
+
device=tokens.device,
|
| 245 |
+
layout=tokens.layout,
|
| 246 |
+
requires_grad=False)
|
| 247 |
+
tokens = torch.cat((tokens, padding_tensor), dim=2)
|
| 248 |
+
return tokens
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class Aimv2VisualTokenizer(BaseVisualTokenizer):
|
| 252 |
+
config_class = Aimv2VisualTokenizerConfig
|
| 253 |
+
supports_gradient_checkpointing = True
|
| 254 |
+
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
| 255 |
+
_image_processor_kwargs = dict(do_center_crop=False)
|
| 256 |
+
|
| 257 |
+
def get_image_size(self):
|
| 258 |
+
height = self.image_processor.crop_size["height"]
|
| 259 |
+
width = self.image_processor.crop_size["width"]
|
| 260 |
+
return height, width
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
AutoModel.register(Aimv2VisualTokenizerConfig, Aimv2VisualTokenizer)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
# ----------------------------------------------------------------------
|
| 267 |
+
# Ovis
|
| 268 |
+
# ----------------------------------------------------------------------
|
| 269 |
+
class VisualEmbedding(torch.nn.Embedding):
|
| 270 |
+
def forward(self, visual_tokens: Tensor) -> Tensor:
|
| 271 |
+
if visual_tokens.dtype in [torch.int8, torch.int16, torch.int32, torch.int64, torch.long]:
|
| 272 |
+
return super().forward(visual_tokens)
|
| 273 |
+
return torch.matmul(visual_tokens, self.weight)
|
| 274 |
+
|
| 275 |
+
def reset_parameters(self, mean=0., std=1.) -> None:
|
| 276 |
+
init.normal_(self.weight, mean=mean, std=std)
|
| 277 |
+
self._fill_padding_idx_with_zero()
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class OvisPreTrainedModel(PreTrainedModel):
|
| 281 |
+
config_class = OvisConfig
|
| 282 |
+
base_model_prefix = "ovis"
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
class Ovis(OvisPreTrainedModel):
|
| 286 |
+
|
| 287 |
+
def __init__(self, config: OvisConfig, *inputs, **kwargs):
|
| 288 |
+
super().__init__(config, *inputs, **kwargs)
|
| 289 |
+
attn_kwargs = dict()
|
| 290 |
+
if self.config.llm_attn_implementation:
|
| 291 |
+
if self.config.llm_attn_implementation == "flash_attention_2":
|
| 292 |
+
assert (is_flash_attn_2_available() and
|
| 293 |
+
version.parse(importlib.metadata.version("flash_attn")) >= version.parse("2.6.3")), \
|
| 294 |
+
"Using `flash_attention_2` requires having `flash_attn>=2.6.3` installed."
|
| 295 |
+
attn_kwargs["attn_implementation"] = self.config.llm_attn_implementation
|
| 296 |
+
self.llm = AutoModelForCausalLM.from_config(self.config.llm_config, **attn_kwargs)
|
| 297 |
+
assert self.config.hidden_size == self.llm.config.hidden_size, "hidden size mismatch"
|
| 298 |
+
self.text_tokenizer = AutoTokenizer.from_pretrained(self.config.name_or_path)
|
| 299 |
+
self.visual_tokenizer = AutoModel.from_config(self.config.visual_tokenizer_config,
|
| 300 |
+
image_processor_name_or_path=self.config.name_or_path)
|
| 301 |
+
self.vte = VisualEmbedding(
|
| 302 |
+
self.config.visual_tokenizer_config.vocab_size,
|
| 303 |
+
self.config.hidden_size,
|
| 304 |
+
device=self.visual_tokenizer.device,
|
| 305 |
+
dtype=self.visual_tokenizer.dtype
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
def _merge_modules(modules_list: tuple):
|
| 309 |
+
merged_modules = []
|
| 310 |
+
for modules in modules_list:
|
| 311 |
+
merged_modules.extend(modules if modules else [])
|
| 312 |
+
return merged_modules
|
| 313 |
+
|
| 314 |
+
self._no_split_modules = _merge_modules((self.llm._no_split_modules, self.visual_tokenizer._no_split_modules))
|
| 315 |
+
self._skip_keys_device_placement = self.llm._skip_keys_device_placement
|
| 316 |
+
self._keep_in_fp32_modules = _merge_modules(
|
| 317 |
+
(self.llm._keep_in_fp32_modules, self.visual_tokenizer._keep_in_fp32_modules))
|
| 318 |
+
self.is_parallelizable = all((self.llm.is_parallelizable, self.visual_tokenizer.is_parallelizable))
|
| 319 |
+
self.supports_gradient_checkpointing = True
|
| 320 |
+
self._supports_flash_attn_2 = True
|
| 321 |
+
|
| 322 |
+
def get_text_tokenizer(self):
|
| 323 |
+
return self.text_tokenizer
|
| 324 |
+
|
| 325 |
+
def get_visual_tokenizer(self):
|
| 326 |
+
return self.visual_tokenizer
|
| 327 |
+
|
| 328 |
+
def tie_weights(self):
|
| 329 |
+
if not self.config.disable_tie_weight:
|
| 330 |
+
self.get_llm().tie_weights()
|
| 331 |
+
|
| 332 |
+
def get_llm(self):
|
| 333 |
+
return self.llm
|
| 334 |
+
|
| 335 |
+
def get_vte(self):
|
| 336 |
+
return self.vte
|
| 337 |
+
|
| 338 |
+
def get_wte(self):
|
| 339 |
+
return self.llm.get_input_embeddings()
|
| 340 |
+
|
| 341 |
+
def get_conversation_formatter(self) -> ConversationFormatter:
|
| 342 |
+
if getattr(self, 'conversation_formatter', None) is None:
|
| 343 |
+
self.conversation_formatter = getattr(import_module(".configuration_ovis", __package__),
|
| 344 |
+
self.config.conversation_formatter_class)(self.text_tokenizer)
|
| 345 |
+
return self.conversation_formatter
|
| 346 |
+
|
| 347 |
+
def forward(
|
| 348 |
+
self,
|
| 349 |
+
input_ids: torch.Tensor,
|
| 350 |
+
attention_mask: torch.Tensor,
|
| 351 |
+
labels: Optional[torch.Tensor],
|
| 352 |
+
pixel_values: List[Optional[torch.Tensor]],
|
| 353 |
+
**kwargs
|
| 354 |
+
):
|
| 355 |
+
# assert self.training, "`forward` can only be used in training. For inference, use `generate`."
|
| 356 |
+
_, inputs_embeds, labels, attention_mask = self.merge_multimodal(
|
| 357 |
+
text_input_ids=input_ids,
|
| 358 |
+
text_attention_masks=attention_mask,
|
| 359 |
+
text_labels=labels,
|
| 360 |
+
pixel_values=pixel_values
|
| 361 |
+
)
|
| 362 |
+
return self.llm(inputs_embeds=inputs_embeds, labels=labels, attention_mask=attention_mask, **kwargs)
|
| 363 |
+
|
| 364 |
+
def merge_multimodal(
|
| 365 |
+
self,
|
| 366 |
+
text_input_ids: torch.Tensor,
|
| 367 |
+
text_attention_masks: torch.Tensor,
|
| 368 |
+
text_labels: Optional[torch.Tensor],
|
| 369 |
+
pixel_values: List[Optional[torch.Tensor]],
|
| 370 |
+
left_padding: bool = False
|
| 371 |
+
):
|
| 372 |
+
input_device = text_input_ids.device
|
| 373 |
+
visual_vocab_szie = self.get_visual_tokenizer().config.vocab_size
|
| 374 |
+
visual_indicator_embeds = self.get_vte()(
|
| 375 |
+
torch.tensor(
|
| 376 |
+
list(range(visual_vocab_szie - 5, visual_vocab_szie)),
|
| 377 |
+
dtype=torch.long,
|
| 378 |
+
device=self.get_visual_tokenizer().device
|
| 379 |
+
)
|
| 380 |
+
).to(device=input_device)
|
| 381 |
+
|
| 382 |
+
if self.training:
|
| 383 |
+
# When training, to be compatible with deepspeed zero, each sample has to include pixel_value tensor.
|
| 384 |
+
# For text-only sample, one can simply use a full zero tensor as pixel_value, which will be ignored
|
| 385 |
+
# (see below in this function); so, the gradient will not be affected.
|
| 386 |
+
num_images = [x.shape[0] for x in pixel_values]
|
| 387 |
+
visual_tokens = self.visual_tokenizer(torch.cat([x for x in pixel_values], dim=0))
|
| 388 |
+
visual_embeds = torch.split(self.get_vte()(visual_tokens).to(dtype=self.dtype, device=input_device),
|
| 389 |
+
split_size_or_sections=num_images, dim=0)
|
| 390 |
+
visual_input_ids = torch.split(torch.argmax(visual_tokens, dim=-1).to(device=input_device),
|
| 391 |
+
split_size_or_sections=num_images, dim=0)
|
| 392 |
+
visual_labels = [torch.full(x.shape, IGNORE_ID, dtype=torch.long, device=input_device) for x in
|
| 393 |
+
visual_input_ids]
|
| 394 |
+
else:
|
| 395 |
+
# When inference, sample can include only text with `None` pixel_value
|
| 396 |
+
num_images = [x.shape[0] if x is not None else 0 for x in pixel_values]
|
| 397 |
+
if sum(num_images) > 0:
|
| 398 |
+
visual_tokens = self.visual_tokenizer(torch.cat([x for x in pixel_values if x is not None], dim=0))
|
| 399 |
+
visual_embeds = torch.split(self.get_vte()(visual_tokens).to(dtype=self.dtype, device=input_device),
|
| 400 |
+
split_size_or_sections=num_images, dim=0)
|
| 401 |
+
visual_input_ids = torch.split(torch.argmax(visual_tokens, dim=-1).to(device=input_device),
|
| 402 |
+
split_size_or_sections=num_images, dim=0)
|
| 403 |
+
visual_labels = [torch.full(x.shape, IGNORE_ID, dtype=torch.long, device=input_device) for x in
|
| 404 |
+
visual_input_ids]
|
| 405 |
+
else:
|
| 406 |
+
# just placeholders
|
| 407 |
+
visual_embeds = [None] * len(num_images)
|
| 408 |
+
visual_input_ids = [None] * len(num_images)
|
| 409 |
+
visual_labels = [None] * len(num_images)
|
| 410 |
+
# just placeholders
|
| 411 |
+
if text_labels is None:
|
| 412 |
+
text_labels = torch.full(text_input_ids.shape, IGNORE_ID, dtype=torch.long, device=input_device)
|
| 413 |
+
|
| 414 |
+
input_embeds = []
|
| 415 |
+
attention_masks = []
|
| 416 |
+
labels = []
|
| 417 |
+
for text_input_id, text_label, text_attention_mask, visual_embed, visual_input_id, visual_label in zip(
|
| 418 |
+
text_input_ids, text_labels, text_attention_masks, visual_embeds, visual_input_ids, visual_labels
|
| 419 |
+
):
|
| 420 |
+
placeholder_token_mask = torch.lt(text_input_id, 0)
|
| 421 |
+
text_embed = self.get_wte()(torch.masked_fill(text_input_id, placeholder_token_mask, 0))
|
| 422 |
+
for i, indicator_id in enumerate(IMAGE_INDICATOR_IDS):
|
| 423 |
+
text_embed[text_input_id == indicator_id] = visual_indicator_embeds[i]
|
| 424 |
+
image_atom_positions = torch.where(torch.eq(text_input_id, IMAGE_ATOM_ID))[0].tolist()
|
| 425 |
+
if len(image_atom_positions) > 0:
|
| 426 |
+
input_embed_parts = []
|
| 427 |
+
attention_mask_parts = []
|
| 428 |
+
label_parts = []
|
| 429 |
+
prev_image_atom_position = -1
|
| 430 |
+
for index, image_atom_position in enumerate(image_atom_positions):
|
| 431 |
+
input_embed_parts.append(
|
| 432 |
+
text_embed[prev_image_atom_position + 1:image_atom_position, :])
|
| 433 |
+
label_parts.append(
|
| 434 |
+
text_label[prev_image_atom_position + 1:image_atom_position])
|
| 435 |
+
attention_mask_parts.append(
|
| 436 |
+
text_attention_mask[prev_image_atom_position + 1:image_atom_position])
|
| 437 |
+
input_embed_parts.append(visual_embed[index])
|
| 438 |
+
attention_mask_parts.append(
|
| 439 |
+
torch.ones_like(visual_label[index], dtype=torch.bool))
|
| 440 |
+
label_parts.append(visual_label[index])
|
| 441 |
+
prev_image_atom_position = image_atom_position
|
| 442 |
+
if prev_image_atom_position + 1 < text_input_id.shape[0]:
|
| 443 |
+
input_embed_parts.append(
|
| 444 |
+
text_embed[prev_image_atom_position + 1:, :])
|
| 445 |
+
attention_mask_parts.append(
|
| 446 |
+
text_attention_mask[prev_image_atom_position + 1:])
|
| 447 |
+
label_parts.append(
|
| 448 |
+
text_label[prev_image_atom_position + 1:])
|
| 449 |
+
input_embed = torch.cat(input_embed_parts, dim=0)
|
| 450 |
+
attention_mask = torch.cat(attention_mask_parts, dim=0)
|
| 451 |
+
label = torch.cat(label_parts, dim=0)
|
| 452 |
+
else:
|
| 453 |
+
input_embed = text_embed
|
| 454 |
+
attention_mask = text_attention_mask
|
| 455 |
+
label = text_label
|
| 456 |
+
if self.training:
|
| 457 |
+
# Make visual_embed & visual_indicator_embeds involved in the backward graph,
|
| 458 |
+
# to be compatible with deepspeed zero and ddp.
|
| 459 |
+
input_embed += torch.sum(visual_embed * 0.0) + torch.sum(visual_indicator_embeds * 0.0)
|
| 460 |
+
input_embeds.append(input_embed)
|
| 461 |
+
attention_masks.append(attention_mask)
|
| 462 |
+
labels.append(label)
|
| 463 |
+
|
| 464 |
+
if self.training: # padding to self.config.multimodal_max_length for increased training speed
|
| 465 |
+
padding_size = max(0, self.config.multimodal_max_length - len(input_embeds[0]))
|
| 466 |
+
input_embeds[0] = torch.nn.ConstantPad2d((0, 0, 0, padding_size), 0.0)(input_embeds[0])
|
| 467 |
+
attention_masks[0] = torch.nn.ConstantPad1d((0, padding_size), False)(attention_masks[0])
|
| 468 |
+
labels[0] = torch.nn.ConstantPad1d((0, padding_size), IGNORE_ID)(labels[0])
|
| 469 |
+
batch_input_embeds = self.pad_truncate_sequence(input_embeds, batch_first=True, padding_value=0.0, left_padding=left_padding)
|
| 470 |
+
batch_attention_mask = self.pad_truncate_sequence(attention_masks, batch_first=True, padding_value=False, left_padding=left_padding)
|
| 471 |
+
batch_labels = self.pad_truncate_sequence(labels, batch_first=True, padding_value=IGNORE_ID, left_padding=left_padding)
|
| 472 |
+
|
| 473 |
+
return visual_input_ids, batch_input_embeds, batch_labels, batch_attention_mask
|
| 474 |
+
|
| 475 |
+
def pad_truncate_sequence(self, sequences: List[torch.Tensor], batch_first: bool = True, padding_value: float = 0.0, left_padding: bool = False) -> torch.Tensor:
|
| 476 |
+
if not left_padding:
|
| 477 |
+
pad_sequence = torch.nn.utils.rnn.pad_sequence(sequences, batch_first=batch_first, padding_value=padding_value)
|
| 478 |
+
return pad_sequence[:,:self.config.multimodal_max_length]
|
| 479 |
+
else:
|
| 480 |
+
pad_sequence = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in sequences],batch_first=True, padding_value=padding_value).flip(dims=[1])
|
| 481 |
+
return pad_sequence[:,-self.config.multimodal_max_length:]
|
| 482 |
+
|
| 483 |
+
def preprocess_inputs(
|
| 484 |
+
self,
|
| 485 |
+
text_or_conversations: Union[List[Dict], str],
|
| 486 |
+
images: Optional[List[PIL.Image.Image]],
|
| 487 |
+
max_partition=9,
|
| 488 |
+
generation_preface='',
|
| 489 |
+
return_labels=False,
|
| 490 |
+
propagate_exception=True,
|
| 491 |
+
frame_selector=None,
|
| 492 |
+
frame_selector_kwargs=None
|
| 493 |
+
):
|
| 494 |
+
# convert text to conversations
|
| 495 |
+
if isinstance(text_or_conversations, str):
|
| 496 |
+
conversations = [{
|
| 497 |
+
"from": "human",
|
| 498 |
+
"value": text_or_conversations
|
| 499 |
+
}]
|
| 500 |
+
elif isinstance(text_or_conversations, list):
|
| 501 |
+
conversations = text_or_conversations
|
| 502 |
+
else:
|
| 503 |
+
raise ValueError(f'Invalid type of `text_or_conversations`, expected `List[Dict]` or `str`,'
|
| 504 |
+
f' but got {type(text_or_conversations)}')
|
| 505 |
+
|
| 506 |
+
if frame_selector is not None:
|
| 507 |
+
frame_selector_kwargs = frame_selector_kwargs or {}
|
| 508 |
+
conversations, images = frame_selector(conversations=conversations, frames=images, **frame_selector_kwargs)
|
| 509 |
+
|
| 510 |
+
# format conversations
|
| 511 |
+
prompt, raw_input_ids, raw_labels = self.get_conversation_formatter().format(
|
| 512 |
+
conversations, generation_preface=generation_preface)
|
| 513 |
+
|
| 514 |
+
# place image placeholders
|
| 515 |
+
input_ids = []
|
| 516 |
+
labels = []
|
| 517 |
+
pixel_values = []
|
| 518 |
+
invalidate_label = False
|
| 519 |
+
image_token_indices = [i for i, v in enumerate(raw_input_ids) if v == IMAGE_TOKEN_ID]
|
| 520 |
+
last_image_token_index = -1
|
| 521 |
+
for i in range(len(image_token_indices)):
|
| 522 |
+
head = 0 if i == 0 else image_token_indices[i - 1] + 1
|
| 523 |
+
tail = image_token_indices[i]
|
| 524 |
+
last_image_token_index = tail
|
| 525 |
+
input_ids.extend(raw_input_ids[head:tail])
|
| 526 |
+
labels.extend(raw_labels[head:tail])
|
| 527 |
+
try:
|
| 528 |
+
image = images[i]
|
| 529 |
+
raw_pixel_values, image_placeholders = self.visual_tokenizer.preprocess_image(
|
| 530 |
+
image, max_partition=max_partition)
|
| 531 |
+
except Exception as e:
|
| 532 |
+
if propagate_exception:
|
| 533 |
+
raise e
|
| 534 |
+
logging.exception(e)
|
| 535 |
+
invalidate_label = True
|
| 536 |
+
raw_pixel_values, image_placeholders = self.visual_tokenizer.mock_input()
|
| 537 |
+
input_ids.extend(image_placeholders)
|
| 538 |
+
labels.extend([IGNORE_ID] * len(image_placeholders))
|
| 539 |
+
pixel_values.append(raw_pixel_values)
|
| 540 |
+
input_ids.extend(raw_input_ids[last_image_token_index + 1:])
|
| 541 |
+
labels.extend(raw_labels[last_image_token_index + 1:])
|
| 542 |
+
|
| 543 |
+
# return tensors
|
| 544 |
+
input_ids = torch.tensor(input_ids, dtype=torch.long)
|
| 545 |
+
labels = torch.tensor([IGNORE_ID] * len(labels) if invalidate_label else labels, dtype=torch.long)
|
| 546 |
+
pixel_values = torch.cat(pixel_values, dim=0) if len(pixel_values) > 0 else None
|
| 547 |
+
|
| 548 |
+
if return_labels:
|
| 549 |
+
return prompt, input_ids, pixel_values, labels
|
| 550 |
+
else:
|
| 551 |
+
return prompt, input_ids, pixel_values
|
| 552 |
+
|
| 553 |
+
def save_pretrained(
|
| 554 |
+
self,
|
| 555 |
+
save_directory: Union[str, os.PathLike],
|
| 556 |
+
is_main_process: bool = True,
|
| 557 |
+
state_dict: Optional[dict] = None,
|
| 558 |
+
save_function: Callable = torch.save,
|
| 559 |
+
push_to_hub: bool = False,
|
| 560 |
+
max_shard_size: Union[int, str] = "5GB",
|
| 561 |
+
safe_serialization: bool = True,
|
| 562 |
+
variant: Optional[str] = None,
|
| 563 |
+
token: Optional[Union[str, bool]] = None,
|
| 564 |
+
save_peft_format: bool = True,
|
| 565 |
+
**kwargs
|
| 566 |
+
):
|
| 567 |
+
super().save_pretrained(save_directory,
|
| 568 |
+
is_main_process=is_main_process,
|
| 569 |
+
state_dict=state_dict,
|
| 570 |
+
save_function=save_function,
|
| 571 |
+
safe_serialization=safe_serialization)
|
| 572 |
+
self.get_text_tokenizer().save_pretrained(save_directory)
|
| 573 |
+
self.get_visual_tokenizer().get_image_processor().save_pretrained(save_directory)
|
| 574 |
+
|
| 575 |
+
def generate(
|
| 576 |
+
self,
|
| 577 |
+
inputs: Optional[torch.Tensor] = None,
|
| 578 |
+
**kwargs
|
| 579 |
+
) -> Union[GenerateOutput, torch.LongTensor]:
|
| 580 |
+
_, inputs_embeds, labels, attention_mask = self.merge_multimodal(
|
| 581 |
+
text_input_ids=inputs,
|
| 582 |
+
text_attention_masks=kwargs.pop('attention_mask'),
|
| 583 |
+
text_labels=None,
|
| 584 |
+
pixel_values=kwargs.pop('pixel_values'),
|
| 585 |
+
left_padding=True
|
| 586 |
+
)
|
| 587 |
+
inputs_embeds = inputs_embeds.detach()
|
| 588 |
+
torch.cuda.empty_cache()
|
| 589 |
+
|
| 590 |
+
return self.llm.generate(inputs=None, inputs_embeds=inputs_embeds, attention_mask=attention_mask, **kwargs)
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": {
|
| 3 |
+
"height": 448,
|
| 4 |
+
"width": 448
|
| 5 |
+
},
|
| 6 |
+
"do_center_crop": false,
|
| 7 |
+
"do_convert_rgb": true,
|
| 8 |
+
"do_normalize": true,
|
| 9 |
+
"do_rescale": true,
|
| 10 |
+
"do_resize": true,
|
| 11 |
+
"image_mean": [
|
| 12 |
+
0.48145466,
|
| 13 |
+
0.4578275,
|
| 14 |
+
0.40821073
|
| 15 |
+
],
|
| 16 |
+
"image_processor_type": "CLIPImageProcessor",
|
| 17 |
+
"image_std": [
|
| 18 |
+
0.26862954,
|
| 19 |
+
0.26130258,
|
| 20 |
+
0.27577711
|
| 21 |
+
],
|
| 22 |
+
"resample": 3,
|
| 23 |
+
"rescale_factor": 0.00392156862745098,
|
| 24 |
+
"size": {
|
| 25 |
+
"shortest_edge": 448
|
| 26 |
+
}
|
| 27 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c5ae00e602b8860cbd784ba82a8aa14e8feecec692e7076590d014d7b7fdafa
|
| 3 |
+
size 11421896
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 199 |
+
"clean_up_tokenization_spaces": false,
|
| 200 |
+
"eos_token": "<|im_end|>",
|
| 201 |
+
"errors": "replace",
|
| 202 |
+
"extra_special_tokens": {},
|
| 203 |
+
"model_max_length": 131072,
|
| 204 |
+
"pad_token": "<|endoftext|>",
|
| 205 |
+
"split_special_tokens": false,
|
| 206 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 207 |
+
"unk_token": null
|
| 208 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_global_step": 35,
|
| 3 |
+
"best_metric": 0.05715959,
|
| 4 |
+
"best_model_checkpoint": "/kaggle/working/outputs/ovis_2/v1-20250825-163329/checkpoint-35",
|
| 5 |
+
"epoch": 4.390243902439025,
|
| 6 |
+
"eval_steps": 20,
|
| 7 |
+
"global_step": 35,
|
| 8 |
+
"is_hyper_param_search": false,
|
| 9 |
+
"is_local_process_zero": true,
|
| 10 |
+
"is_world_process_zero": true,
|
| 11 |
+
"log_history": [
|
| 12 |
+
{
|
| 13 |
+
"epoch": 0.13008130081300814,
|
| 14 |
+
"grad_norm": 11.133254873275208,
|
| 15 |
+
"learning_rate": 1e-05,
|
| 16 |
+
"loss": 0.5857368111610413,
|
| 17 |
+
"step": 1
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"epoch": 2.5203252032520327,
|
| 21 |
+
"grad_norm": 1.3225270792658155,
|
| 22 |
+
"learning_rate": 4.081252410917148e-06,
|
| 23 |
+
"loss": 0.22521548522146126,
|
| 24 |
+
"step": 20
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"epoch": 2.5203252032520327,
|
| 28 |
+
"eval_loss": 0.06231056898832321,
|
| 29 |
+
"eval_runtime": 24.679,
|
| 30 |
+
"eval_samples_per_second": 4.943,
|
| 31 |
+
"eval_steps_per_second": 1.256,
|
| 32 |
+
"step": 20
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"epoch": 4.390243902439025,
|
| 36 |
+
"eval_loss": 0.05715958774089813,
|
| 37 |
+
"eval_runtime": 24.763,
|
| 38 |
+
"eval_samples_per_second": 4.927,
|
| 39 |
+
"eval_steps_per_second": 1.252,
|
| 40 |
+
"step": 35
|
| 41 |
+
}
|
| 42 |
+
],
|
| 43 |
+
"logging_steps": 20,
|
| 44 |
+
"max_steps": 35,
|
| 45 |
+
"num_input_tokens_seen": 0,
|
| 46 |
+
"num_train_epochs": 5,
|
| 47 |
+
"save_steps": 20,
|
| 48 |
+
"stateful_callbacks": {
|
| 49 |
+
"TrainerControl": {
|
| 50 |
+
"args": {
|
| 51 |
+
"should_epoch_stop": false,
|
| 52 |
+
"should_evaluate": false,
|
| 53 |
+
"should_log": false,
|
| 54 |
+
"should_save": true,
|
| 55 |
+
"should_training_stop": true
|
| 56 |
+
},
|
| 57 |
+
"attributes": {}
|
| 58 |
+
}
|
| 59 |
+
},
|
| 60 |
+
"total_flos": 12582790037504.0,
|
| 61 |
+
"train_batch_size": 1,
|
| 62 |
+
"trial_name": null,
|
| 63 |
+
"trial_params": null
|
| 64 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ff6839e6a0249f5438a88d7efb9a820c1a33c57665643df143d4d73f0e1613f3
|
| 3 |
+
size 8913
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|